













本文转载自微信公众号「Linux内核远航者」,作者Linux内核远航者。转载本文请联系Linux内核远航者公众号。
1.开场白
- 环境:
处理器架构:arm64
内核源码:linux-5.11
ubuntu版本:20.04.1
代码阅读工具:vim+ctags+cscope
我们知道,Linux系统中我们经常将一个块设备上的文件系统挂载到某个目录下才能访问这个文件系统下的文件,但是你有没有思考过:为什么块设备挂载之后才能访问文件?挂载文件系统Linux内核到底为我们做了哪些事情?是否可以不将文件系统挂载到具体的目录下也能访问?下面,本文将详细讲解Linxu系统中,文件系统挂载的奥秘。
注:本文主要讲解文件系统挂载核心逻辑,暂不涉及挂载命名空间和绑定挂载等内容(后面的内容可能会涉及),且以ext2磁盘文件系统为例讲解挂载。本专题文章分为上下两篇,上篇主要介绍挂载全貌以及具体文件系统的挂载方法,下篇介绍如何通过挂载实例关联挂载点和超级块。
2. vfs 几个重要对象
在这里我们不介绍整个IO栈,只说明和文件系统相关的vfs和具体文件系统层。我们知道在Linux中通过虚拟文件系统层VFS统一所有具体的文件系统,提取所有具体文件系统的共性,屏蔽具体文件系统的差异。VFS既是向下的接口(所有文件系统都必须实现该接口),同时也是向上的接口(用户进程通过系统调用最终能够访问文件系统功能)。
下面我们来看下,vfs中几个比较重要的结构体对象:
2.1 file_system_type
这个结构来描述一种文件系统类型,一般具体文件系统会定义这个结构,然后注册到系统中;定义了具体文件系统的挂载和卸载方法,文件系统挂载时调用其挂载方法构建超级块、跟dentry等实例。
文件系统分为以下几种:
1)磁盘文件系统
文件在非易失性存储介质上(如硬盘,flash),掉电文件不丢失。
如ext2,ext4,xfs
2)内存文件系统
文件在内存上,掉电丢失。
如tmpfs
3)伪文件系统
是假的文件系统,是利用虚拟文件系统的接口(可以对用户可见如proc、sysfs,也可以对用户不可见内核可见如sockfs,bdev)。
如proc,sysfs,sockfs,bdev
4)网络文件系统
这种文件系统允许访问另一台计算机上的数据,该计算机通过网络连接到本地计算机。
如nfs文件系统
结构体定义源码路径:include/linux/fs.h +2226
2.2 super_block
超级块,用于描述块设备上的一个文件系统总体信息(如文件块大小,最大文件大小,文件系统魔数等),一个块设备上的文件系统可以被挂载多次,但是内存中只能有个super_block来描述(至少对于磁盘文件系统来说)。
结构体定义源码路径:include/linux/fs.h +1414
2.3 mount
挂载描述符,用于建立超级块和挂载点等之间的联系,描述文件系统的一次挂载,一个块设备上的文件系统可以被挂载多次,每次挂载内存中有一个mount对象描述。
结构体定义源码路径:fs/mount.h +39
2.4 inode
索引节点对象,描述磁盘上的一个文件元数据(文件属性、位置等),有些文件系统需要从块设备上读取磁盘上的索引节点,然后在内存中创建vfs的索引节点对象,一般在文件第一次打开时创建。
结构体定义源码路径:include/linux/fs.h +610
2.5 dentry
目录项对象,用于描述文件的层次结构,从而构建文件系统的目录树,文件系统将目录当作文件,目录的数据由目录项组成,而每个目录项存储一个目录或文件的名称和索引节点号等内容。每当进程访问一个目录项就会在内存中创建目录项对象(如ext2路径名查找中,通过查找父目录数据块的目录项,找到对应文件/目录的名称,获得inode号来找到对应inode)。
结构体定义源码路径:include/linux/dcache.h +90
2.6 file
文件对象,描述进程打开的文件,当进程打开文件时会创建文件对象加入到进程的文件打开表,通过文件描述符来索引文件对象,后面读写等操作都通过文件描述符进行(一个文件可以被多个进程打开,会由多个文件对象加入到各个进程的文件打开表,但是inode只有一个)。
结构体定义源码路径:include/linux/fs.h +915
3. 挂载总体流程
3.1系统调用处理
用户执行挂载是通过系统调用路径进入内核处理,拷贝用户空间传递参数到内核,挂载委托do_mount。
//fs/namespace.c
SYSCALL_DEFINE5(mount
参数:
dev_name 要挂载的块设备
dir_name 挂载点目录
type 文件系统类型名
flags 挂载标志
data 挂载选项
-> kernel_type = copy_mount_string(type); //拷贝文件系统类型名到内核空间
-> kernel_dev = copy_mount_string(dev_name) //拷贝块设备路径名到内核空间 -> options = copy_mount_options(data) //拷贝挂载选项到内核空间
-> do_mount(kernel_dev, dir_name, kernel_type, flags, options) //挂载委托do_mount
3.2 挂载点路径查找
挂载点路径查找,挂载委托path_mount
do_mount
-> user_path_at(AT_FDCWD, dir_name, LOOKUP_FOLLOW, &path) //挂载点路径查找 查找挂载点目录的 vfsmount和dentry 存放在 path
-> path_mount(dev_name, &path, type_page, flags, data_page) //挂载委托path_mount
3.3 参数合法性检查
参数合法性检查, 新挂载委托do_new_mount
path_mount
-> 参数合法性检查
-> 根据挂载标志调用不同函数处理 这里讲解是默认 do_new_mount
3.4 调用具体文件系统挂载方法
do_new_mount
-> type = get_fs_type(fstype) //根据传递的文件系统名 查找已经注册的文件系统类型
-> fc = fs_context_for_mount(type, sb_flags) //为挂载分配文件系统上下文 struct fs_context
-> alloc_fs_context
-> 分配fs_context fc = kzalloc(sizeof(struct fs_context), GFP_KERNEL)
-> 设置 ...
-> fc->fs_type = get_filesystem(fs_type); //赋值相应的文件系统类型
-> init_fs_context = **fc->fs_type->init_fs_context**; //新内核使用fs_type->init_fs_context接口 来初始化文件系统上下文
if (!init_fs_context) //init_fs_context回掉 主要用于初始化
init_fs_context = **legacy_init_fs_context**; //没有 fs_type->init_fs_context接口
-> init_fs_context(fc) //初始化文件系统上下文 (初始化一些回掉函数,供后续使用)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
来看下文件系统类型没有实现init_fs_context接口的情况:
//fs/fs_context.c
init_fs_context = legacy_init_fs_context
-> fc->ops = &legacy_fs_context_ops //设置文件系统上下午操作
->.get_tree = legacy_get_tree //操作方法的get_tree用于 读取磁盘超级块并在内存创建超级块,创建跟inode, 跟dentry
-> root = fc->fs_type->mount(fc->fs_type, fc->sb_flags,
¦ fc->source, ctx->legacy_data) //调用文件系统类型的mount方法来读取并创建超级块
-> fc->root = root //赋值创建好的跟dentry
有一些文件系统使用原来的接口(fs_type.mount = xxx_mount):如ext2,ext4等
有一些文件系统使用新的接口(fs_type.init_fs_context = xxx_init_fs_context):xfs, proc, sys
无论使用哪一种,都会在xxx_init_fs_contex中实现 fc->ops = &xxx_context_ops 接口,后面会看的都会调用fc->ops.get_tree 来读取创建超级块实例
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
继续往下走:
do_new_mount
-> ...
-> fc = fs_context_for_mount(type, sb_flags) //分配 赋值文件系统上下文
-> parse_monolithic_mount_data(fc, data) //调用fc->ops->parse_monolithic 解析挂载选项
-> mount_capable(fc) //检查是否有挂载权限
-> vfs_get_tree(fc) //fs/super.c 挂载重点 调用fc->ops->get_tree(fc) 读取创建超级块实例
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
3.5 挂载实例添加到全局文件系统树
do_new_mount
...
-> do_new_mount_fc(fc, path, mnt_flags) //创建mount实例 关联挂载点和超级块 添加到命名空间的挂载树中
- 1.
- 2.
- 3.
下面主要看下vfs_get_tree和do_new_mount_fc:
4.具体文件系统挂载方法
1)vfs_get_tree
//以ext2文件系统为例
vfs_get_tree //fs/namespace.c
-> fc->ops->get_tree(fc)
-> legacy_get_tree //上面分析过 fs_type->init_fs_context == NULL使用旧的接口(ext2为NULL)
->fc->fs_type->mount
-> ext2_mount //fs/ext2/super.c 调用到具体文件系统的挂载方法
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
来看下ext2对挂载的处理:
启动阶段初始化->
//fs/ext2/super.c
module_init(init_ext2_fs)
init_ext2_fs
->init_inodecache //创建ext2_inode_cache 对象缓存
->register_filesystem(&ext2_fs_type) //注册ext2的文件系统类型
static struct file_system_type ext2_fs_type = {
.owner = THIS_MODULE,
.name = "ext2",
.mount = ext2_mount, //挂载时调用 用于读取创建超级块实例
.kill_sb = kill_block_super, //卸载时调用 用于释放超级块
.fs_flags = FS_REQUIRES_DEV, //文件系统标志为 请求块设备,文件系统在块设备上
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
挂载时调用->
// fs/ext2/super.c
static struct dentry *ext2_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return mount_bdev(fs_type, flags, dev_name, data, ext2_fill_super);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
ext2_mount通过调用mount_bdev来执行实际文件系统的挂载工作,ext2_fill_super的一个函数指针作为参数传递给get_sb_bdev。该函数用于填充一个超级块对象,如果内存中没有适当的超级块对象,数据就必须从硬盘读取。
mount_bdev是个公用的函数,一般磁盘文件系统会使用它来根据具体文件系统的fill_super方法来读取磁盘上的超级块并在创建内存超级块。
我们来看下mount_bdev的实现(**它执行完成之后会创建vfs的三大数据结构 super_block、根inode和根dentry **):
2)mount_bdev源码分析
//fs/super.c
mount_bdev
->bdev = blkdev_get_by_path(dev_name, mode, fs_type) //通过要挂载的块设备路径名 获得它的块设备描述符block_device(会涉及到路径名查找和通过设备号在bdev文件系统查找block_device,block_device是添加块设备到系统时创建的)
-> s = sget(fs_type, test_bdev_super, set_bdev_super, flags | sb_NOSEC,
¦bdev); //查找或创建vfs的超级块 (会首先在文件系统类型的fs_supers链表查找是否已经读取过指定的超级块,会对比每个超级块的s_bdev块设备描述符,没有创建一个)
-> if (s->s_root) { //超级块的根dentry是否被赋值?
...
} else { //没有赋值说明时新创建的sb
...
-> sb_set_blocksize(s, block_size(bdev)) //根据块设备描述符设置文件系统块大小
-> fill_super(s, data, flags & sb_SILENT ? 1 : 0) //调用传递的具体文件系统的填充超级块方法读取填充超级块等 如ext2_fill_super
-> bdev->bd_super = s //块设备bd_super指向sb
}
-> return dget(s->s_root) //返回文件系统的根dentry
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
可以看到mount_bdev主要是:1.根据要挂载的块设备文件名查找到对应的块设备描述符(内核后面操作块设备都是使用块设备描述符);2.首先在文件系统类型的fs_supers链表查找是否已经读取过指定的vfs超级块,会对比每个超级块的s_bdev块设备描述符,没有创建一个vfs超级块; 3.新创建的vfs超级块,需要调用具体文件系统的fill_super方法来读取填充超级块。
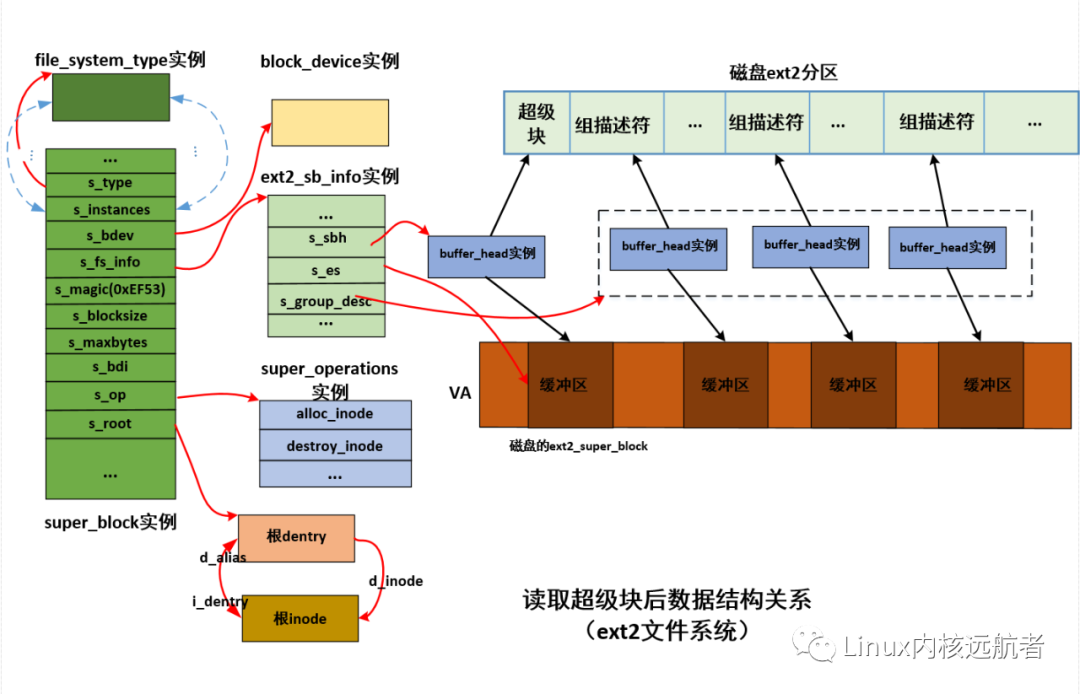
那么下面主要集中在具体文件系统的fill_super方法,这里是ext2_fill_super:
分析重点代码如下:
3)ext2_fill_super源码分析
//fs/ext2/super.c
static int ext2_fill_super(struct super_block *sb, void *data, int silent)
{
struct buffer_head * bh; //缓冲区头 记录读取的磁盘超级块
struct ext2_sb_info * sbi; //内存的ext2 超级块信息
struct ext2_super_block * es; //磁盘上的 超级块信息
...
sbi = kzalloc(sizeof(*sbi), GFP_KERNEL); //分配 内存的ext2 超级块信息结构
if (!sbi)
goto failed;
...
sb->s_fs_info = sbi; //vfs的超级块 的s_fs_info指向内存的ext2 超级块信息结构
sbi->s_sb_block = sb_block;
if (!(bh = sb_bread(sb, logic_sb_block))) { // 读取磁盘上的超级块到内存的 使用buffer_head关联内存缓冲区和磁盘扇区
ext2_msg(sb, KERN_ERR, "error: unable to read superblock");
goto failed_sbi;
}
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset); //转换为struct ext2_super_block 结构
sbi->s_es = es; // 内存的ext2 超级块信息结构的 s_es指向真正的ext2磁盘超级块信息结构
sb->s_magic = le16_to_cpu(es->s_magic); //获得文件系统魔数 ext2为0xEF53
if (sb->s_magic != EXT2_SUPER_MAGIC) //验证 魔数是否正确
goto cantfind_ext2;
blocksize = BLOCK_SIZE << le32_to_cpu(sbi->s_es->s_log_block_size); //获得磁盘读取的块大小
/* If the blocksize doesn't match, re-read the thing.. */
if (sb->s_blocksize != blocksize) { //块大小不匹配 需要重新读取超级块
brelse(bh);
if (!sb_set_blocksize(sb, blocksize)) {
ext2_msg(sb, KERN_ERR,
"error: bad blocksize %d", blocksize);
goto failed_sbi;
}
logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize;
offset = (sb_block*BLOCK_SIZE) % blocksize;
bh = sb_bread(sb, logic_sb_block); //重新 读取超级块
if(!bh) {
ext2_msg(sb, KERN_ERR, "error: couldn't read"
"superblock on 2nd try");
goto failed_sbi;
}
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset);
sbi->s_es = es;
if (es->s_magic != cpu_to_le16(EXT2_SUPER_MAGIC)) {
ext2_msg(sb, KERN_ERR, "error: magic mismatch");
goto failed_mount;
}
}
sb->s_maxbytes = ext2_max_size(sb->s_blocksize_bits); //设置最大文件大小
...
//读取或设置 inode大小和第一个inode号
if (le32_to_cpu(es->s_rev_level) == EXT2_GOOD_OLD_REV) {
sbi->s_inode_size = EXT2_GOOD_OLD_INODE_SIZE;
sbi->s_first_ino = EXT2_GOOD_OLD_FIRST_INO;
} else {
sbi->s_inode_size = le16_to_cpu(es->s_inode_size);
sbi->s_first_ino = le32_to_cpu(es->s_first_ino);
...
}
...
sbi->s_blocks_per_group = le32_to_cpu(es->s_blocks_per_group); //赋值每个块组 块个数
sbi->s_frags_per_group = le32_to_cpu(es->s_frags_per_group);
sbi->s_inodes_per_group = le32_to_cpu(es->s_inodes_per_group); //赋值每个块组 inode个数
sbi->s_inodes_per_block = sb->s_blocksize / EXT2_INODE_SIZE(sb); //赋值每个块 inode个数
...
sbi->s_desc_per_block = sb->s_blocksize /
sizeof (struct ext2_group_desc); //赋值每个块 块组描述符个数
sbi->s_sbh = bh; //赋值读取的超级块缓冲区
sbi->s_mount_state = le16_to_cpu(es->s_state); //赋值挂载状态
...
if (sb->s_magic != EXT2_SUPER_MAGIC)
goto cantfind_ext2;
//一些合法性检查
...
//计算块组描述符 个数
sbi->s_groups_count = ((le32_to_cpu(es->s_blocks_count) -
le32_to_cpu(es->s_first_data_block) - 1)
/ EXT2_BLOCKS_PER_GROUP(sb)) + 1;
db_count = (sbi->s_groups_count + EXT2_DESC_PER_BLOCK(sb) - 1) /
¦ EXT2_DESC_PER_BLOCK(sb);
sbi->s_group_desc = kmalloc_array(db_count,
¦ sizeof(struct buffer_head *),
¦ GFP_KERNEL); //分配块组描述符 bh数组
for (i = 0; i < db_count; i++) { //读取块组描述符
block = descriptor_loc(sb, logic_sb_block, i);
sbi->s_group_desc[i] = sb_bread(sb, block); //读取的 块组描述符缓冲区保存 到sbi->s_group_desc[i]
if (!sbi->s_group_desc[i]) {
for (j = 0; j < i; j++)
brelse (sbi->s_group_desc[j]);
ext2_msg(sb, KERN_ERR,
"error: unable to read group descriptors");
goto failed_mount_group_desc;
}
}
sb->s_op = &ext2_sops; //赋值超级块操作
...
root = ext2_iget(sb, EXT2_ROOT_INO); //读取根inode (ext2 根根inode号为2)
sb->s_root = d_make_root(root); //创建根dentry 并建立根inode和根dentry关系
ext2_write_super(sb); //同步超级块信息到磁盘 如挂载时间等
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
可以看到ext2_fill_super主要工作为:
1.读取磁盘上的超级块;
2.填充并关联vfs超级块;
3.读取块组描述符;
4.读取磁盘根inode并建立vfs 根inode;
5.创建根dentry关联到根inode。
下面给出ext2_fill_super之后ext2相关图解:
有了这些信息,虽然能够获得块设备上的文件系统全貌,内核也能通过已经建立好的block_device等结构访问块设备,但是用户进程不能真正意义上访问到,用户一般会通过open打开一个文件路径来访问文件,但是现在并没有关联挂载目录的路径,需要将文件系统关联到挂载点,以至于路径名查找的时候查找到挂载点后,在转向文件系统的根目录,而这需要通过do_new_mount_fc来去关联并加入全局的文件系统树中,下一篇我们将做详细讲解。

















