












本文转载自微信公众号「程序员小灰」,作者小灰。转载本文请联系程序员小灰公众号。




首先,我们来讲一讲什么是数据库。
作为程序员,我们写的大多数商业项目,往往都需要用到大量的数据。计算机的内存,可以实现数据的快速存储和访问。
但是,内存的空间是有限的,也无法长期保存有用的数据。对于那些大量的,需要长期使用的数据,我们需要对它们进行持久的、规范化的存储,于是就有了数据库(DataBase)。
市场上常用的数据库有很多种,包括像MySQL、Oracle这样的关系型数据库,也包括Redis,HBase这样的非关系型数据库。
无论是哪一种数据库,它们所存储的都是结构化数据,主要应用的领域是联机事务处理(OLTP),也就是我们程序员所熟悉的增删改查业务。

满足了业务需求,数据库当中的数据不断积累,变得越来越丰富。这时候人们发现,这些数据不但可以支撑业务的运行,也可以用于生成商业报表,进行数据分析,提供有价值的决策参考。这些数据分析和生成报表的处理操作,被称为联机分析处理(OLAP)。
但是,传统数据库擅长的是快速地对小规模数据进行增删改查,并不擅长大规模数据的快速读取。
于是,人们发明了一种全新的数据存储方式,并把原本分散在不同项目当中的业务数据进行抽取、清洗、转换、加载,最终汇总成为一系列面向主题的数据集合,按照全新的方式进行存储。
这种全新的存储方式,被称为数据仓库(Data Warehouse);把数据进行抽取、清洗、转换、加载的过程,被称为ETL(Extract Transform Load)。
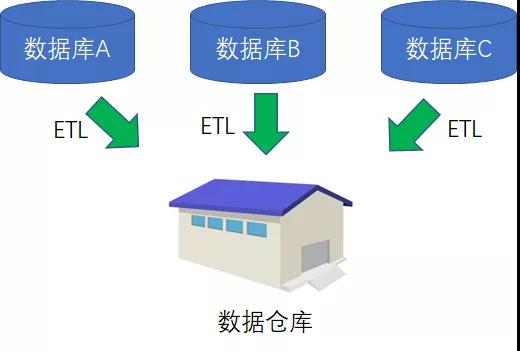
数据仓库当中存储的数据,同样是结构化数据。

数据库用于业务处理,数据仓库用于数据分析,一时间大家都使用得十分愉快。
但是,随着大数据和机器学习技术的不断发展,人们发现不仅是结构化的数据具有分析价值,许多非结构化的数据,例如用户日志、电子邮件、PDF等等,同样具有可观的分析和学习价值。
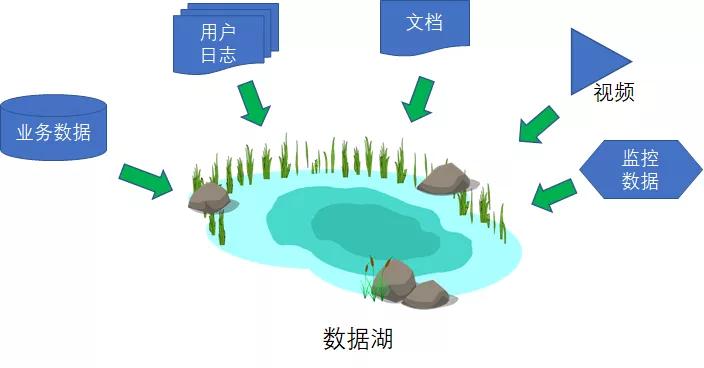
这些五花八门的数据,如果统一按照ETL的方式进行加工处理,实在是不太现实,那么索性把它们按照原始格式汇总在一起吧。这样汇总起来的庞大集合,被存储在了数据湖(Data Lake)当中。
数据湖当中的数据可谓是包罗万象:
结构化的,有各种关系型数据库的行和列。
半结构化的,有JSON、XML、CSV。
非结构化的,有电子邮件、PDF、各种文档。
甚至还有杂七杂八的二进制文件,比如图片、视频、音频。
通过数据湖这个统一的数据管理节点,企业可以利用更加丰富多样的数据,为商业智能、机器学习等方向赋能。


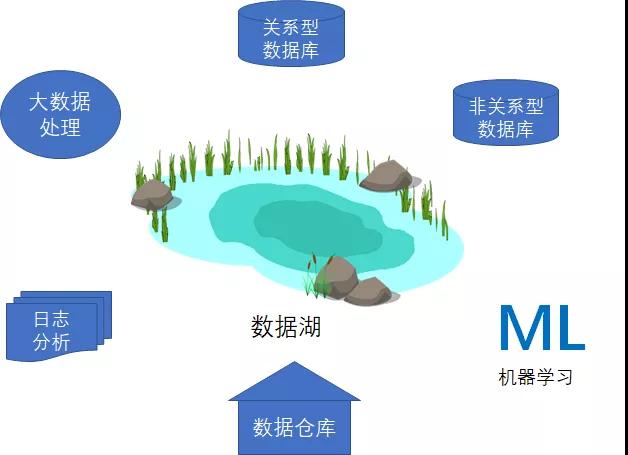
在现实的企业项目当中,所需要的不只是统一存储的数据湖,也需要各种各样专门构建的存储方案,由此为特定应用场景提供必要的性能、规模与成本优势。
比如,我们仍然需要数据仓库,适合针对结构化数据通过复杂查询快速获取结果;我们需要Lucene或Elastic Search这样的全文检索引擎,从而实现快速搜索并分析日志数据,借此监控生产系统的运行状态。
通过这些多样的存储方案,我们可以高效低成本地进行数据分析、机器学习、大数据处理、日志分析等工作。
为了从数据湖及专门构建的存储中获取最大收益,企业希望在不同系统之间轻松移动数据。比如有些情况下,客户希望将数据湖当中的部分数据移至数据仓库、日志系统等节点。我们将这种情况,归纳为由内向外的数据移动操作。
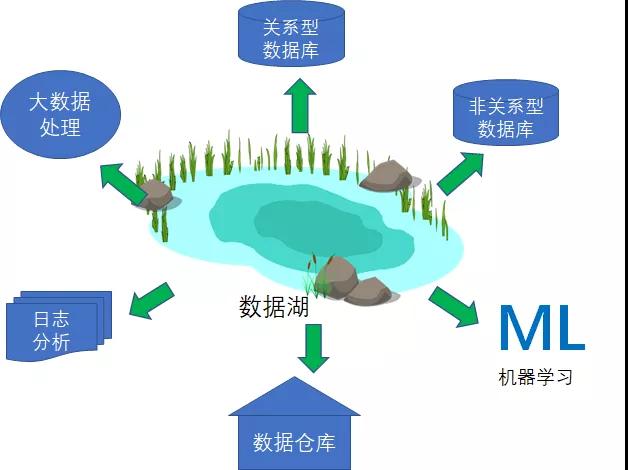
还有些情况下,企业希望将业务数据从关系型数据库和非关系型数据库移动到数据湖内。我们将这种情况,归纳为由外向内的数据移动操作。
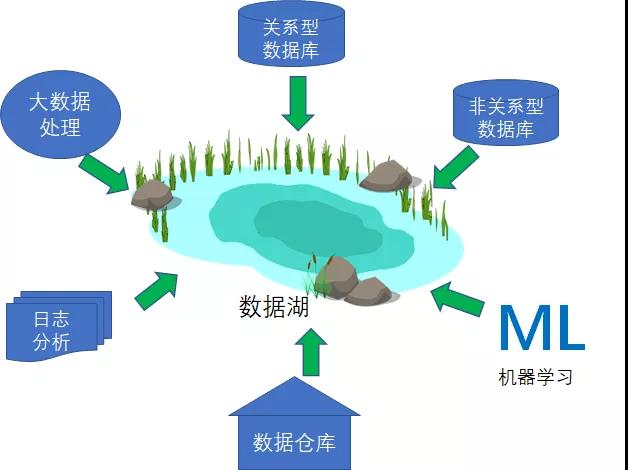
最后,企业还可能要求将数据在不同的专用数据存储方案之间往来移动,比如将数据仓库内的数据提供给机器学习系统。我们将这种情况,归纳为围绕边界的数据移动操作。
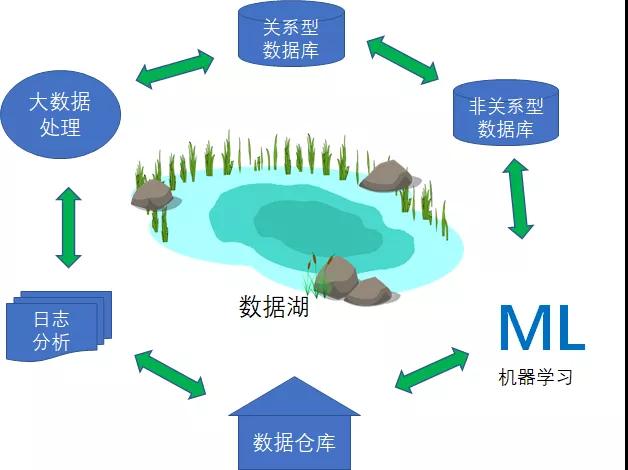




1.快速构建起可扩展的数据湖。
2.丰富而且功能强大的专门构建的数据服务集合,这些数据服务可以为交互式仪表板与日志分析等提供必要的性能支持。
3.在数据湖及各专门构建的数据服务之间实现数据的无缝化移动。
4.通过统一方式加以保护、监控与管理,保证数据访问活动的合规性。
5.以低成本方式扩展系统,保证不对性能产生负面影响。
我们将这样一种强大的数据湖及其配套的专用构建数据服务体系,称为智能湖仓(Lake House)架构。






















