












面试官:呦,小伙子来的挺早啊!
Hydra:那是,不能让您等太久了啊(别废话了快开始吧,还赶着去下一场呢)。
面试官:前面两轮表现还不错,那我们今天继续说说队列中的SynchronousQueue吧。
Hydra:好的,SynchronousQueue和之前介绍过的队列相比,稍微有一些特别,必须等到队列中的元素被消费后,才能继续向其中添加新的元素,因此它也被称为无缓冲的等待队列。
我还是先写一个例子吧,创建两个线程,生产者线程putThread向SynchronousQueue中放入元素,消费者线程takeThread从中取走元素:
- SynchronousQueue<Integer> queue=new SynchronousQueue<>(true);
- Thread putThread=new Thread(()->{
- for (int i = 0; i <= 2; i++) {
- try {
- System.out.println("put thread put:"+i);
- queue.put(i);
- System.out.println("put thread put:"+i+" awake");
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- Thread takeThread=new Thread(()->{
- int j=0;
- while(j<2){
- try {
- j=queue.take();
- System.out.println("take from putThread:"+j);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- putThread.start();
- Thread.sleep(1000);
- takeThread.start();
执行上面的代码,查看结果:
- put thread put:0
- take from putThread:0
- put thread put:0 awake
- put thread put:1
- take from putThread:1
- put thread put:1 awake
- put thread put:2
- take from putThread:2
- put thread put:2 awake
可以看到,生产者线程在执行put方法后就被阻塞,直到消费者线程执行take方法对队列中的元素进行了消费,生产者线程才被唤醒,继续向下执行。简单来说运行流程是这样的:
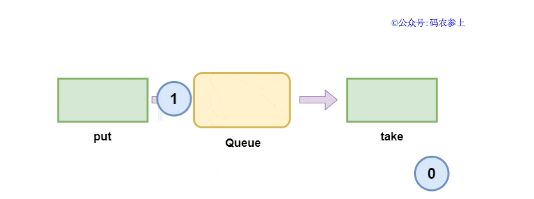
面试官:就这?应用谁不会啊,不讲讲底层原理就想蒙混过关?
Hydra:别急啊,我们先从它的构造函数说起,根据参数不同,SynchronousQueue分为公平模式和非公平模式,默认情况下为非公平模式
- public SynchronousQueue(boolean fair) {
- transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
- }
我们先来看看公平模式吧,该模式下底层使用的是TransferQueue队列,内部节点由QNode构成,定义如下:
- volatile QNode next; // next node in queue
- volatile Object item; // CAS'ed to or from null
- volatile Thread waiter; // to control park/unpark
- final boolean isData;
- QNode(Object item, boolean isData) {
- this.item = item;
- this.isData = isData;
- }
item用来存储数据,isData用来区分节点是什么类型的线程产生的,true表示是生产者,false表示是消费者,是后面用来进行节点匹配(complementary )的关键。在SynchronousQueue中匹配是一个非常重要的概念,例如一个线程先执行put产生了一个节点放入队列,另一个线程再执行take产生了一个节点,这两个不同类型的节点就可以匹配成功。
面试官:可是我看很多资料里说SynchronousQueue是一个不存储元素的阻塞队列,这点你是怎么理解的?
Hydra:通过上面节点中封装的属性,可以看出SynchronousQueue的队列中封装的节点更多针对的不是数据,而是要执行的操作,个人猜测这个说法的出发点就是队列中存储的节点更多偏向于操作这一属性。
面试官:好吧,接着往下说队列的结构吧。
Hydra:TransferQueue中主要定义的属性有下面这些:
- transient volatile QNode head;
- transient volatile QNode tail;
- transient volatile QNode cleanMe;
- TransferQueue() {
- QNode h = new QNode(null, false); // initialize to dummy node.
- head = h;
- tail = h;
- }
比较重要的有头节点head、尾节点tail、以及用于标记下一个要删除的节点的cleanMe节点。在构造函数初始化中创建了一个节点,注释中将它称为dummy node,也就是伪造的节点,它的作用类似于AQS中的头节点的作用,实际操作的节点是它的下一个节点。
要说SynchronousQueue,真是一个神奇的队列,不管你调用的是put和offer,还是take和poll,它都一概交给核心的transfer方法去处理,只不过参数不同。今天我们抛弃源码,通过画图对它进行分析,首先看一下方法的定义:
- E transfer(E e, boolean timed, long nanos);
面试官:呦呵,就一个方法?我倒要看看它是怎么区分实现的入队和出队操作…
Hydra:在方法的参数中,timed和nanos用于标识调用transfer的方法是否是能够超时退出的,而e是否为空则可以说明是生产者还是消费者调用的此方法。如果e不为null,是生产者调用,如果e为null则是消费者调用。方法的整体逻辑可以分为下面几步:
1、若队列为空,或队列中的尾节点类型和自己的类型相同,那么准备封装一个新的QNode添加到队列中。在添加新节点到队尾的过程中,并没有使用synchronized或ReentrantLock,而是通过CAS来保证线程之间的同步。
在添加新的QNode到队尾前,会首先判断之前取到的尾节点是否发生过改变,如果有改变的话那么放弃修改,进行自旋,在下一次循环中再次判断。当检查队尾节点没有发生改变后,构建新的节点QNode,并将它添加到队尾。
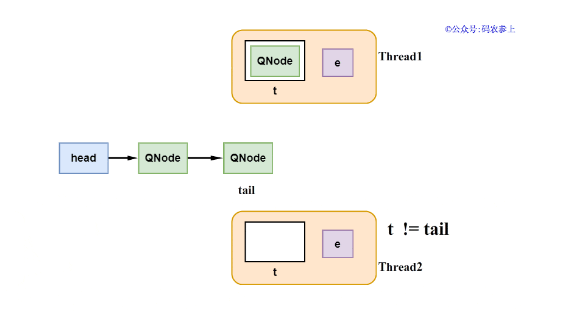
2、当新节点被添加到队尾后,会调用awaitFulfill方法,会根据传递的参数让线程进行自旋或直接挂起。方法的定义如下,参数中的timed为true时,表示这是一个有等待超时的方法。
- Object awaitFulfill(QNode s, E e, boolean timed, long nanos);
在awaitFulfill方法中会进行判断,如果新节点是head节点的下一个节点,考虑到可能很快它就会完成匹配后出队,先不将它挂起,进行一定次数的自旋,超过自旋次数的上限后再进行挂起。如果不是head节点的下一个节点,避免自旋造成的资源浪费,则直接调用park或parkNanos挂起线程。
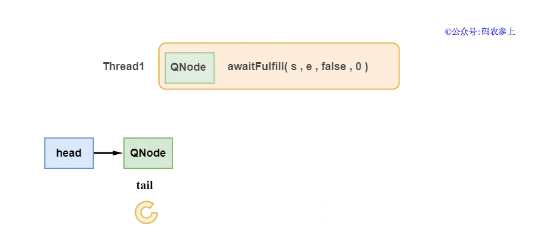
3、当挂起的线程被中断或到达超时时间,那么需要将节点从队列中进行移除,这时会执行clean()方法。如果要被删除的节点不是链表中的尾节点,那么比较简单,直接使用CAS替换前一个节点的next指针。
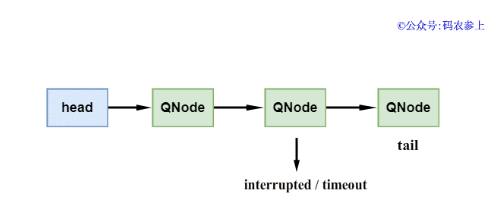
如果要删除的节点是链表中的尾节点,就会有点复杂了,因为多线程环境下可能正好有其他线程正在向尾节点后添加新的节点,这时如果直接删除尾节点的话,会造成后面节点的丢失。
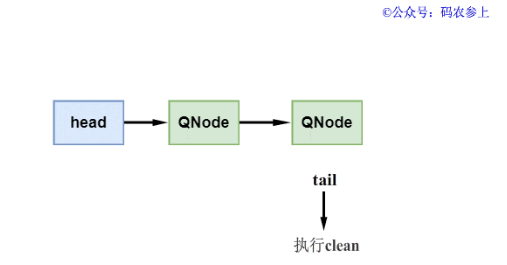
这时候就会用到TransferQueue中定义的cleanMe标记节点了,cleanMe的作用就是当要被移除的节点是队尾节点时,用它来标记队尾节点的前驱节点。具体在执行过程中,又会分为两种情况:
- cleanMe节点为null,说明队列在之前没有标记需要删除的节点。这时会使用cleanMe来标识该节点的前驱节点,标记完成后退出clean方法,当下一次执行clean方法时才会删除cleanMe的下一个节点。
- cleanMe节点不为null,那么说明之前已经标记过需要删除的节点。这时删除cleanMe的下一个节点,并清除当前cleanMe标记,并再将当前节点未修改前的前驱节点标记为cleanMe。注意,当前要被删除的节点的前驱节点不会发生改变,即使这个前驱节点已经在逻辑上从队列中删除掉了。
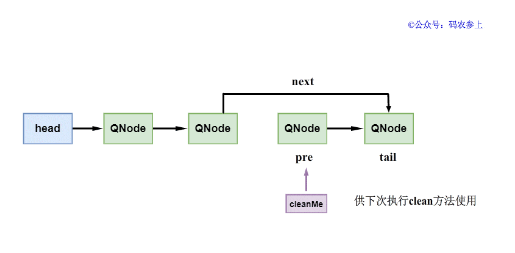
执行完成clean方法后,transfer方法会直接返回null,说明入队操作失败。
面试官:讲了这么多,入队的还都是一个类型的节点吧?
Hydra:是的,TransferQueue队列中,只会存在一个类型的节点,如果有另一个类型的节点过来,那么就会执行出队的操作了。
面试官:好吧,那你接着再说说出队方法吧。
Hydra:相对入队来说,出队的逻辑就比较简单了。因为现在使用的是公平模式,所以当队列不为空,且队列的head节点的下一个节点与当前节点匹配成功时,进行出队操作,唤醒head节点的下一个节点,进行数据的传递。
根据队列中节点类型的不同,可以分为两种情况进行分析:
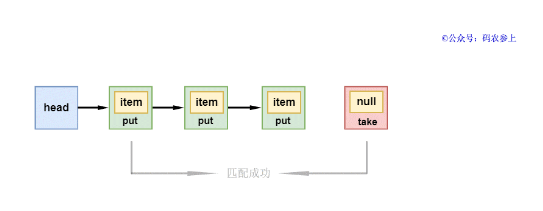
1、如果head节点的下一个节点是put类型,当前新节点是take类型。take线程取出put节点的item的值,并将其item变为null,然后推进头节点,唤醒被挂起的put线程,take线程返回item的值,完成数据的传递过程。
head节点的下一个节点被唤醒后,会推进head节点,虽然前面说过队列的head节点是一个dummy节点,并不存储数据,理论上应该将第二个节点直接移出队列,但是源码中还是将head节点出队,将原来的第二个节点变成了新的head节点。
2、同理,如果head节点的下一个节点是take类型,当前新节点是put类型。put线程会将take节点的item设为自己的数据值,然后推进头节点,并唤醒挂起的take线程,唤醒的take线程最终返回从put线程获得的item的值。
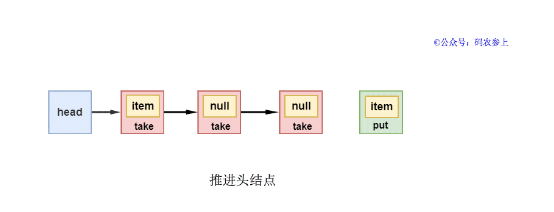
此外,在take线程唤醒后,会将自己QNode的item指针指向自己,并将waiter中保存的线程置为null,方便之后被gc回收。
面试官:也就是说,在代码中不一定非要生产者先去生产产品,也可以由消费者先到达后进行阻塞等待?
Hydra:是的,两种线程都可以先进入队列。
面试官:好了,公平模式下我是明白了,我去喝口水,给你十分钟时间,回来我们聊聊非公平模式的实现吧。
本文转载自微信公众号「码农参上」,可以通过以下二维码关注。转载本文请联系码农参上公众号。
















