本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
使用机器学习时,你是不是经常因为有太多无关特征而导致模型效果不佳而烦恼?
而其实,降维就是机器学习中能够解决这种问题的一种好方法。
知名科技博主Ben Dickson 对此进行了探讨,并在TechTalks上发表了博客《机器学习:什么是降维》,本文的编译整理已受到Ben Dickson 本人授权。
他指出,机器学习算法因为能够从具有许多特征的数据集中找出相关信息而大火,这些数据集往往包括了几十行的表格或者数百万像素的图像。
云计算的突破可以帮助使用者运行大型的机器学习模型,而不用管后台的计算能力。
但是,每增加一个新特征都会增加复杂性,增大使用机器学习算法的困难。
数据科学家通常使用降维,这是一套从机器学习模型中去除过多或者无关特征的技术。
降维可以降低机器学习的成本,有时还可以帮助用更简单的模型来解决复杂的问题。
以下让我们来看看是他的文章。
维度的诅咒
机器学习模型可以将特征映射到结果。
比如,假设你想创建一个模型,来预测一个月内的降雨量:
你有一个在不同月份从不同城市收集的各类信息的数据集,包括温度、湿度、城市人口、交通、在城市举办的音乐会数量、风速、风向、气压、购买的汽车票数量和降雨量。
显然,这些信息并不是都和降雨预测有关。
有些特征可能和目标变量毫无关系。
比如,人口和购买的汽车票数量并不影响降雨量。
其他特征可能与目标变量相关,但与它没有因果关系。
比如,户外音乐会的数量可能与降雨量相关,但它不是一个很好的降雨预测器。
在其他情况下,比如碳排放,特征和目标变量之间可能有联系,但效果可以忽略不计。
在这个例子中,哪些特征是有价值的,哪些是无用的,是显而易见的。
在其他问题中,过度的特征可能不明显,这就需要进一步的数据分析。
但是,为什么要费力地去除多余的维度呢?
因为当你有太多的特征时,你也会需要一个更复杂的模型,这就意味着你需要更多的训练数据和更多的计算能力,才能把模型训练到一个可接受的水平。
由于机器学习不了解因果关系,即使没有因果关系,模型也会试图将数据集中的任何特征映射到目标变量,这可能会导致模型错误。
另一方面,减少特征的数量会使机器学习模型更简单,更有效,对数据的要求也更低。
很多特征造成的问题通常被称为 “维度的诅咒”,而且它们并不限于表格数据。
考虑一个对图像进行分类的机器学习模型。如果你的数据集由100×100像素的图像组成,那么每个像素一个,这样的问题空间有10,000个特征。然而,即使在图像分类问题中,一些特征也是过度的,可以被删除。
降维可以识别并删除那些损害机器学习模型性能或对其准确性没有贡献的特征。
目前有几种降维技术,每一种都有有用的适用范围。
特征选择
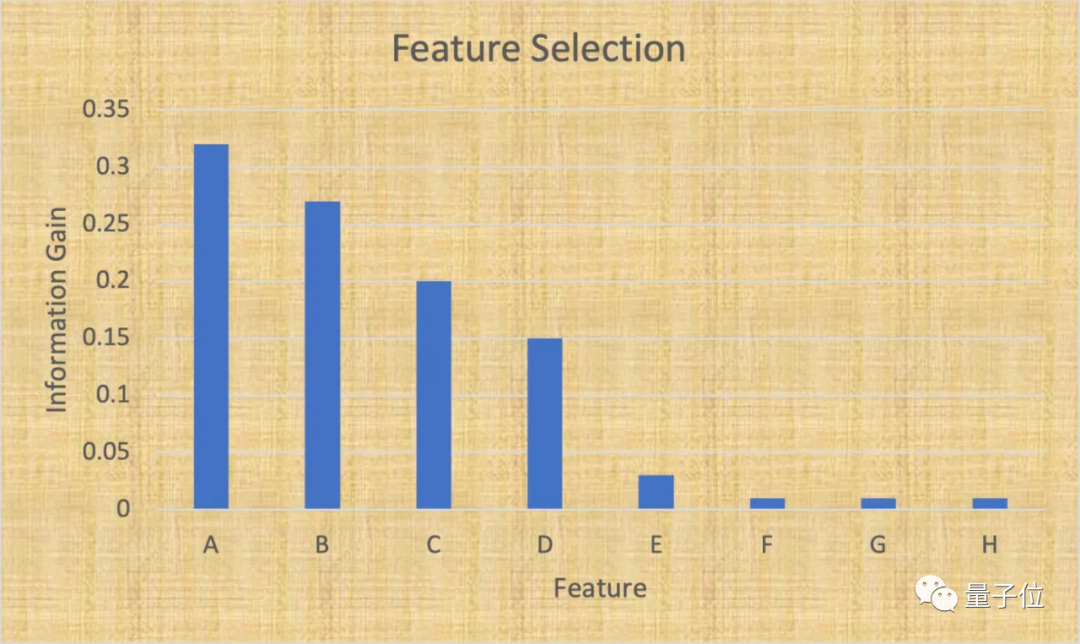
一个基本且有效的降维方法是“特征选择”,就是识别和选择与目标变量最相关的特征子集。
当处理表格数据时,特征选择非常有效,因为其中的每一列都代表了一种特定的信息。
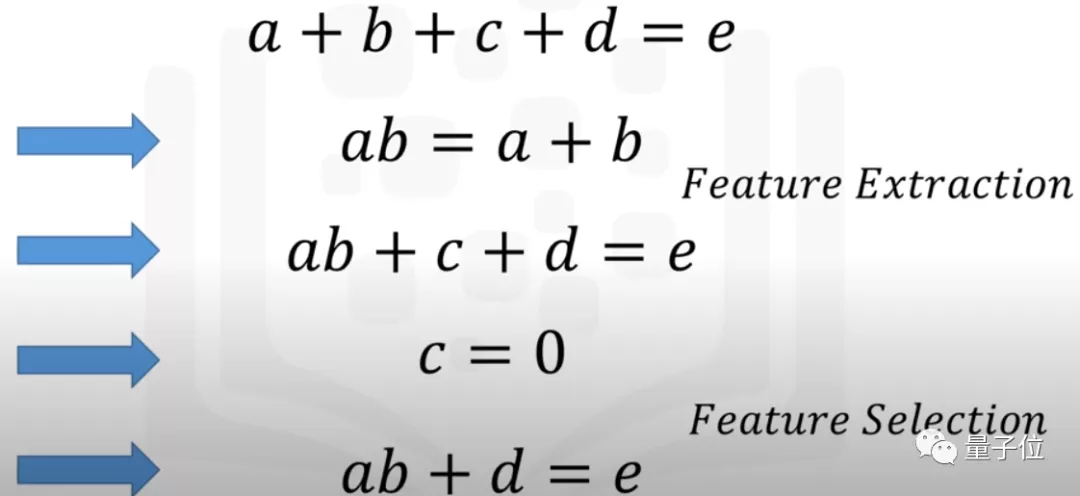
在进行特征选择时,数据科学家要做两件事:
保留与目标变量高度相关的特征,和对数据集的方差贡献最大的特征。
Python的Scikit-learn库开发了很多功能,能够分析、可视化和选择正确的特征,来实现机器学习模型。
比如,数据科学家可以使用散点图和热图来可视化不同特征的协方差。
如果两个特征高度相关,那么它们将对目标变量产生类似的影响,因此,可以删除其中一个,而不会对模型造成负面影响。
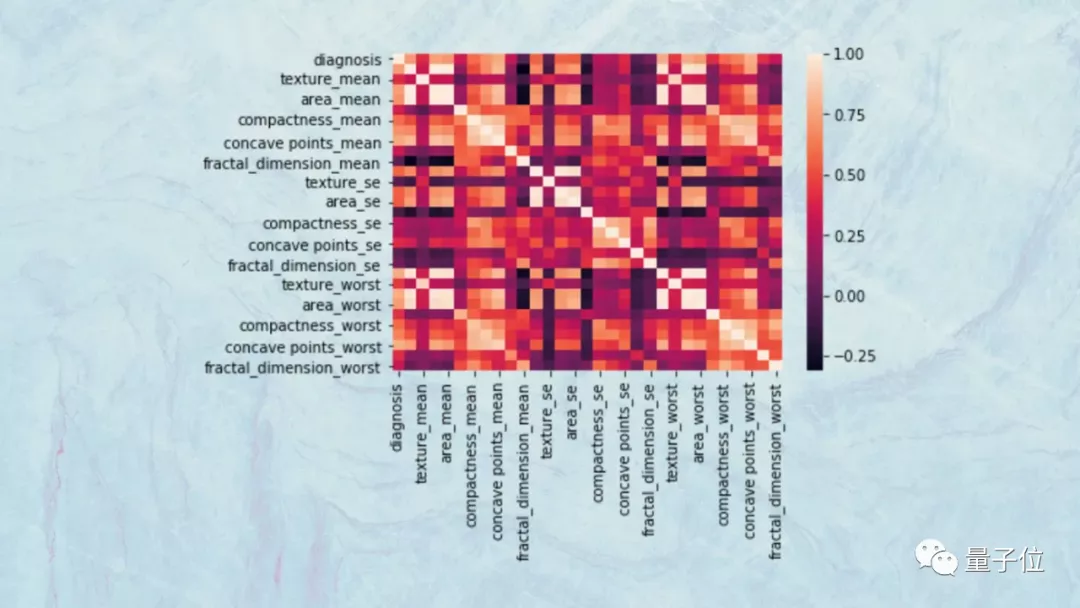
这些工具还可以帮助可视化特征和分析目标变量之间的关联性,从而帮助去除不影响目标变量的变量。
比如,你可能会发现,在你的数据集的25个特征中,有7个对目标变量的影响占到了95%。
所以能够删除18个特征,使机器学习模型变得更简单,而不会对模型的准确性产生太大影响。
投影技术
有时,你没办法删除个别特征,但这并不意味着不能简化机器学习模型。
投影技术 就是一个好办法,也被称为 “特征提取” ,可以通过将几个特征压缩到一个低维空间来简化模型。
用于表示投影技术的一个常见示例是 “瑞士卷”。
这是一组围绕三维焦点旋转的数据点,这个数据集有三个特征。每个点(目标变量)的值是根据它沿卷曲路径到瑞士卷中心的距离来测量的。在下面的图片中,红点更靠近中心,黄点沿着滚动方向更远。
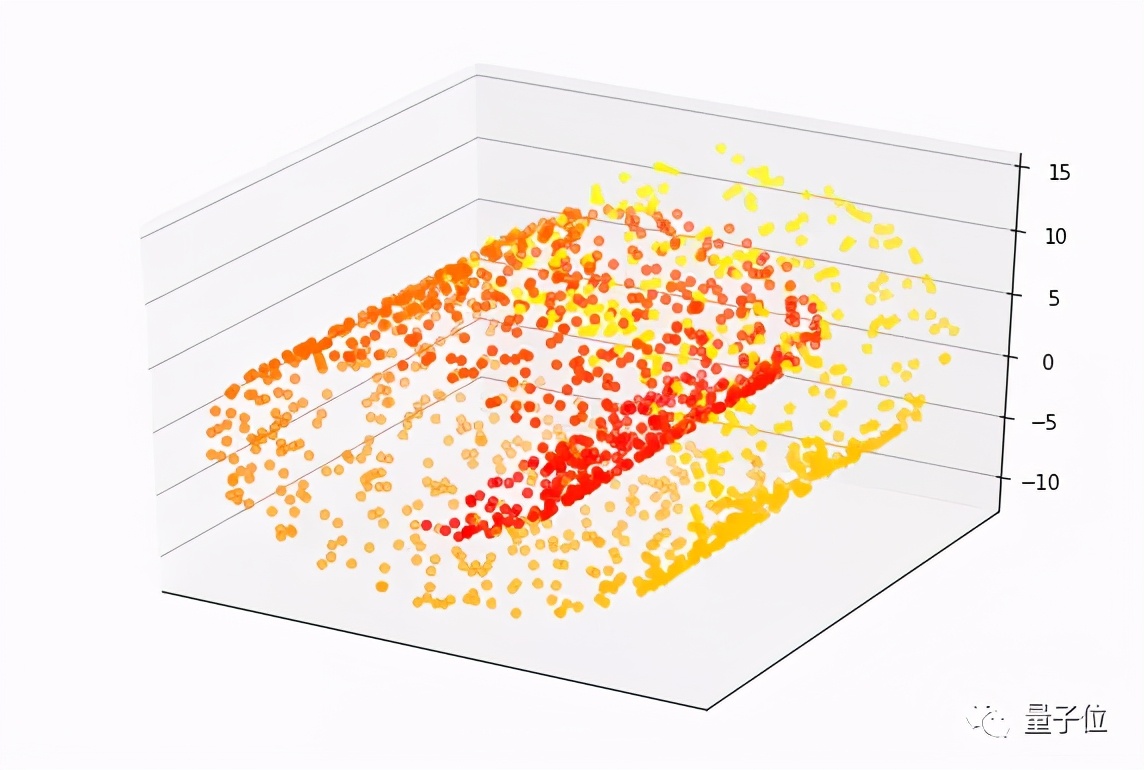
创建一个机器学习模型,将瑞士卷点的特征映射到它们的值非常难,需要一个具有许多参数的复杂模型。但是,引入降维技术,这些点可以被投射到一个较低维度的空间,可以用一个简单的机器学习模型来学习。
有各种投影技术。在上面的例子中,我们使用了 “局部线性嵌入(LLE)”的方法,这种算法可以降低问题空间的维度,同时保留了分离数据点数值的关键元素。当我们的数据用LLE处理时,结果看起来就像下面的图片,这就像一个展开的瑞士卷。
你可以看到,每种颜色的点都保持在一起。因此,这个问题仍然可以简化为一个单一的特征,并用最简单的机器学习算法(线性回归)建模。
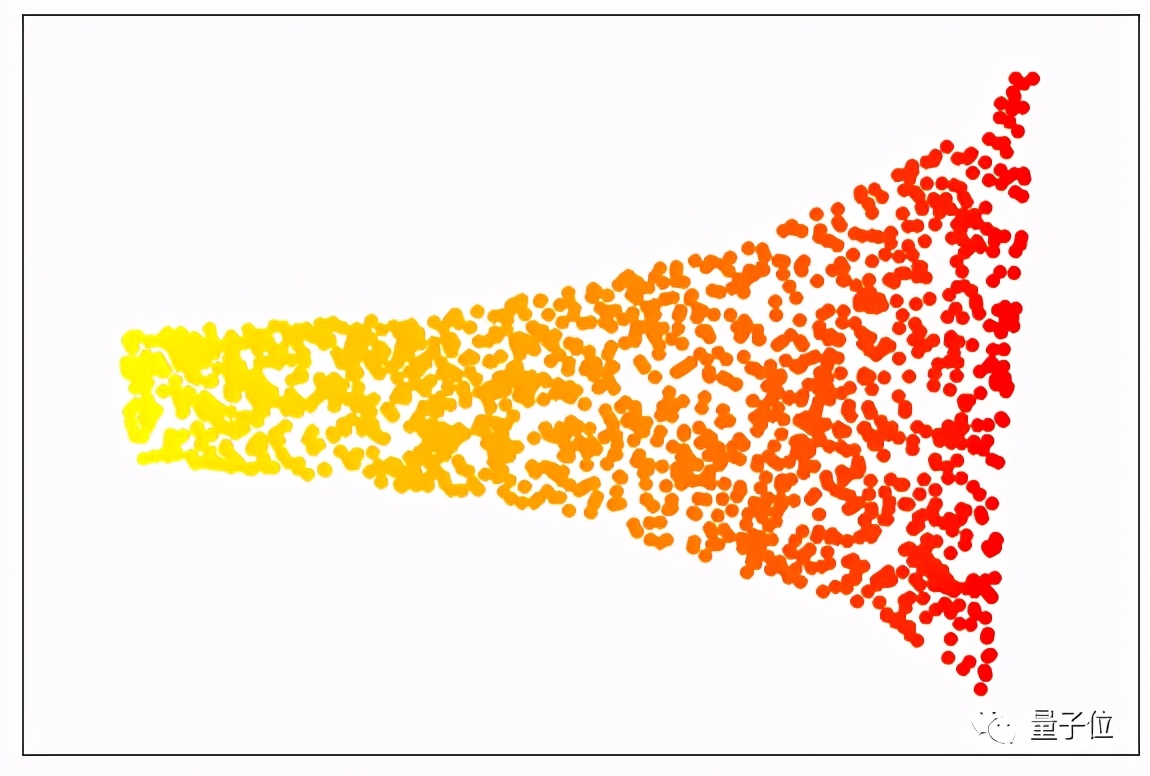
虽然这个例子是假设性的,但如果你把特征投射到一个较低维度的空间,经常会面临一些可以简化的问题。
比如, “主成分分析”(PCA) 是一种流行的降维算法,在简化机器学习问题方面有许多有用的应用。
在优秀的《用Python进行机器学习(Hands-on Machine Learning with Python)》一书中,数据科学家Aurelien Geron展示了如何使用PCA将MNIST数据集从784个特征(28×28像素)减少到150个特征,同时保留了95%的方差。
这种降维水平对人工神经网络的训练和运行成本的影响特别大。

关于投影技术,有几个注意事项需要考虑:
一旦你开发了投影技术,就必须先将新数据点转换到低维空间,然后再通过机器学习模型运行它们。但如果这个预处理步骤的成本太大,最后模型的收益太小的话,可能不太值。
第二个问题是,转换后的数据点可能不能直接代表其原始特征,如果将它们再转换回原始空间可能很麻烦,某些情况下也不太可行,因此这可能会很难解释模型的推论。
机器学习工具箱中的降维
简单总结一下。
过多的特征会降低机器学习模型的效率,但删除过多的特征也不太好。
数据科学家可以用降维作为一个工具箱,生成好的机器学习模型,但和其他工具一样,使用降维的时候也有许多问题,有许多地方都需要小心。
作者简介
知名科技博主、软件工程师Ben Dickson,TechTalks的创始人。