首先要明白什么是事务?
事务是程序中一系列严密的操作,所有的操作必须完成,否则在所有的操作中所做的所有的更改都会被撤销。也就是事务的原子性,一个事务中的一系列的操作要么全部成功,要么就是失败。
事务的结束有两种,当事务中所有的步骤全部成功执行的时候,事务提交。如果其中一个步骤失败,将会发生回滚操作,撤销到事务开始之前的所有的操作。
事务的ACID
事务具有四个特征
- 原子性 事务是数据库的逻辑工作单位,事务中包含多个操作,要么都做完,要么都不做
- 隔离性(隔离性也是本文的重点) 事务彼此之间是不能互相干扰的,即一个事务的操作对该数据库的其他事务操作是隔离的,并发执行的各个事务时间互补干扰
- 持久性 事务一旦提交,其变更是永久性的
- 一致性 事务执行的结果必须满足从一个状态变到另一个状态,因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性的状态。如果数据库系统在运行时发生系统故障,有些未完成的事务被迫中止,而有一部分修改已经写入数据库,这个时候数据库就处于一种不正确的状态。
其实以上三个条件(原子性、隔离性、持久性)最终都是为了保持数据库数据的一致性服务的
MySQL的四种隔离级别
SQL标准定义了四种隔离级别,用来限定事务内外的哪些改变是可见的,哪些是不可见的。
- 读取未提交的数据【Read Uncommitted】 在该隔离级别,所有的事务都可以看到其他事务没有提交的执行结果。(实际生产中不可能使用这种隔离级别的)
- 读取提交的内容【Read Committed】 该隔离级别是大多数数据库的默认的隔离级别(不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看到其他的已经提交的事务所做的改变。这种隔离级别也支持不可重复读,即同一个 select 可能得到不同的结果
- 可重读【Repeatable Read】 这是 MySQL 默认的隔离级别,它确保同一个事务在并发读取数据时,会看到同样的数据行。不过理论上会导致另外一个问题,【幻读】。幻读:相同的条件查询一些数据,然后其他事务【新增】或者是【删除】了该条件的数据,然后导致读取的结果不一样多。InnoDB 存储引擎通过多版本控制(MVCC)机制解决了该问题
- 可串行化【serializable】 这是事务的最高隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决了幻读的问题。它在每个读的数据行上面加上共享锁,。但是可能会导致超时和锁竞争(这种隔离级别太极端,实际生产基本不使用)
这四种隔离级别采用不同的锁类型来实现
- 脏读 读取了前一个事务未提交的或者是回滚的数据
- 不可重复度 同样的 select 查询,但是结果不同,过程中有事务更新了原有的数据
- 幻读 两次查询的结果数量不一样,过程中有事务新增或者是删除数据
下面对不同的隔离级别产生的不同的问题做一个汇总
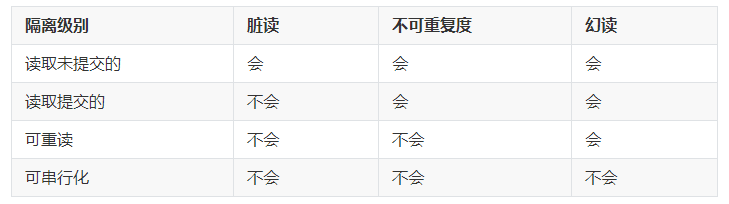
各个隔离级别的详细测试
查看数据库的隔离级别
- show variables like '%isolation%'
设置数据库的隔离级别
- set session transaction isolation level Read Uncommitted;
设置数据库的隔离级别为:Read Uncommitted
实验一:Read Uncommitted
Read Uncommitted 即:读取未提交
前置条件:将数据库的隔离级别设置为read uncomitted;
- set session transaction isolation level Read Uncommitted;

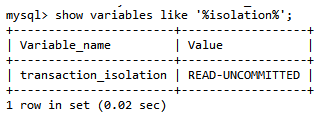
第一步:A开启事务:start tracsaction;

第二步:A查询数据:select * from test;
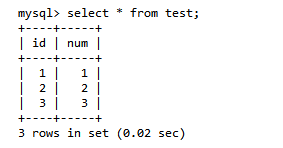
第三步:B开启事务:start transaction;

第四步:B查询数据:select * from test;

第五步:B更新数据:update test set num =10 where id = 1;B没有提交事务
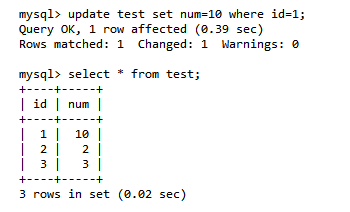
第六步:A读取数据----A读取到了B未提交的数据(当前数据库的隔离级别是:Read Uncommitted)

第七步:B回滚数据:rollback;

第八步:B查询数据:select * from test;

第九步:A查询数:select * from test;
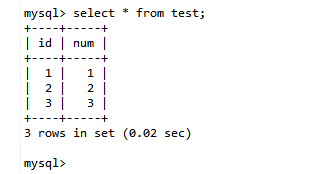
结论:事务B更新了数据,但是没有提交,事务A读取到的是B未提交的记录。因为造成脏读。Read Uncommitted是最低的隔离级别
实验二:读取已提交-Read Committed
前置条件:将数据库的隔离级别设置为:Read Committed;
- set session transaction isolaction level Read Committed;

第一步:A开始事务:start transaction;

第二步:A查询数据:select *from test;

第三步:B开启事务:start transaction;

第四步:B查询数据:select * from test;
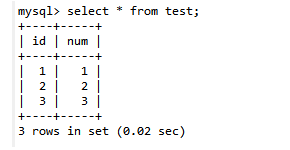
第五步:B更新数据:update test set num =10 where id=1
查看结果:
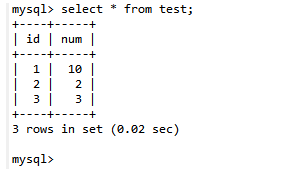
第六步:A查询数据:select * from test;

第七步:B提交数据:commit;

第八步:A查询数据:select * from test;
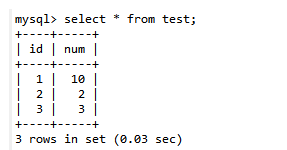
结论:Read Committed 读已提交的隔离级别解决了脏读的问题,但是出现了不可重复读的问题,即事务A在两次查询的结果不一致,因为在两次查询之间事务B更新了一条数据。
读已提交的只允许读取已经提交的记录 ,但是不要求可重复读
实验三:可重读度-Repeatable Read
前置条件:将数据库的级别设置为可重复度
set session transaction isolation level repeatable read;

第一步:A开始事务:start transaction;

第二步:A查询数据:select * from test;

第三步:B开启事务:start transaction;

第四步:B查询数据:select * from test;

第五步:B更新数据:update test set num=10 where id=1;

此时B并没有提交事务
第六步:B查询数据:select * from test;

第七步:A查询数据
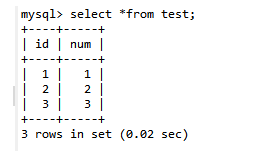
结果仍然是之前的结果(因为B事务还没有提交)
第八步:B提交事务:commit;

第九步:A查询数据:select * from test;此时A查询的记录仍然和之前一样

第十步:B插入一条数据并提交事务:inset into test(num) value(4);

第十一步:A查询数据,发现结果还是和之前的一样:select * from test;
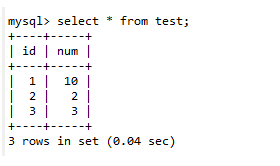
第十二步:A提交事务并查询数据

此时发现A查询的数据已经和B查询的结果一致了;
结论:Repeatable Read隔离级别只允许读取已经提交的事务的记录,
实验四:串行化-Serializable
前置条件:将数据库的隔离级别设置为可串行化

第一步:A开始事务并查询数据
第二步:B开启事务并insert数据,发现只能等待,并不能执行下去

第三步:A提交事务

第四步:B插入数据

结论:serializable完全锁定字段,若一个事务来操作同一份数据,那么就必须等待,直到前一个事务完成并解除锁为止。是完整的隔离级别,会锁住对应的数据表,因为会导致效率问题。
本文小结
本片文章并没有深入的去讲解原理,而是让大家能够从更直观的从隔离级别的表面去了解隔离级别,因为我发现我的很多同事对此是模模糊糊,模棱两可的,但是这个是不可以的,因为技术本身是不允许存在这种歧义的,懂就是懂,才能合理运用,如果模棱两可,那么在实际运用中一定也是漏洞百出,所以这也是这篇文章诞生的原因。
我们可以先抛开原理与底层的具体实现,先能够清晰且明了的搞清楚各个专业术语的含义,这未尝不是一种进步。