本文转载自微信公众号「小菜学编程」,作者fasionchan。转载本文请联系小菜学编程公众号。
Python 内部采用 引用计数法 ,为每个对象维护引用次数,并据此回收不再需要的垃圾对象。由于引用计数法存在重大缺陷,循环引用时有内存泄露风险,因此 Python 还采用 标记清除法 来回收存在循环引用的垃圾对象。此外,为了提高垃圾回收( GC )效率,Python 还引入了 分代回收机制 。
对象跟踪
将程序内部对象跟踪起来,是实现垃圾回收的第一步。那么,是不是程序创建的所有对象都需要跟踪呢?
一个对象是否需要跟踪,取决于它会不会形成循环引用。按照引用特征,Python 对象可以分为两类:
- 内向型对象 ,例如 int 、float 、 str 等,这类对象不会引用其他对象,因此无法形成循环引用,无须跟踪;
- 外向型对象 ,例如 tuple 、 list 、 dict 等容器对象,以及函数、类实例等复杂对象,这类对象一般都会引用其他对象,存在形成循环引用的风险,因此是垃圾回收算法关注的重点;
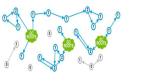
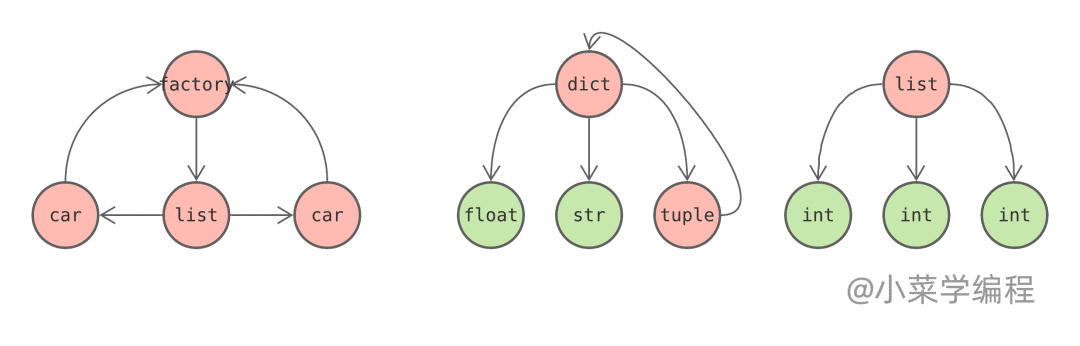
这是一个典型的例子,橘红色外向型对象存在循环引用的可能性,需要跟踪;而绿色内向型对象在引用关系图中只能作为叶子节点存在,无法形成任何环状,因此无需跟踪:
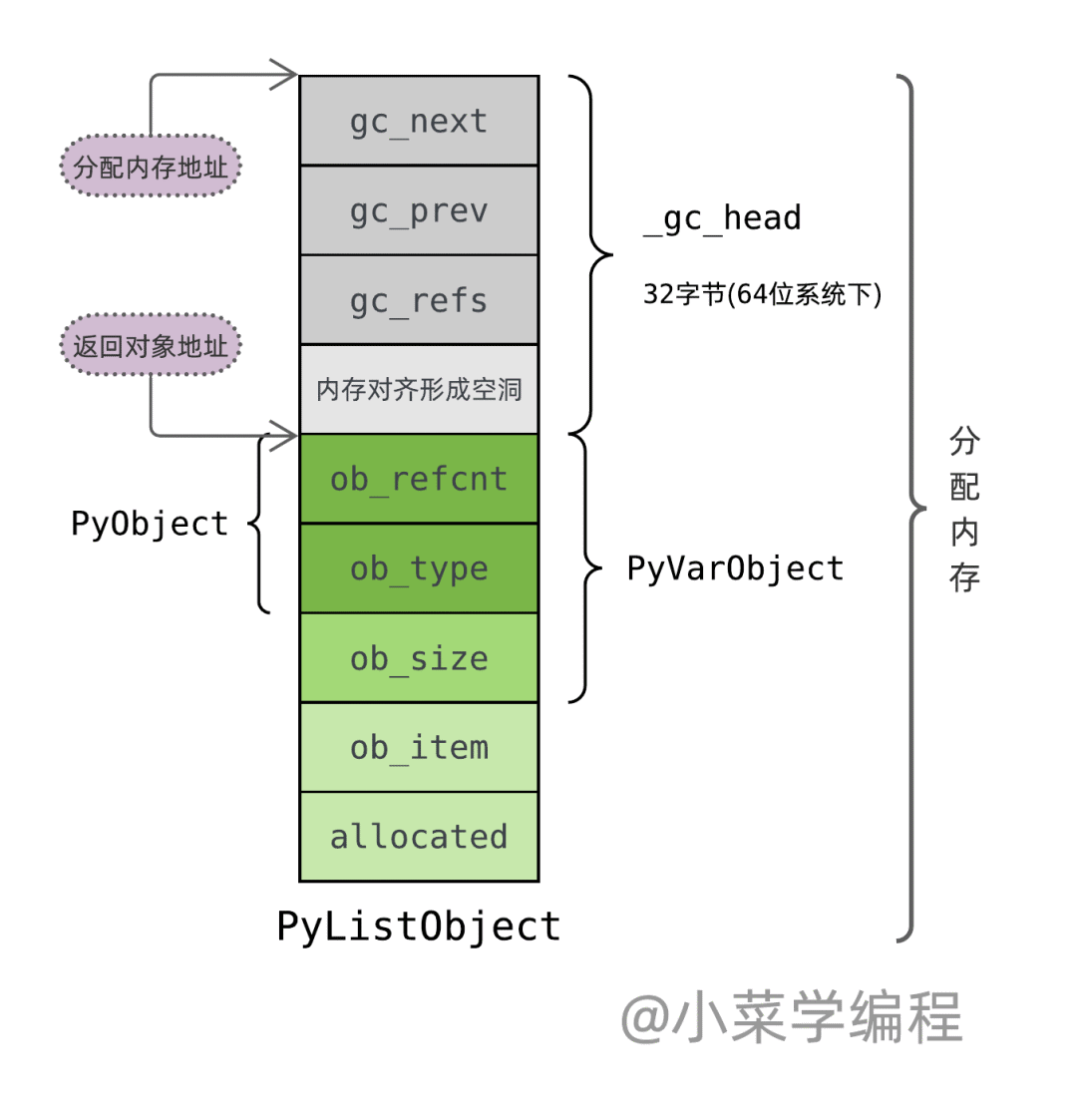
Python 为外向型对象分配内存时,调用位于 Modules/gcmodule.c 源文件的 _PyObject_GC_Alloc 函数。该函数在对象头部之前预留了一些内存空间,以便垃圾回收模块用 链表 将它们跟踪起来。预留的内存空间是一个 _gc_head 结构体,它定义于 Include/objimpl.h 头文件:
- typedef union _gc_head {
- struct {
- union _gc_head *gc_next;
- union _gc_head *gc_prev;
- Py_ssize_t gc_refs;
- } gc;
- long double dummy; /* force worst-case alignment */
- // malloc returns memory block aligned for any built-in types and
- // long double is the largest standard C type.
- // On amd64 linux, long double requires 16 byte alignment.
- // See bpo-27987 for more discussion.
- } PyGC_Head;
- gc_next ,链表后向指针,指向后一个被跟踪的对象;
- gc_prev ,链表前向指针,指向前一个被跟踪的对象;
- gc_refs ,对象引用计数副本,在标记清除算法中使用;
- dummy ,内存对齐用,以 64 位系统为例,确保 _gc_head 结构体大小是 16 字节的整数倍,结构体地址以 16 字节为单位对齐;
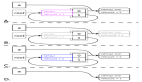
以 list 对象为例,_PyObject_GC_Alloc 函数在 PyListObject 结构体基础上加上 _gc_head 结构体来申请内存,但只返回 PyListObject 的地址作为对象地址,而不是整块内存的首地址:
就这样,借助 gc_next 和 gc_prev 指针,Python 将需要跟踪的对象一个接一个组织成 双向链表 :
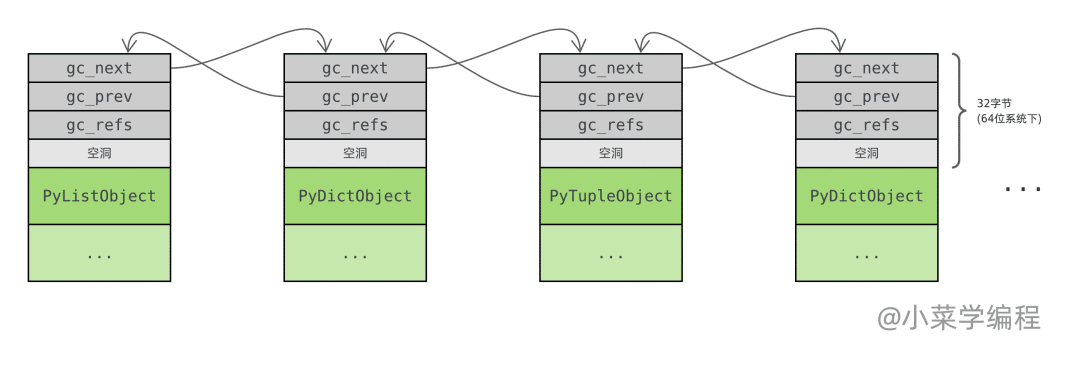
这个链表也被称为 可收集 ( collectable )对象链表,Python 将从这个链表中收集并回收垃圾对象。
分代回收机制
Python 程序启动后,内部可能会创建大量对象。如果每次执行标记清除法时,都需要遍历所有对象,多半会影响程序性能。为此,Python 引入分代回收机制——将对象分为若干“代”( generation ),每次只处理某个代中的对象,因此 GC 卡顿时间更短。
那么,按什么标准划分对象呢?是否随机将一个对象划分到某个代即可呢?答案是否定的。实际上,对象分代里头也是有不少学问的,好的划分标准可显著提升垃圾回收的效率。
考察对象的生命周期,可以发现一个显著特征:一个对象存活的时间越长,它下一刻被释放的概率就越低。我们应该也有这样的亲身体会:经常在程序中创建一些临时对象,用完即刻释放;而定义为全局变量的对象则极少释放。
因此,根据对象存活时间,对它们进行划分就是一个不错的选择。对象存活时间越长,它们被释放的概率越低,可以适当降低回收频率;相反,对象存活时间越短,它们被释放的概率越高,可以适当提高回收频率。
| 对象存活时间 | 释放概率 | 回收频率 |
|---|---|---|
| 长 | 低 | 低 |
| 短 | 高 | 高 |
Python 内部根据对象存活时间,将对象分为 3 代(见 Include/internal/mem.h ):
- #define NUM_GENERATIONS 3
每个代都由一个 gc_generation 结构体来维护,它同样定义于 Include/internal/mem.h 头文件:
- struct gc_generation {
- PyGC_Head head;
- int threshold; /* collection threshold */
- int count; /* count of allocations or collections of younger
- generations */
- };
- head ,可收集对象链表头部,代中的对象通过该链表维护;
- threshold ,仅当 count 超过本阀值时,Python 垃圾回收操作才会扫描本代对象;
- count ,计数器,不同代统计项目不一样;
Python 虚拟机运行时状态由 Include/internal/pystate.h 中的 pyruntimestate 结构体表示,它内部有一个 _gc_runtime_state ( Include/internal/mem.h )结构体,保存 GC 状态信息,包括 3 个对象代。这 3 个代,在 GC 模块( Modules/gcmodule.c ) _PyGC_Initialize 函数中初始化:
- struct gc_generation generations[NUM_GENERATIONS] = {
- /* PyGC_Head, threshold, count */
- {{{_GEN_HEAD(0), _GEN_HEAD(0), 0}}, 700, 0},
- {{{_GEN_HEAD(1), _GEN_HEAD(1), 0}}, 10, 0},
- {{{_GEN_HEAD(2), _GEN_HEAD(2), 0}}, 10, 0},
- };
为方便讨论,我们将这 3 个代分别称为:初生代、中生代 以及 老生代。当这 3 个代初始化完毕后,对应的 gc_generation 数组大概是这样的:
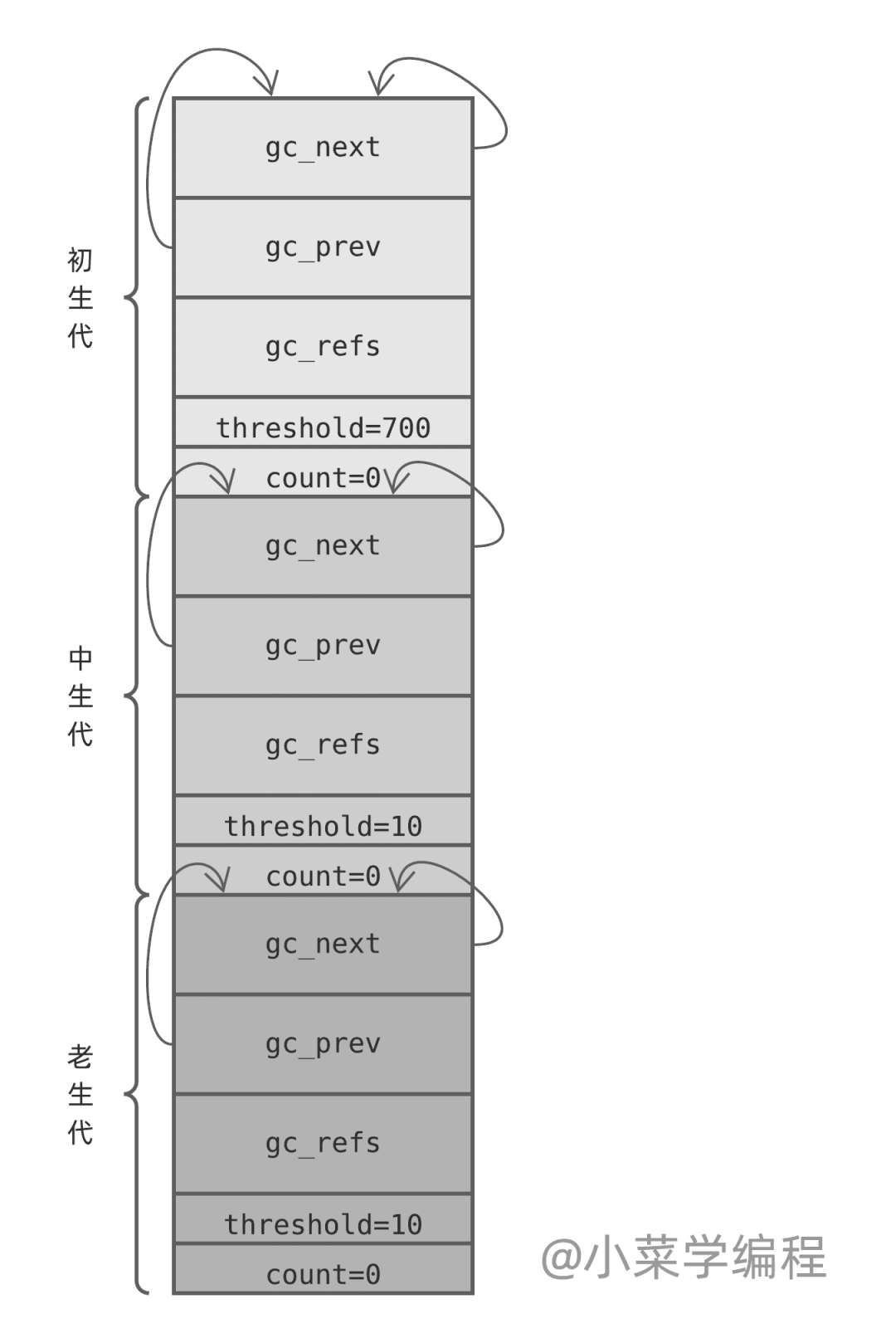
每个 gc_generation 结构体链表头节点都指向自己,换句话说每个可收集对象链表一开始都是空的;计数器字段 count 都被初始化为 0 ;而阀值字段 threshold 则有各自的策略。这些策略如何理解呢?
Python 调用 _PyObject_GC_Alloc 为需要跟踪的对象分配内存时,该函数将初生代 count 计数器加一,随后对象将接入初生代对象链表;当 Python 调用 PyObject_GC_Del 释放垃圾对象内存时,该函数将初生代 count 计数器减一;_PyObject_GC_Alloc 自增 count 后如果超过阀值( 700 ),将调用 collect_generations 执行一次垃圾回收( GC )。
collect_generations 函数从老生代开始,逐个遍历每个生代,找出需要执行回收操作( count>threshold )的最老生代。随后调用 collect_with_callback 函数开始回收该生代,而该函数最终调用 collect 函数。
collect 函数处理某个生代时,先将比它年轻的生代计数器 count 重置为 0 ;然后将它们的对象链表移除,与自己的拼接在一起后执行 GC 算法(本文后半部分介绍);最后,将下一个生代计数器加一。
- 系统每新增 701 个需要 GC 的对象,Python 就执行一次 GC 操作;
- 每次 GC 操作需要处理的生代可能是不同的,由 count 和 threshold 共同决定;
- 某个生代需要执行 GC ( count>hreshold ),在它前面的所有年轻生代也同时执行 GC ;
- 对多个代执行 GC ,Python 将它们的对象链表拼接在一起,一次性处理;
- GC 执行完毕后,count 清零,而后一个生代 count 加一;
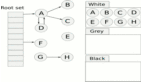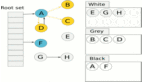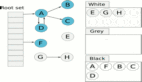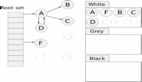
下面是一个简单的例子:初生代触发 GC 操作,Python 执行 collect_generations 函数。它找出了达到阀值的最老生代是中生代,因此调用 collection_with_callback(1) ,1 是中生代在数组中的下标。
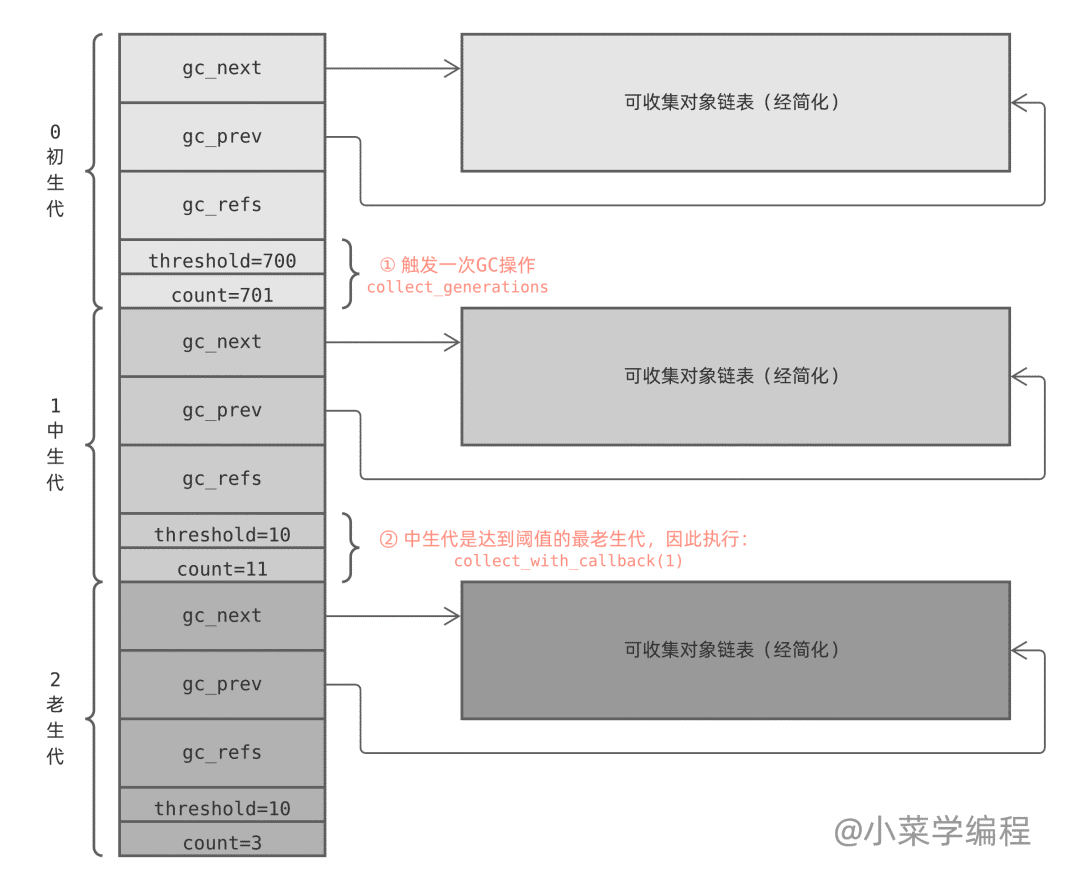
collection_with_callback(1) 最终执调用 collect(1) ,它先将后一个生代计数器加一;然后将本生代以及前面所有年轻生代计数器重置为零;最后调用 gc_list_merge 将这几个可回收对象链表合并在一起:
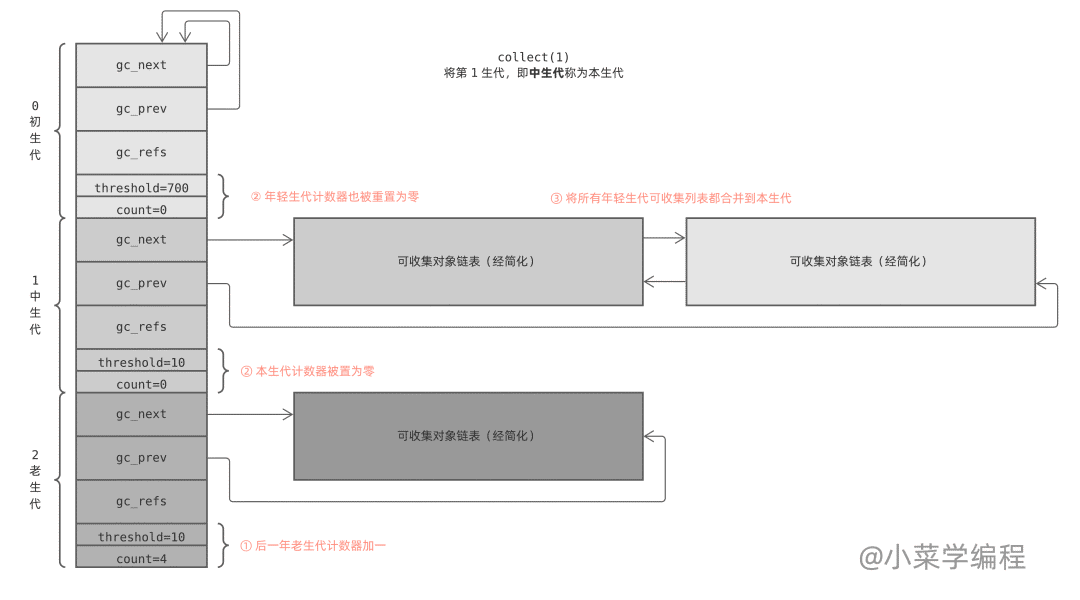
最后,collect 函数执行标记清除算法,对合并后的链表进行垃圾回收,具体细节在本文后半部分展开介绍。
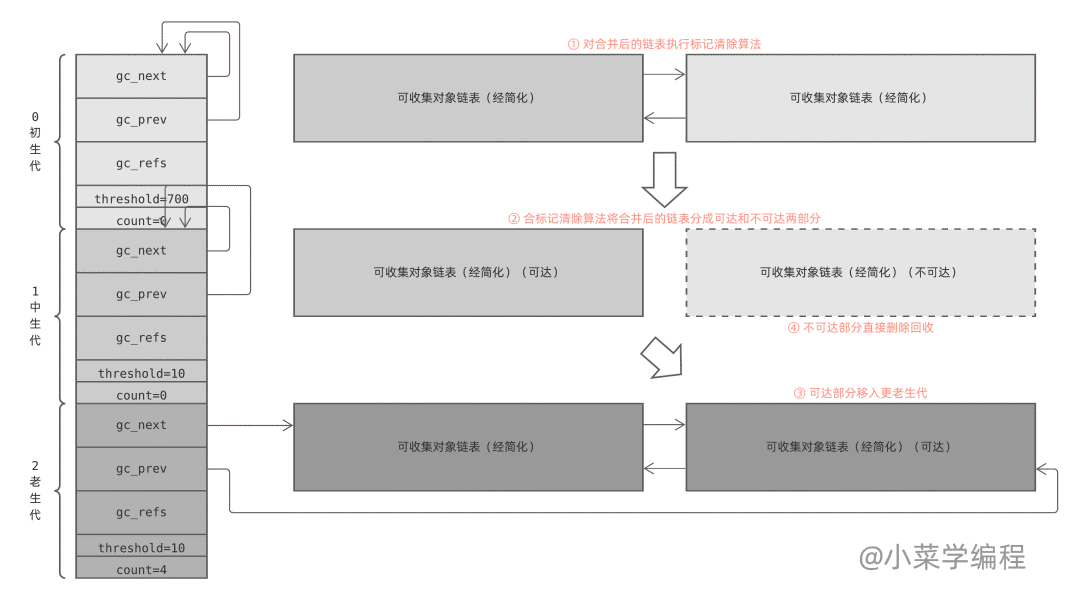
这就是分代回收机制的全部秘密,它看似复杂,但只需略加总结就可以得到几条直白的策略:
- 每新增 701 个需要 GC 的对象,触发一次新生代 GC ;
- 每执行 11 次新生代 GC ,触发一次中生代 GC ;
- 每执行 11 次中生代 GC ,触发一次老生代 GC (老生代 GC 还受其他策略影响,频率更低);
- 执行某个生代 GC 前,年轻生代对象链表也移入该代,一起 GC ;
- 一个对象创建后,随着时间推移将被逐步移入老生代,回收频率逐渐降低;
由于篇幅关系,分代回收部分代码无法逐行解释,请对照图示阅读相关重点函数,应该不难理解。
现在,我们对 Python 垃圾回收机制有了框架上的把握,但对检测垃圾对象的方法还知之甚少。垃圾对象识别是垃圾回收工作的重中之重,Python 是如何解决这一关键问题的呢?