【51CTO.com快译】一次我们为托管在Kubernetes集群上的一个应用程序增加了HTTP请求,然后导致了5xx错误的激增。在一个GraphQL服务器上的一个应用程序,调用大量外部的API,然后返回聚合反应。开始我们采用的应对方法是增加应用程序的副本数量,看它是否提高了性能并减少了错误。
随着我们进一步的深入研究,发现大多数的失败都与DNS解析有关。这就是我们开始在Kubernetes上深入研究DNS解析的原因。
CoreDNS指标
DNS服务器在其数据库中存储记录,并使用该数据库回答域名查询。如果DNS服务器没有此数据,它会尝试从其他DNS服务器找到解决方案。
CoreDNS成为Kubernetes 1.13+之后的默认DNS服务。如今,当使用托管Kubernetes集群或为应用程序工作负载自我管理集群时,通常调整应用程序,而没有过多的关注Kubernetes提供的服务或如何利用它们。
DNS解析是任何应用程序的基本要求,即使是在Kubernetes集群上,也要确保CoreDNS正确配置和运行。
默认情况下,集群应该始终有一个仪表板盘观察关键的CoreDNS指标。为了获得CoreDNS指标,你应该启用Prometheus插件作为CoreDNS配置的一部分。
下面是使用Prometheus插件从CoreDNS实例中启用度量集合的配置示例。
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods verified
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}以下是我们建议您在仪表板中使用的关键指标。如果你正在使用Prometheus、DataDog、Kibana等,可以从社区/提供者那里找到现成的仪表板模板。
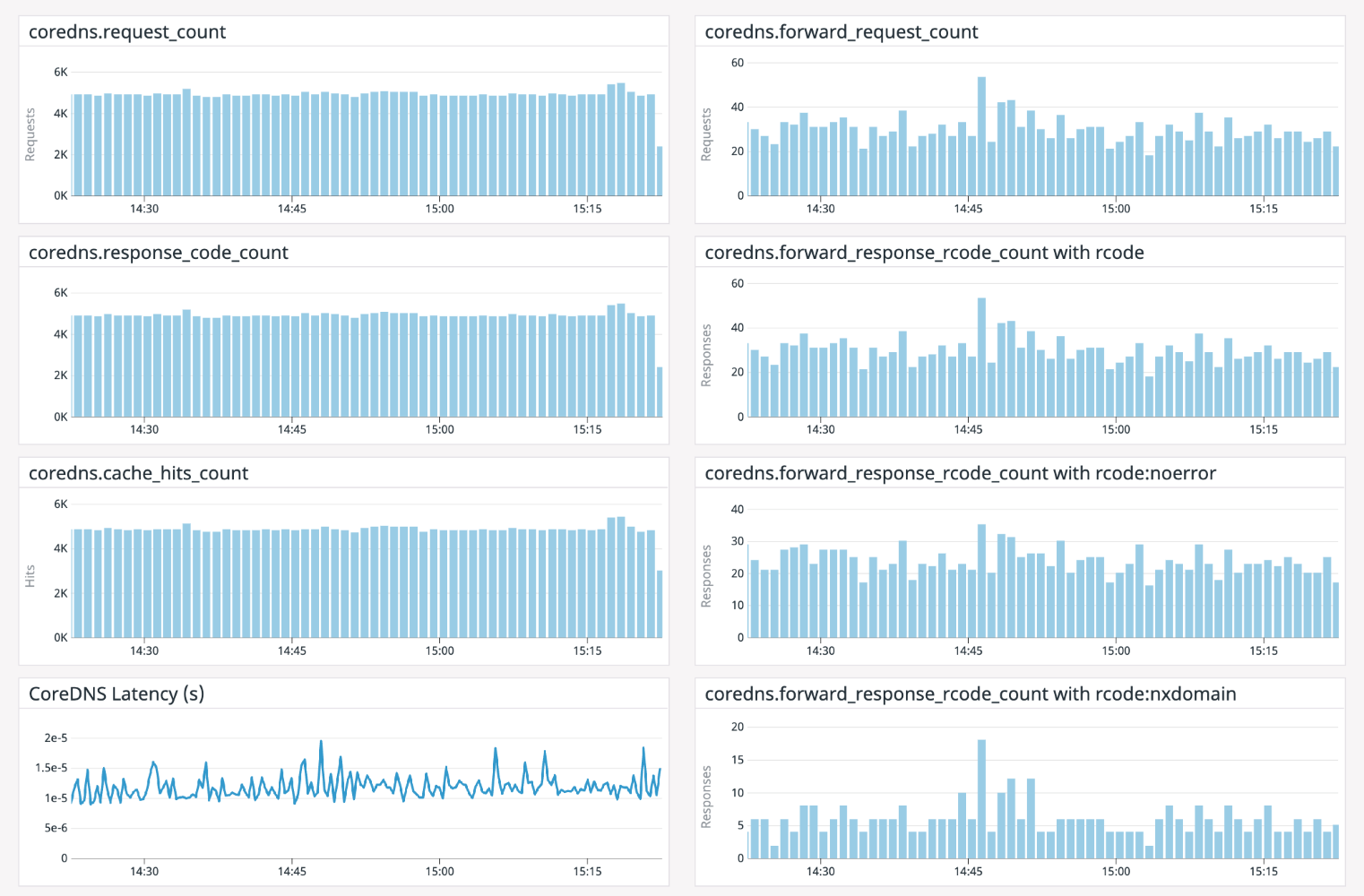
a.高速缓存命中百分比:使用CoreDNS高速缓存响应的请求的百分比;
b.DNS请求延迟:
- CoreDNS:CoreDNS处理DNS请求所花费的时间
- 上行服务器:处理转发到上行的DNS请求所花费的时间
c.转发到上行服务器的请求数;
d.请求的错误代码:
- NXDomain:不存在的域
- FormErr:DNS请求格式错误
- ServFail:服务器故障
- NoError:无错误,已成功处理请求
e.CoreDNS资源使用情况:服务器消耗的不同资源,例如内存,CPU等。
我们使用DataDog来监视特定的应用程序。下面是用DataDog构建的一个示例仪表板:
减少DNS错误
当我们开始深入研究应用程序如何向CoreDNS发出请求时,我们观察到大多数出站请求都是通过应用程序向外部API服务器发出的。
这通常是resolv.conf在应用程序部署窗格中的外观:
nameserver 10.100.0.10
search kube-namespace.svc.cluster.local svc.cluster.local cluster.local us-west-2.compute.internal
options ndots:5
Kubernetes尝试通过不同级别的DNS查找来解析FQDN。
考虑到上述DNS配置,当DNS解析器向CoreDNS服务器发送查询时,它会根据搜索路径尝试搜索域。
如果我们正在寻找一个域boktube.io,它将执行以下查询来在最后一个查询中接收成功的响应:
botkube.io.kube-namespace.svc.cluster.local <= NXDomain
botkube.io.svc.cluster.local <= NXDomain
boktube.io.cluster.local <= NXDomain
botkube.io.us-west-2.compute.internal <= NXDomain
botkube.io <= NoERROR
由于我们进行了过多的外部查找,因此我们收到了很多NXDomain DNS搜索的响应。为了优化这一点,我们在Deployment对象中定制了spec.template.spec.dnsConfig。这是改变的样子:
dnsPolicy: ClusterFirst
dnsConfig:
options:
- name: ndots
value: "1"
通过以上改变,pods上的resolve.conf也改变了。只对外部域执行搜索。
这减少了对DNS服务器的查询数量,也有助于减少应用程序的5xx错误。通过下图可以看出NXDomain响应次数的差异:
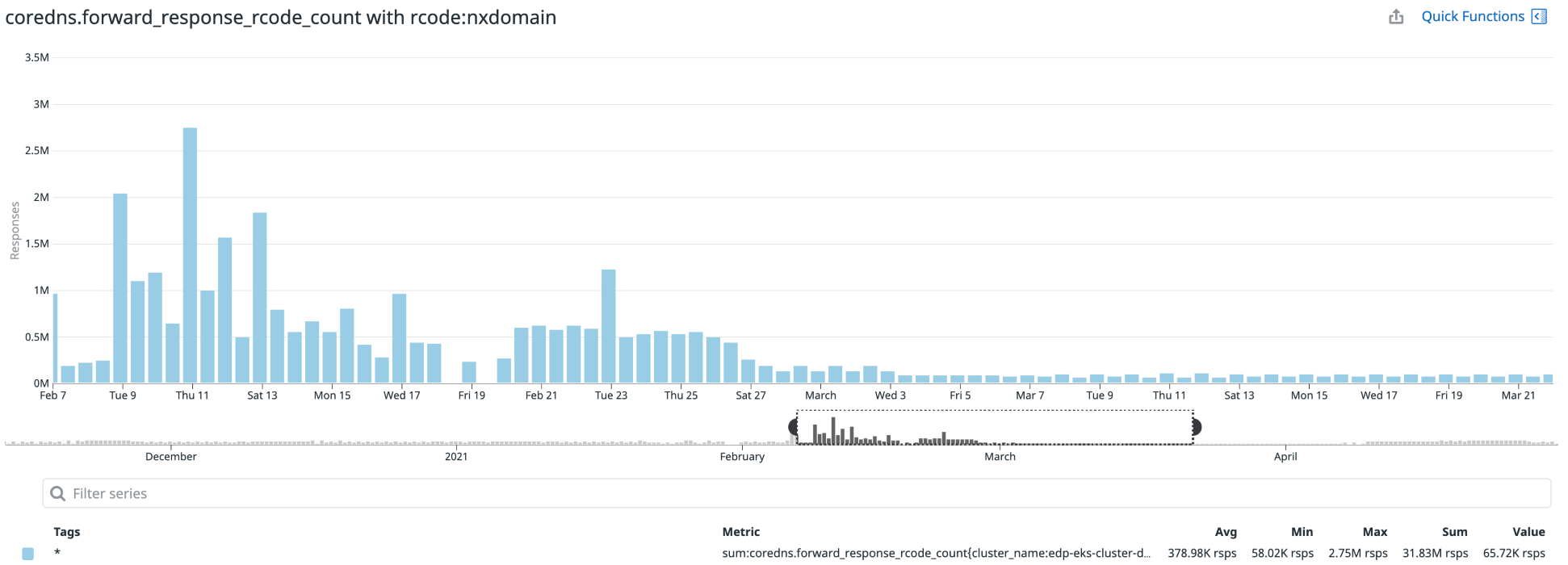
因此我们收到了许多NXDomain响应DNS搜索。为了对此进行优化,我们在Deployment对象中自定义了spec.template.spec.dnsConfig。这是变化的样子:
针对此问题的更好解决方案是在Kubernetes 1.18+中引入的[Node Level Cache](https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/)。
根据您的需要自定义CoreDNS
我们可以使用插件自定义CoreDNS。Kubernetes支持不同类型的工作负载,而标准的CoreDNS配置可能无法满足你的所有需求。CoreDNS有两个树内插件和外部插件。
您尝试解析的FQDN的类型可能会根据你在集群上运行的工作负载的类型而有所不同,例如应用程序之间是否相互通信或在Kubernetes集群外部进行交互的独立应用程序。
我们应该尝试相应地调整CoreDNS的旋钮。假设您在特定的公共/私有云中运行Kubernetes,并且大多数由DNS支持的应用程序都在同一云中。在这种情况下,CoreDNS还提供特定的云相关或通用插件,可用于扩展DNS区域记录。
决定的关键因素之一是你是否在Kubernetes集群中运行适当数量的CoreDNS实例。建议至少运行两个CoreDNS服务器实例,以更好地保证DNS请求得到服务。
你可能需要为您的集群添加额外的CoreDNS实例或配置HPA (Horizontal Pod Autoscaler),具体取决于服务的请求数量、请求的性质、在集群上运行的工作负载数量和集群的大小。
诸如被服务的请求数量、请求的性质、在集群上运行的工作负载数量以及集群大小等因素应该有助于你决定CoreDNS实例的数量。
本强调了Kubernetes中DNS请求循环的重要性。很多时候,我们会觉得这不是DNS的问题,但最终会发现确实的DNS问题,小心这个坑。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】