













本文转载自微信公众号「程序员jinjunzhu」,作者jinjunzhu。转载本文请联系程序员jinjunzhu公众号。
蚂蚁集团自研数据库OceanBase已经开源,这对国产分布式数据库来说,是一个重磅消息。一直以来OceanBase作为商业数据库,披露的技术细节并不多,以后又多了一个可以拿来研究的优秀分布式数据库。参考1[1]
根据官网描述,在5月20日国际事务处理性能委员会(TPC,Transaction Processing Performance Council)官网发布最新的数据分析型基准测试(TPC-H)榜单中,OceanBase以 1526 万 QphH 的性能总分排名 30,000 GB 第一。这意味着,OceanBase 成为唯一在事务处理和数据分析两个领域测试中都获得第一的中国自研数据库。
1 架构
主流的分布式数据库有两种架构,PGXC和NewSql。
1.1 PGXC
PGXC是指PostgreSQL-XC,指以PostgreSQL为内核的分布式数据库,整体架构如下:
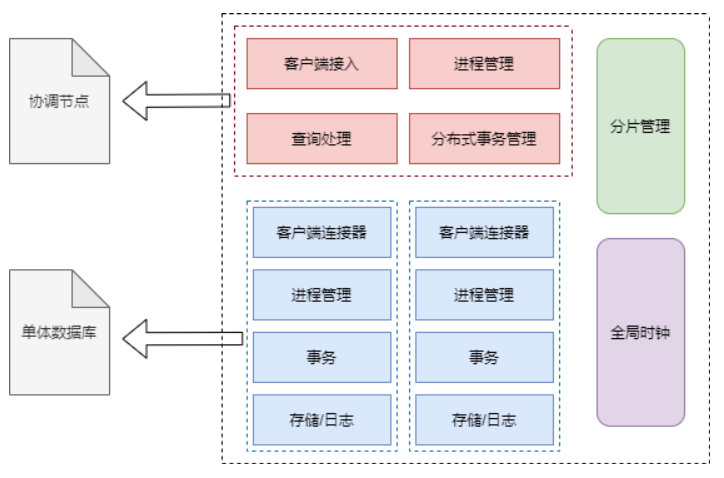
PGXC架构是对传统单体数据库做了集群,在集群的基础上加了协调节点,协调节点具有如下作用:
- 客户端接入
- 进程管理
- 分布式事务管理
- 查询处理
同时还增加了分片管理和全局时钟。分片管理用来管理集群的分片信息,全局时钟的介绍见下一节。
虽然PGXC名字的由来是PostgreSQL组成的分布式数据库,但是使用其他单体数据库组成的分布式数据库,也可以理解为PGXC,比如Golden使用的就是mysql作为内核。
1.2 NewSQL
跟PGXC采用传统单体数据库为内核相比,NewSQL是在NoSQL基于分布式键值存储系统的基础上构建了分布式事务处理能力。架构如下图:
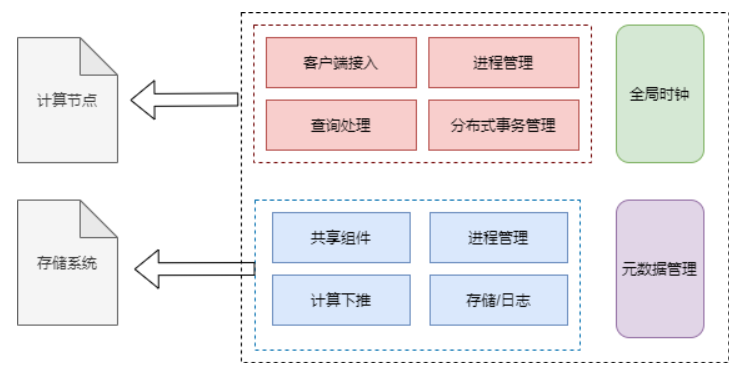
此外,NewSQL还有两个改进:
- 对于HA,放弃传统数据库的主从复制,使用Paxos、Raft等共识算法来保证多副本的一致性。
- 对于存储,使用LSM树模型替换B+树,写入性能更高。
2 全局时钟
2.1 线程一致性
线性一致性(Linearizability)是分布式系统中最强的一致性模型,总体思想是保证读取多个不同副本的客户端,跟读取同一个副本读到的结果一样,即整个系统看起来像只有一个副本。
先看两个不符合线性一致性的示例。
2.1.1 同一个客户端
如下图:
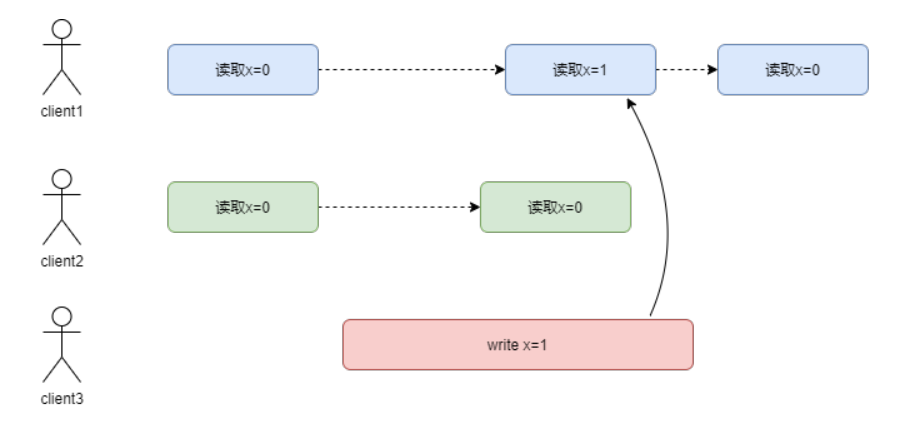
client1第一次读取了x的值是0,第二次读取时以为client3修改了x的值,所以读到了新的值1,但是第三次读取时因为读到了别的副本,因为这个副本还没有同步完成,所以读到了旧的值0。
2.1.2 不同客户端
如下图:
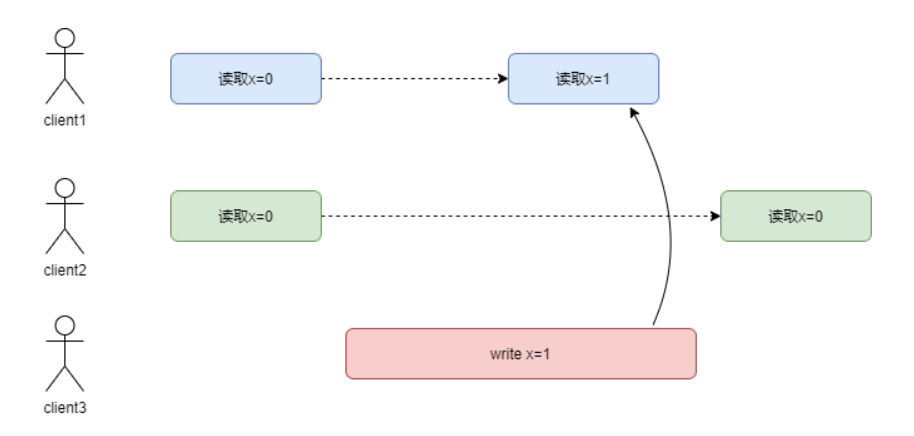
client1第一次读取了x的值是0,第二次读取时因为client3修改了x的值,所以读到了新的值1,但是在client1第二次读取之后,client2来读取x的值,因为读到了别的副本,因为这个副本还没有同步完成,所以读到了旧的值0。
线性一致性要求,任何一个客户端读取返回新值后,后面所有客户端(包括相同客户端和不同客户端)读取也必须返回新值
下面这个图就是线性一致性的:
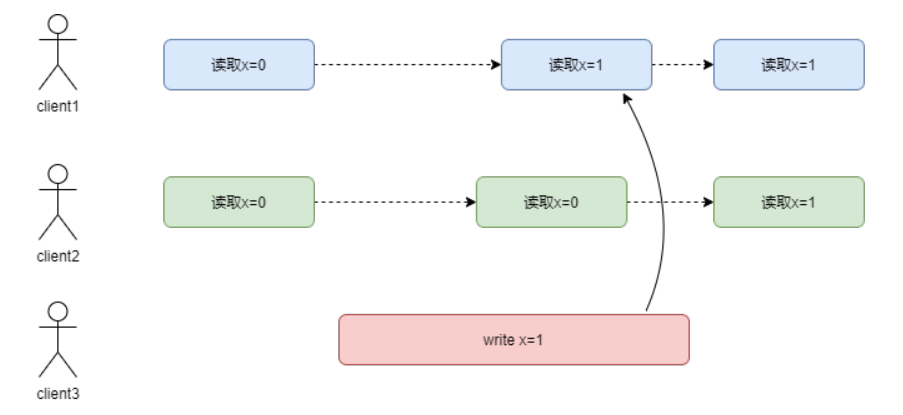
2.2 全局时钟
从上面的描述可以看到,线性一致性是建立在事件的先后顺序之上的。所有操作必须记录在一条时间线上,任意两个事件都有先后顺序。但是,集群中各个节点都有各自的时间线,怎么实现时间上的顺序性呢。这时就需要一个全局的绝对时间,就是这里讲的全局时钟。
一般来说,从一台时间服务器获取时间,就可以实现全局时钟,但是必须保证高可用。下面介绍几种全局时钟的实现方式:
2.2.1 TrueTime
Google Spanner采用GPS加原子钟来分配时间,支持多点授时机制。有两个明显的优势:
- 多点授时去中心化,实现了高可靠。
- 支持全球化部署,这样可以减少客户端和时间服务器的通信时长。
但是也存在一些问题:
- 采用物理时钟可以出现时钟偏移和时钟回拨。
- 多点授时可能出现系统整体的时间误差。
从Spanner的介绍看,时间误差在7毫秒以内。
2.2.2 混合逻辑时钟(HLC)
HLC(Hybrid Logical Clock),因为Truetime依赖于硬件设备来实现,实现难度大,所以有的数据库采用了混合逻辑时钟,即物理时钟和逻辑时钟配合使用,同样采多时间源、多点授时,所以也会有系统整体的时间误差问题。
2.2.3 Timestamp Oracle
简称TSO,中心化授时方案,采用单时间源、单点授时实现全局时钟,用一个全局唯一的时间戳作为xid(全局事务id)。
优点:
- 实现简单
- 单时间源单调递增,可以减少事务冲突
缺点也很明显
- 单点授时,性能会有瓶颈
- 不适合大规模集群部署
目前,TiDB、OceanBase都使用了这个方案。
2.2.4 总结
Spanner需要借助物理设备来实现,对其他开源数据库的参考价值并不大。
其他无论采用HLC还是TSO,都有各自的优缺点。
还有一种介于两者之间的授时方案,单时间源,多点授时,使用比较少。
3 HTAP
HTAP英文全称是 Hybrid Transaction and Analytical Processing,即混合事务和分析处理,能够将事务处理(OLTP)和数据分析(OLAP)请求在同一个数据库系统中完成。
HTAP需要在计算和存储两个层面支持OLTP和OLAP,存储是基础。OLTP通常使用行式存储,OLAP则一般使用列式存储,差异很大。HTAP解决这个差异的方式有两种:
- Google Spanner的PAX,一种新的融合性存储,即在行存储的基础上融合列存储的特点。
- TiDB的思路,借助Raft协议在OLTP与OLAP之间异步复制数据,通过OLAP的特殊设计来弥补异步带来的数据不一致。
OceanBase采用独创的分布式计算引擎,能让系统中多个计算节点同时运行OLTP类型的应用和OLAP类型的应用,实现了用一套计算引擎同时支持混合负载的能力。
4 RANGE动态分区
下图有4条数据,
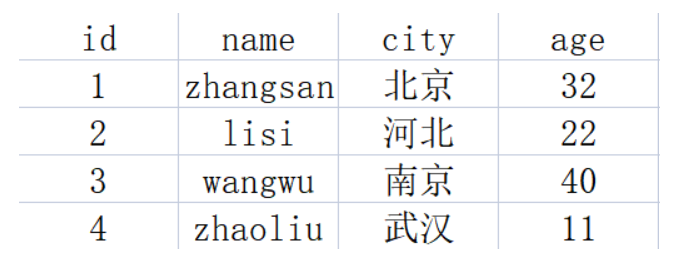
如果按照HASH进行分片,一般会选择id作为key进行HASH计算,之后根据计算结果把数据分配到不同的分片中。这样做的好处是实现简单,但也存在两个问题:
- 分片不具备业务属性,可能会存在业务热点访问的问题。
- 分片规模变化时,迁移数据问题。
Range分片技术跟HASH相比,很大的不同是数据并没有被打散。比如上表中,我们可以把数据按照城市进行分片,这样数据读取效率会更高。
Range动态分区用在NewSQL架构的分布式数据库中,一般具有下面的特性:
4.1 自动合并和拆分
可以给分配的数据量设置阈值,当某个分片的数据量超过最大阈值时,可以自动拆分成2个分片,当分片数据量小于最小阈值时,进行分片合并。
4.2 自动负载
当某个分片上的热点数据较多时,节点访问压力会很大,系统可以自动地将这些热点数据访问调度到不同节点,以均衡访问压力。
4.3 减少分布式事务
分布式事务的开销会远远大于本地事务,分布式数据库可以把频繁参与同一个分布式事务的数据调度到同一个分片上,这样就避开了分布式事务。
Spanner支持
4.4 就近访问
在全球部署的场景下,给用户分配最近节点的分片,可以减少访问延时。
Spanner支持
4.5 高可靠
分布式数据库的高可靠是分区级别的高可靠,下图是OceanBase中一个Zone的架构图:
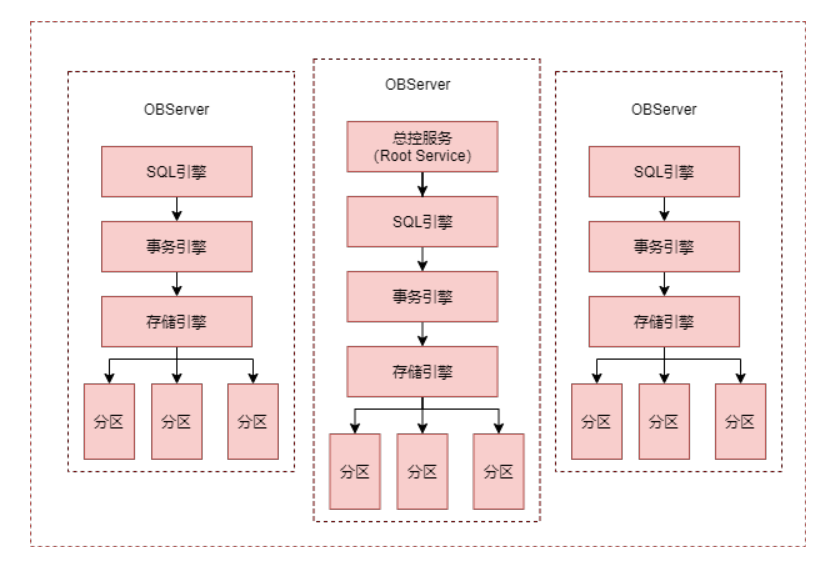
OceanBase基于Paxos算法来实现系统的高可用,最小的粒度可以做到分区级别。集群中数据的每一个分区会被保存到所有的Zone上,分区的多个副本采用Paxos协议进行日志同步。每个分区和它的副本构成一个独立的Paxos复制组,其中一个分区为Leader,其它分区为Follower。所有针对这个副本的写请求,都会自动路由到对应的主分区上进行。主分区可以分布在不同的OBServer上,这样对于不同副本的写操作也会分布到不同的数据节点上,从而实现数据多点写入,提高系统性能。
5 percalator模型
分布式数据库是在BigTable基础上增加了分布式事务解决方案。而Percolator模型就是Google提出的构建在BigTable之上的分布式事务解决方案。参考2[2]
percalator模型采用了2阶段提交的思想,这里以银行汇款为例,账户1给账户2汇款100元,这2个账户位于不同的分区上。
5.1 初始状态
初始阶段,假如初始时账户1上有300元,账户2上有500元,如下图:

上面表格中,":"前面是用时间戳表示的数据版本,后面是数据值。第一列是表名,第二列的低版本保存了数据,第三列列保存了数据上加的锁。第四列的高版本保存了指向保存数据版本的指针,比如6这个版本保存了指向了5这个版本数据的指针 6:data@5。
5.2 Prewrite
事务管理器向两个分片发送了Prepare请求,分片收到请求后,为每个要修改的数据行写日志,并且根据时间戳记录事务的私有版本,这里的私有版本就是7,这样就获得了锁,其他事务就不能操作这两条数据了。
如下图:

从第二列的数据可以看到,账户1上减少了200元,账户2上增加600元。从第三列可以看到账户1获得了primary lock,账户2上是指向primary lock的锁指针。
注意:primary lock的选择是随机的,账户1和账户2都可以选择。
5.3 commit
commit阶段,协调节点只需要跟拥有primary lock的分片进行通信,这里只需要跟账户1进行通信,从而保证了commit指令的原子性。这时数据如下表:
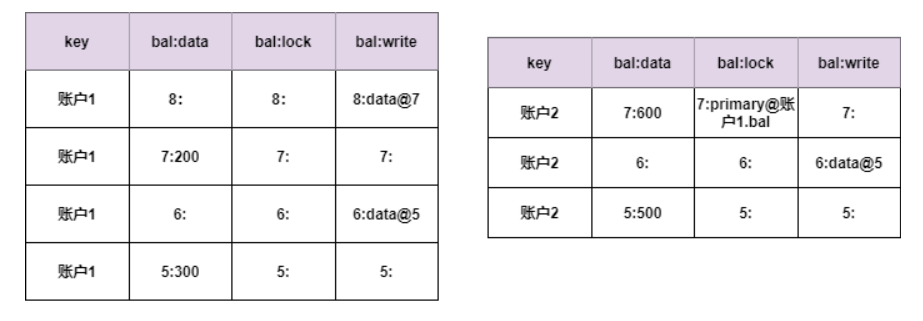
可以看到账户1的primary lock已经清除了,同时增加了8这个版本,8这个版本的数据指向版本7。这样7、8两个版本都不是私有版本了,其他事务就可以操作这条记录了。
私有版本还有一个作用,就是账户1提交失败后,账户2可以根据私有版本进行回滚。
5.4 事务结束
commit成功后并没有同步清除账户2上的私有版本和锁指针,而是会启动异步线程来清除,异步线程清除完成后,最终数据如下图:
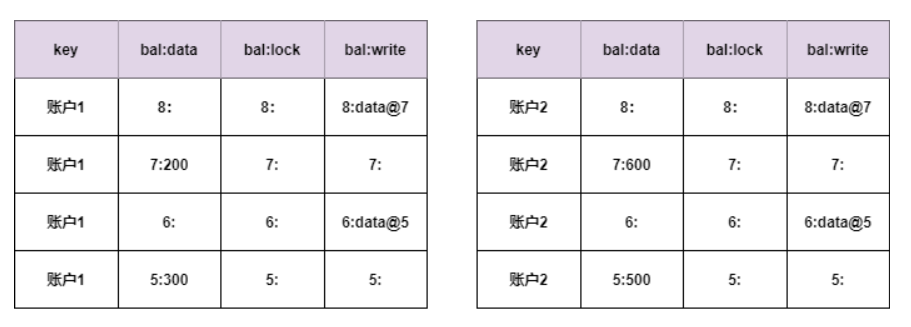
可以看到,最终账户2清除了锁指针和私有版本。
账户2上的lock没有同步清除,其他线程读取账户2时会根据primary@order.bal查找primary lock,如果发现primary lock已经清除,就可以继续读取。读取的同时做一下secondary lock清理工作。
6 总结
本文主要从5个方面入手讲了分布式数据库的关键知识,欢迎大家批评指正。
参考资料
[1]参考1: https://open.oceanbase.com/
[2]参考2: https://www.cs.princeton.edu/courses/archive/fall10/cos597B/papers/percolator-osdi10.pdf

























