












面试官:好了,你也休息了十分钟了,咱们接着往下聊聊SynchronousQueue的非公平模式吧。
Hydra:好的,有了前面公平模式的基础,非公平模式理解起来就非常简单了。公平模式下,SynchronousQueue底层使用的是TransferQueue,是一个先进先出的队列,而非公平模式与它不同,底层采用了后进先出的TransferStack栈来实现。
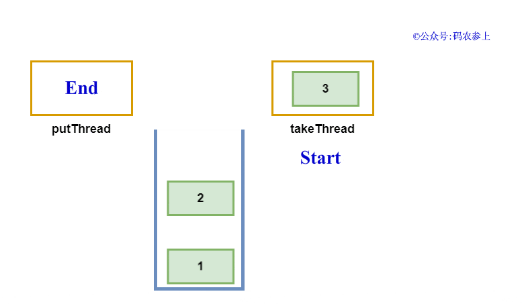
下面我们还是先写一个例子来看看效果,首先创建3个线程使用put方法向SynchronousQueue中插入数据,结束后再使用3个线程调用take方法:
- SynchronousQueue<Integer> queue=new SynchronousQueue<>(false);
- @AllArgsConstructor
- class PutThread implements Runnable{
- int i;
- @SneakyThrows
- @Override
- public void run() {
- queue.put(i);
- System.out.println("putThread "+i+" end");
- }
- }
- class TakeThread implements Runnable{
- @SneakyThrows
- @Override
- public void run() {
- System.out.println("takeThread take: "+queue.take());
- }
- }
- for (int i = 1; i <=3; i++) {
- new Thread(new PutThread(i)).start();
- Thread.sleep(1000);
- }
- for (int i = 1; i <=3 ; i++) {
- new Thread(new TakeThread()).start();
- Thread.sleep(1000);
- }
运行上面的代码,查看结果:
- takeThread take: 3
- putThread 3 end
- takeThread take: 2
- putThread 2 end
- takeThread take: 1
- putThread 1 end
可以看到,生产者线程在执行完put后会进行阻塞,直到有消费者线程调用take方法取走了数据,才会唤醒被阻塞的线程。并且,数据的出队与入队顺序是相反的,即非公平模式下采用的是后进先出的顺序。
面试官:就是把结构从队列换成了栈,真就这么简单?
Hydra:并不是,包括底层节点以及出入栈的逻辑都做了相应的改变。我们先看节点,在之前的公平模式中队列的节点是QNode,非公平模式下栈中节点是SNode,定义如下:
- volatile SNode next; // 指向下一个节点的指针
- volatile SNode match; // 存放和它进行匹配的节点
- volatile Thread waiter; // 保存阻塞的线程
- Object item;
- int mode;
- SNode(Object item) {
- this.item = item;
- }
和QNode类似,如果是生产者构建的节点,那么item非空,如果是消费者产生的节点,那么item为null。此外还有一个mode属性用来表示节点的状态,它使用TransferStack中定义的3个常量来表示不同状态:
- static final int REQUEST = 0; //消费者
- static final int DATA = 1; //生产者
- static final int FULFILLING = 2; //匹配中状态
TransferStack中没有携带参数的构造函数,使用一个head节点来标记栈顶节点:
- volatile SNode head;
面试官:基本结构就讲到这吧,还是老规矩,先从入队操作开始分析吧。
Hydra:当栈为空、或栈顶元素的类型与自己相同时,会先创建一个SNode节点,并将它的next节点指向当前栈顶的head,然后将head指针指向自己。这个过程中通过使用CAS保证线程安全,如果失败则退出,在循环中采取自旋的方式不断进行尝试,直到节点入栈成功。用一张图来表示两个线程同时入栈的场景:
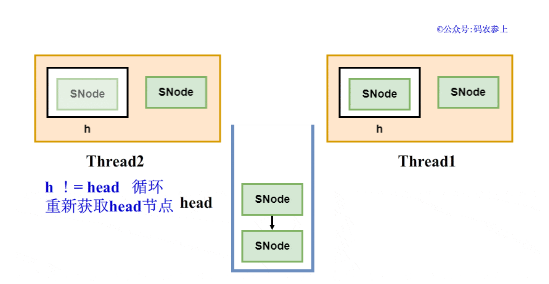
当节点完成入栈后,调用awaitFulfill方法,等待匹配的操作的到来。在这一过程中,会使节点对应的线程进行自旋或挂起操作,直到匹配操作的节点将自己唤醒,或被其他线程中断、等待超时。
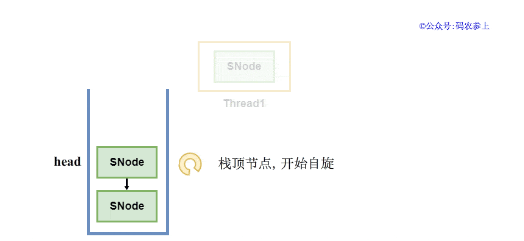
当入栈后的节点是栈顶节点,或者节点的类型为FULFILLING匹配状态时,那么可能会马上完成匹配,因此先进行自旋,当超过自旋次数上限后再挂起。而如果节点在自旋过程中,有新的节点压入栈顶,会将非栈顶节点剩余的自旋次数直接清零,挂起线程避免浪费资源。
面试官:你上面也说了,挂起的线程有可能会超时或者被中断,这时候应该怎么处理?
Hydra:当这两种情况出现时,SNode会将match属性设为自身,退出awaitFulfill方法,然后调用clean方法将对应的节点清理出栈。具体情形可分为两种情况。先说简单的情况,如果清理的是栈顶节点,那么直接将head节点指向它的next节点,即将当前栈顶节点弹出即可。
面试官:那么如果要删除的节点不是栈顶的节点呢?
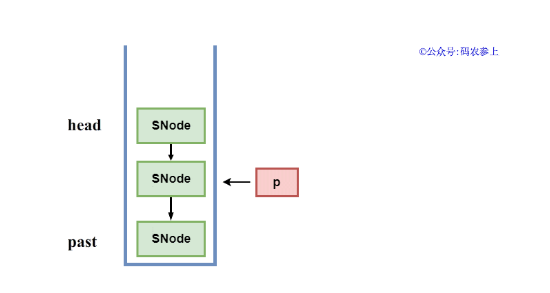
Hydra:如果清理的不是栈顶节点,会稍微有一些麻烦。因为栈的底层是一个单向的链表结构,所以需要从栈顶head节点开始遍历,遍历到被删除节点的后继节点为止。所以在清除工作开始前,先使用了一个past节点标记需要删除节点的下一个节点,作为结束遍历的标记。
然后创建一个标记节点p,初始时指向head节点,开始循环,如果p的next节点不是需要被删除的节点,那么就将p向后移一个位置,直到找到这个需要被删除的中断或超时的节点,然后将p的next指向这个删除节点的next节点,在逻辑上完成链表中节点的删除。
面试官:单一类型节点的入栈应该说完了吧,接下来说说不同类型节点间是如何实现的匹配操作吧?
Hydra:好的,那我们先回顾一点上面的知识,前面说过每个节点有一个mode属性代表它的模式,REQUEST表示它是消费者,DATA表示是生产者,FULFILLING表明正处于匹配中的状态。
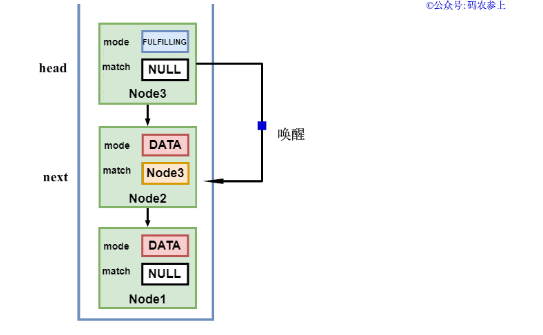
在一个新的线程调用方法时,先判断它的类型mode是什么,如果和当前栈顶head节点类型不同,且head节点的状态不为匹配中时,将它的状态设置为FULFILLING|mode,压入栈中。然后将尝试匹配新的head节点和它的next节点,如果匹配成功,会将next节点的match属性设置为head节点,唤醒挂起的next节点中的线程。
在完成匹配后,当前头节点对应的线程会协助推进head节点,将head指向next节点的下一个节点,即完成了栈顶两节点的出栈。最终消费者线程会返回匹配的生产者节点中的item数据值,而生产者线程也会结束运行退出。
我们以栈中当前节点为DATA类型,新节点为REQUEST类型画一张图,来直观的感受一下上面的流程:
面试官:总算是讲完了,能对SynchronousQueue做一个简单的总结吗?
Hydra:SynchronousQueue基于底层结构,实现了线程配对通信这一机制。在它的公平模式下使用的是先进先出(FIFO)的队列,非公平模式下使用的是后进先出(LIFO)的栈,并且SynchronousQueue没有使用synchronized或ReentrantLock,而是使用了大量的CAS操作来保证并发操作。可能我们在平常的工作中使用场景不是很多,但是在线程池的设计中使用了SynchronousQueue,还是有很重要的应用场景的。
面试官:讲的还行,不过刚才这些和公平模式听起来感觉区别不大啊,没有什么技术含量。这样吧,你明天过来我们加试一场,我再给你打分。
Hydra:(溜了溜了,还是找家别的靠谱公司吧……)

















