传统的讲座通常伴随着一组 pdf 幻灯片。一般来说,想要对此类讲座做笔记,需要从 pdf 复制、粘贴很多内容。
最近,来自 K1 Digital 的高级机器学习工程师 Lucas Soares 一直在尝试通过使用 OCR(光学字符识别)自动转录 pdf 幻灯片,以便直接在 markdown 文件中操作它们的内容,从而避免手动复制和粘贴 pdf 内容,实现这一过程的自动化。
左为项目作者 Lucas Soares。
项目地址:https://github.com/EnkrateiaLucca/ocr_for_transcribing_pdf_slides
为什么不使用传统的 pdf 转文本工具呢?
Lucas Soares 发现传统工具往往会带来更多的问题,需要花时间解决。他曾经尝试使用传统的 Python 软件包,但是遇到了很多问题(例如必须使用复杂的正则表达式模式解析最终输出等),因此决定尝试使用目标检测和 OCR 来解决。
基本过程可分为以下步骤:
- 将 pdf 转换为图片;
- 检测和识别图像中的文本;
- 展示示例输出。
基于深度学习的 OCR 将 pdf 转录为文本
将 pdf 转换为图像
Soares 使用的 pdf 幻灯片来自于 David Silver 的增强学习(参见以下 pdf 幻灯片地址)。使用「pdf2image」包将每张幻灯片转换为 png 图像格式。

pdf 幻灯片示例。
地址:https://www.davidsilver.uk/wp-content/uploads/2020/03/intro_RL.pdf
代码如下:
- from pdf2image import convert_from_path
- from pdf2image.exceptions import (
- PDFInfoNotInstalledError,
- PDFPageCountError,
- PDFSyntaxError
- )
- pdf_path = "path/to/file/intro_RL_Lecture1.pdf"
- images = convert_from_path(pdf_path)
- for i, image in enumerate(images):
- fname = "image" + str(i) + ".png"
- image.save(fname, "PNG")
经过处理后,所有的 pdf 幻灯片都转换成 png 格式的图像:

检测和识别图像中的文本
为了检测和识别 png 图像中的文本,Soares 使用 ocr.pytorch 库中的文本检测器。按照说明下载模型并将模型保存在 checkpoints 文件夹中。
ocr.pytorch 库地址:https://github.com/courao/ocr.pytorch
代码如下:
- # adapted from this source: https://github.com/courao/ocr.pytorch
- %load_ext autoreload
- %autoreload 2
- import os
- from ocr import ocr
- import time
- import shutil
- import numpy as np
- import pathlib
- from PIL import Image
- from glob import glob
- import matplotlib.pyplot as plt
- import seaborn as sns
- sns.set()
- import pytesseract
- def single_pic_proc(image_file):
- image = np.array(Image.open(image_file).convert('RGB'))
- result, image_framed = ocr(image)
- return result,image_framed
- image_files = glob('./input_images/*.*')
- result_dir = './output_images_with_boxes/'
- # If the output folder exists we will remove it and redo it.
- if os.path.exists(result_dir):
- shutil.rmtree(result_dir)
- os.mkdir(result_dir)
- for image_file in sorted(image_files):
- result, image_framed = single_pic_proc(image_file) # detecting and recognizing the text
- filename = pathlib.Path(image_file).name
- output_file = os.path.join(result_dir, image_file.split('/')[-1])
- txt_file = os.path.join(result_dir, image_file.split('/')[-1].split('.')[0]+'.txt')
- txt_f = open(txt_file, 'w')
- Image.fromarray(image_framed).save(output_file)
- for key in result:
- txt_f.write(result[key][1]+'\n')
- txt_f.close()
设置输入和输出文件夹,接着遍历所有输入图像(转换后的 pdf 幻灯片),然后通过 single_pic_proc() 函数运行 OCR 模块中的检测和识别模型,最后将输出保存到输出文件夹。
其中检测继承(inherit)了 Pytorch CTPN 模型,识别继承了 Pytorch CRNN 模型,两者都存在于 OCR 模块中。
示例输出
代码如下:
- import cv2 as cv
- output_dir = pathlib.Path("./output_images_with_boxes")
- # image = cv.imread(str(np.random.choice(list(output_dir.iterdir()),1)[0]))
- image = cv.imread(f"{output_dir}/image7.png")
- size_reshaped = (int(image.shape[1]),int(image.shape[0]))
- image = cv.resize(image, size_reshaped)
- cv.imshow("image", image)
- cv.waitKey(0)
- cv.destroyAllWindows()
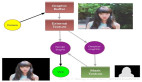
下图左为原始 pdf 幻灯片,图右为转录后的输出文本,转录后的准确率非常高。

文本识别输出如下:
- filename = f"{output_dir}/image7.txt"
- with open(filename, "r") as text:
- for line in text.readlines():
- print(line.strip("\n"))
通过上述方法,最终你可以得到一个非常强大的工具来转录各种文档,从检测和识别手写笔记到检测和识别照片中的随机文本。拥有自己的 OCR 工具来处理一些文本内容,这比依赖外部软件来转录文档要好的多。