在人工智能发展史上,各类算法可谓层出不穷。近十几年来,深层神经网络的发展在机器学习领域取得了显著进展。通过构建分层或「深层」结构,模型能够在有监督或无监督的环境下从原始数据中学习良好的表征,这被认为是其成功的关键因素。
而深度森林,是 AI 领域重要的研究方向之一。
2017 年,周志华和冯霁等人提出了深度森林框架,这是首次尝试使用树集成来构建多层模型的工作。2018 年,周志华等人又在研究《Multi-Layered Gradient Boosting Decision Trees》中探索了多层的决策树。今年 2 月,周志华团队开源深度森林软件包 DF21:训练效率高、超参数少,在普通设备就能运行。
就在近日,TensorFlow 开源了 TensorFlow 决策森林 (TF-DF)。TF-DF 是用于训练、服务和解释决策森林模型(包括随机森林和梯度增强树)生产方面的 SOTA 算法集合。现在,你可以使用这些模型进行分类、回归和排序任务,具有 TensorFlow 和 Keras 的灵活性和可组合性。
谷歌大脑研究员、Keras之父François Chollet表示:「现在可以用Keras API训练TensorFlow决策森林了。」

对于这一开源项目,网友表示:「这非常酷!随机森林是我最喜欢的模型。」

决策森林
决策森林是一系列机器学习算法,其质量和速度可与神经网络相竞争(它比神经网络更易于使用,功能也很强大),实际上与特定类型的数据配合使用时,它们比神经网络更出色,尤其是在处理表格数据时。
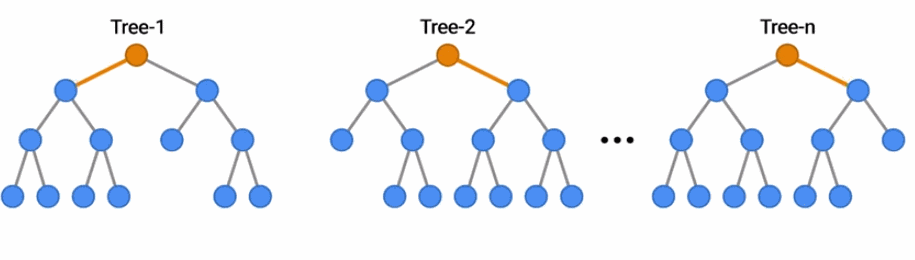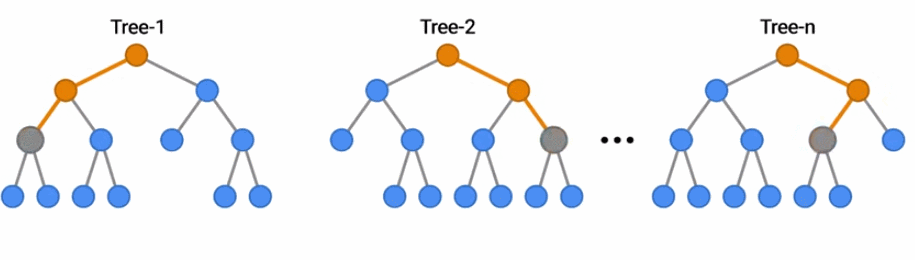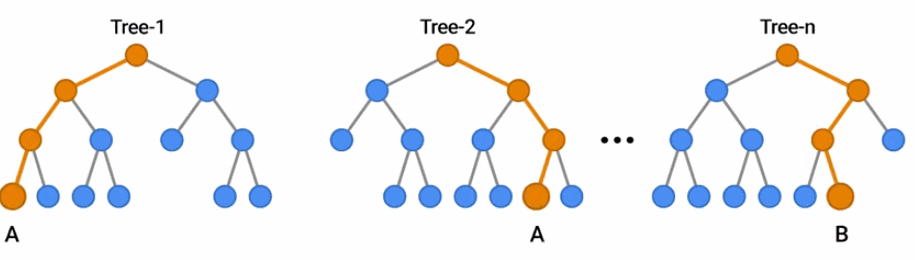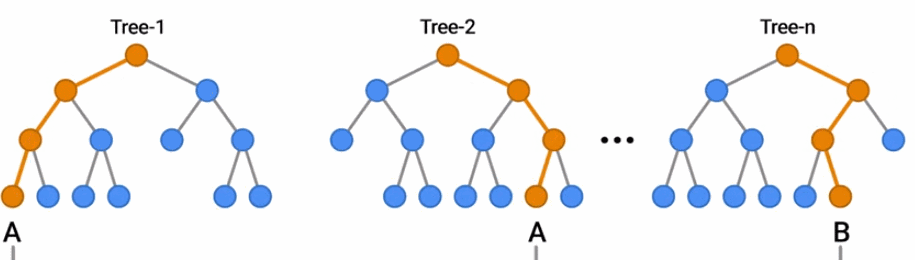
随机森林是一种流行的决策森林模型。在这里,你可以看到一群树通过投票结果对一个例子进行分类。
决策森林是由许多决策树构建的,它包括随机森林和梯度提升树等。这使得它们易于使用和理解,而且可以利用已经存在的大量可解释性工具和技术进行操作。
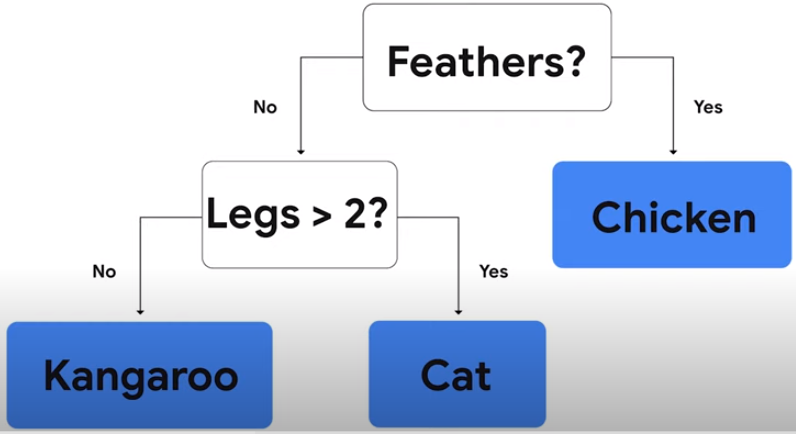
决策树是一系列仅需做出是 / 否判断的问题,使用决策树将动物分成鸡、猫、袋鼠。
TF-DF 为 TensorFlow 用户带来了模型和一套定制工具:
- 对初学者来说,开发和解释决策森林模型更容易。不需要显式地列出或预处理输入特征(因为决策森林可以自然地处理数字和分类属性)、指定体系架构(例如,通过尝试不同的层组合,就像在神经网络中一样),或者担心模型发散。一旦你的模型经过训练,你就可以直接绘制它或者用易于解释的统计数据来分析它。
- 高级用户将受益于推理时间非常快的模型(在许多情况下,每个示例的推理时间为亚微秒)。而且,这个库为模型实验和研究提供了大量的可组合性。特别是,将神经网络和决策森林相结合是很容易的。

如上图所示,只需使用一行代码就能构建模型,相比之下,动图中的下面代码是用于构建神经网络的代码。在 TensorFlow 中,决策森林和神经网络都使用 Keras。可以使用相同的 API 来实验不同类型的模型,更重要的是,可以使用相同的工具,例如 TensorFlow Serving 来部署这两种模型。
以下是 TF-DF 提供的一些功能:
- TF-DF 提供了一系列 SOTA 决策森林训练和服务算法,如随机森林、CART、(Lambda)MART、DART 等。
- 基于树的模型与各种 TensorFlow 工具、库和平台(如 TFX)更容易集成,TF-DF 库可以作为通向丰富 TensorFlow 生态系统的桥梁。
- 对于神经网络用户,你可以使用决策森林这种简单的方式开始 TensorFlow,并继续探索神经网络。
代码示例
下面进行示例展示,可以让使用者简单明了。
项目地址:https://github.com/tensorflow/decision-forests
- TF-DF 网站地址:https://www.tensorflow.org/decision_forests
- Google I/O 2021 地址:https://www.youtube.com/watch?v=5qgk9QJ4rdQ
模型训练
在数据集 Palmer's Penguins 上训练随机森林模型。目的是根据一种动物的特征来预测它的种类。该数据集包含数值和类别特性,并存储为 csv 文件。

Palmer's Penguins 数据集示例。
模型训练代码:
- # Install TensorFlow Decision Forests
- !pip install tensorflow_decision_forests
- # Load TensorFlow Decision Forests
- import tensorflow_decision_forests as tfdf
- # Load the training dataset using pandas
- import pandas
- train_df = pandas.read_csv("penguins_train.csv")
- # Convert the pandas dataframe into a TensorFlow dataset
- train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="species")
- # Train the model
- model = tfdf.keras.RandomForestModel()
- model.fit(train_ds)
请注意,代码中没有提供输入特性或超参数。这意味着,TensorFlow 决策森林将自动检测此数据集中的输入特征,并对所有超参数使用默认值。
评估模型
现在开始对模型的质量进行评估:
- # Load the testing dataset
- test_df = pandas.read_csv("penguins_test.csv")
- # Convert it to a TensorFlow dataset
- test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="species")
- # Evaluate the model
- model.compile(metrics=["accuracy"])
- print(model.evaluate(test_ds))
- # >> 0.979311
- # Note: Cross-validation would be more suited on this small dataset.
- # See also the "Out-of-bag evaluation" below.
- # Export the model to a TensorFlow SavedModel
- model.save("project/my_first_model")
带有默认超参数的随机森林模型为大多数问题提供了一个快速和良好的基线。决策森林一般会对中小尺度问题进行快速训练,与其他许多类型的模型相比,需要较少的超参数调优,并且通常会提供强大的结果。
解读模型
现在,你已经了解了所训练模型的准确率,接下来该考虑它的可解释性了。如果你希望理解和解读正被建模的现象、调试模型或者开始信任其决策,可解释性就变得非常重要了。如上所述,有大量的工具可用来解读所训练的模型。首先从 plot 开始:
- tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0)

其中一棵决策树的结构。
你可以直观地看到树结构。此外,模型统计是对 plot 的补充,统计示例包括:
- 每个特性使用了多少次?
- 模型训练的速度有多快(树的数量和时间)?
- 节点在树结构中是如何分布的(比如大多数 branch 的长度)?
这些问题的答案以及更多类似查询的答案都包含在模型概要中,并可以在模型检查器中访问。
- # Print all the available information about the model
- model.summary()
- >> Input Features (7):
- >> bill_depth_mm
- >> bill_length_mm
- >> body_mass_g>>
- ...
- >> Variable Importance:
- >> 1. "bill_length_mm" 653.000000 ################
- >> ...
- >> Out-of-bag evaluation: accuracy:0.964602 logloss:0.102378
- >> Number of trees: 300
- >> Total number of nodes: 4170
- >> ...
- # Get feature importance as a array
- model.make_inspector().variable_importances()["MEAN_DECREASE_IN_ACCURACY"]
- >> [("flipper_length_mm", 0.149),
- >> ("bill_length_mm", 0.096),
- >> ("bill_depth_mm", 0.025),
- >> ("body_mass_g", 0.018),
- >> ("island", 0.012)]
在上述示例中,模型通过默认超参数值进行训练。作为首个解决方案而言非常好,但是调整超参数可以进一步提升模型的质量。可以如下这样做:
- # List all the other available learning algorithms
- tfdf.keras.get_all_models()
- >> [tensorflow_decision_forests.keras.RandomForestModel,
- >> tensorflow_decision_forests.keras.GradientBoostedTreesModel,
- >> tensorflow_decision_forests.keras.CartModel]
- # Display the hyper-parameters of the Gradient Boosted Trees model
- ? tfdf.keras.GradientBoostedTreesModel
- >> A GBT (Gradient Boosted [Decision] Tree) is a set of shallow decision trees trained sequentially. Each tree is trained to predict and then "correct" for the errors of the previously trained trees (more precisely each tree predicts the gradient of the loss relative to the model output)..
- ...
- Attributes:
- num_trees: num_trees: Maximum number of decision trees. The effective number of trained trees can be smaller if early stopping is enabled. Default: 300.
- max_depth: Maximum depth of the tree. `max_depth=1` means that all trees will be roots. Negative values are ignored. Default: 6.
- ...
- # Create another model with specified hyper-parameters
- model = tfdf.keras.GradientBoostedTreesModel(
- num_trees=500,
- growing_strategy="BEST_FIRST_GLOBAL",
- max_depth=8,
- split_axis="SPARSE_OBLIQUE"
- ,)
- # Evaluate the model
- model.compile(metrics=["accuracy"])
- print(model.evaluate(test_ds))#
- >> 0.986851