













为什么使用缓存
在高并发请求时,我们会频繁提到使用缓存技术,最直接的原因是,磁盘IO及网络开销是直接请求内存IO的千百上千倍
做个简单计算,如果我们需要某个数据,该数据从数据库磁盘读出来需要0.0045S,经过网络请求传输需要0.0005S,那么每个请求完成最少需要0.005S,该数据服务器每秒最多只能响应200个请求,而如果该数据存于本机内存里,读出来只需要100us,那么每秒能够响应10000个请求。通过将数据存储到离CPU更近的未位置,减少数据传输时间,提高处理效率,这就是缓存的意义。
什么场景下适合使用缓存
-
读密集型的应用
-
存在热数据的应用
-
对响应时效要求高的应用
-
对一致性要求不严格的场景
-
需要实现分布式锁的时候
什么场景下不适合使用缓存
-
对一致性要求严格的场景
-
更新频繁,更新数据频率过高的场景,频繁同步缓存中的数据所花费的代价可能比不使用缓存的代价还要高
-
读少的场景,对于读少的系统而言,使用缓存就完全没有意义了,比较使用缓存是为了读取数据更高效
缓存收益成本对比
收益
-
加速读写。因为缓存通常都是全内存的系统,通过缓存的使用可以有效提高用户的访问速度同时优化用户体验。
-
降低后端负载。通过添加缓存,如果程序没有什么问题,在命中率还可以的情况下,可以帮助后端减少访问量和复杂计算,很大程度降低了后端的负载。
成本
-
数据不一致性。无论设计做的多么好,缓存数据与真实数据源一定存在着一定时间窗口的数据不一致性
-
代码维护成本。有缓存后,代码就会在原数据源基础上加入缓存的相关代码,例如原来只是一些sql,现在要加入缓存,必然增加代码维护成本。
-
架构复杂度。有缓存后,需要专门的管理人员来维护主从缓存系统,同时也增加了架构的复杂度和维护成本。
高并发场景下带来的常见问题
在高并发场景下,缓存主要会带来下面几个问题:
1.缓存一致性
2.缓存并发(缓存击穿)
3.缓存穿透
4.缓存雪崩(缓存失效)
打个比方,你是个很有钱的人,开满了百度云,腾讯视频各种杂七杂八的会员,但是你就是没有netflix的会员,然后你把这些账号和密码发布到一个你自己做的网站上,然后你有一个朋友每过十秒钟就查询你的网站,发现你的网站没有Netflix的会员后打电话向你要。你就相当于是个数据库,网站就是Redis。这就是缓存穿透。
大家都喜欢看腾讯视频上 周星驰的《喜剧之王》 ,但是你的会员突然到期了,大家在你的网站上看不到腾讯视频的账号,纷纷打电话向你询问,这就是缓存击穿
你的各种会员突然同一时间都失效了,那这就是缓存雪崩了。
下面一一介绍!
缓存一致性问题
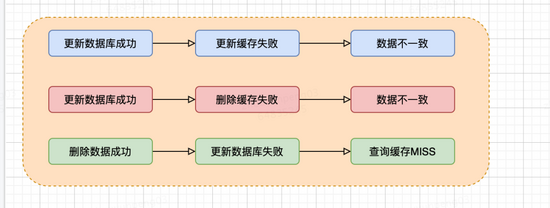
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,而且需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
下图情况都会导致数据一致性问题
缓存击穿问题
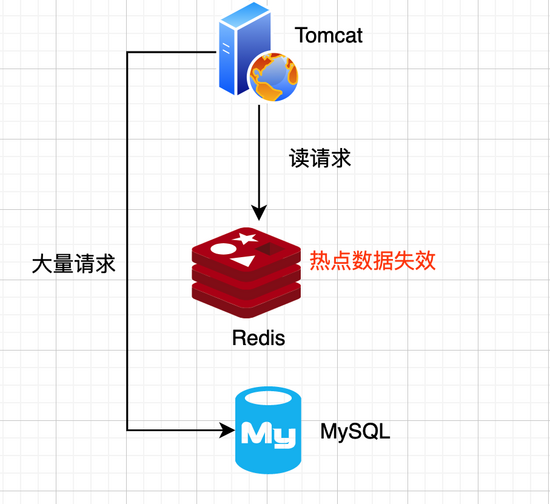
对于一些设置了过期时间的key,可能这些key会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑缓存被“击穿”的问题,和缓存雪崩的区别在于这里针对某一key缓存,而缓存雪崩则是很多key。
如图所示:
解决方案:
业界比较常用的做法,是使用mutex(互斥锁)。
1.使用互斥锁(mutex key)
该方案思路比较简单,就是只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据就可以
如果是单机可以用synchronized或者lock来处理,如果是分布式环境可以用分布式锁(redis的setnx, zookeeper的添加节点操作)
redis伪代码如下:
public String get(String key) {
String value = storeClient.get(key);
StoreKey key_mutex = new MutexStoreKey(key);
if (value == null) {//代表缓存值过期
//设置2min的超时,防止删除缓存操作失败的时候,下次缓存过期一直不能获取DB数据
if (storeClient.setnx(key_mutex, 1, 2 * 60)) { //代表设置成功
value = db.get(key);
storeClient.set(key, value, 3 * 3600);
storeClient.delete(key_mutex);
} else {
sleep(1000); //这个时候代表同时候的其他线程已经获取DB数据并回设到缓存了,这时候重试获取缓存值即可
return get(key); //重试
}
}
return value;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
2.“提前”使用互斥锁(mutex key)
即在value内部设置1个超时值(timeout1),timeout1比实际的redis timeout(timeout2)小。
当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
方案2和方案1的区别在于,如果缓存有数据,但是已经过期,会提前使用互斥锁,查询DB最新数据再缓存起来
伪代码如下,注意代码else里面的逻辑。
public String get(String key) {
MutexDTO value = storeClient.get(key);
StoreKey key_mutex = new MutexStoreKey(key);
if (value == null) {
if (storeClient.setnx(key_mutex, 3 * 60 * 1000)) {
value = db.get(key);
storeClient.set(key, value);
storeClient.delete(key_mutex);
} else {
sleep(50);
get(key);
}
} else {
if (value.getTimeout() <= System.currentTimeMillis()) {
if (storeClient.setnx(key_mutex, 3 * 60 * 1000)) {
value.setTimeout(value.getTimeout() + 3 * 60 * 1000);
storeClient.set(key, value, 3 * 3600 * 2);
value = db.get(key);//获取最近DB更新数据
value.setTimeout(value.getTimeout() + 3 * 60 * 1000);
storeClient.set(key, value, 3 * 3600 * 2);
storeClient.delete(key_mutex);
} else {
sleep(50);
get(key);
}
}
}
return value.getValue();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
3.缓存”永不过期“
这里的“永远不过期”包含两层意思:
-
从redis上看,不设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
-
从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期。
public String get(String key) {
MutexDTO mutexDTO = storeClient.get(key);
String value = mutexDTO.getValue();
if (mutexDTO.getTimeout() <= System.currentTimeMillis()) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();// 异步更新后台异常执行
singleThreadExecutor.execute(new Runnable() {
public void run() {
StoreKey mutexKey = new MutexStoreKey(key);
if (storeClient.setnx(mutexKey, "1")) {
storeClient.expire(mutexKey, 3 * 60);
String dbValue = db.get(key);
storeClient.set(key, dbValue);
storeClient.delete(mutexKey);
}
}
});
}
return value;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
三种方法如下比较:
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 使用互斥锁 | 1.思路简单2.保证一致性 | 1. 代码复杂度增大2. 存在死锁的风险 |
| 提前使用互斥锁 | 1. 保证一致性 | 同上 |
| 缓存永不过期 | 1. 异步构建缓存,不会阻塞线程池 | 1. 不保证一致性。2. 代码复杂度增大(每个value都要维护一个timekey)。3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
缓存穿透问题
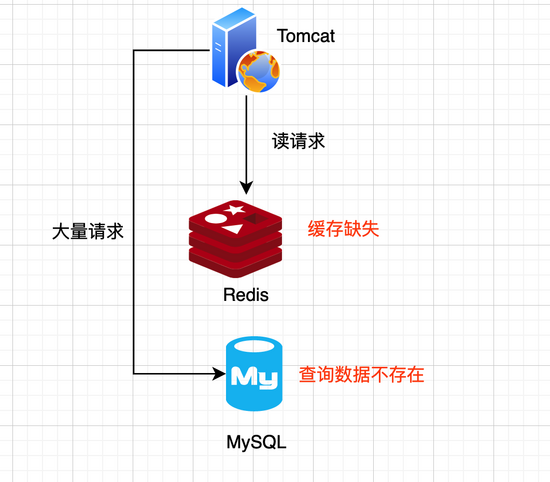
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,要是DB无法承受瞬间流量冲击,DB可能就挂了。
如图所示:
解决方案:
有多种方法可以有效解决缓存穿透问题,一种比较简单粗暴的方法采用缓存空数据,如果一个查询返回的数据为空(数据库中不存在该数据),仍然把这个空结果进行缓存(过期时间一般较短)。
另一种方法则是采用常用的布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
1.缓存空数据
当Client请求MISS后,仍然将空对象保留到Cache中(可能是保留一段时间,具体问题具体分析),下次新的Request(同一个key)将会从Cache中获取到数据,保护了后端的DB。伪代码如下:
public class CacheNullService {
private Cache cache = new Cache();
private Storage storage = new Storage();
/**
* 模拟正常模式
* @param key
* @return
*/
public String getNormal(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
// 如果存储数据不为空,将存储的值设置到缓存
if (StringUtils.isNotBlank(storageValue)) {
cache.set(key, storageValue);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
/**
* 模拟防穿透模式
* @param key
* @return
*/
public String getPassThrough(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (StringUtils.isBlank(storageValue)) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
2.布隆过滤器
BloomFilter 是一个非常有意思的数据结构,不仅仅可以挡住非法 key 攻击,还可以低成本、高性能地对海量数据进行判断,比如一个系统有数亿用户和百亿级新闻 feed,就可以用 BloomFilter 来判断某个用户是否阅读某条新闻 feed
在访问所有资源(cache, DB)之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。算法的简单图解如下:
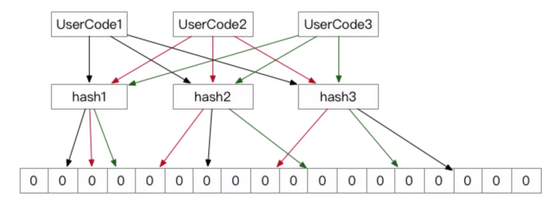
用布隆过滤器实际只需要判断客户端传过来的userCode是否存在就可以,图中的hash1,hash2,hash3分别代表三种hash算法,不同的userCode对应着不同的数据位,当需要校验的时候,判断每一种算法的得出来的byte位是否相同,只要一位不同,那么我们可以认为这个userCode不存在。
一般BloomFilter 要缓存全量的 key,这就要求全量的 key 数量不大,10 亿条数据以内最佳,因为 10 亿条数据大概要占用 1.2 GB 的内存。也可以用 BloomFilter 缓存非法 key,每次发现一个 key 是不存在的非法 key,就记录到 BloomFilter 中,这种记录方案,会导致 BloomFilter 存储的 key 持续高速增长,为了避免记录 key 太多而导致误判率增大,需要定期清零处理
布隆使用案例如下:
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.util.*;
public class BFDemo {
private static final int insertions = 1000000;//100W
public static void main(String[] args) {
BloomFilter bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions);
Set sets = new HashSet(insertions);
List<String> lists = new ArrayList(insertions);
for (int i = 0; i < insertions; i++) {
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
sets.add(uuid);
lists.add(uuid);
}
int wrong = 0;
int right = 0;
for (int i = 0; i < 10000; i++) {
String test = i % 100 == 0 ? lists.get(i / 100) : UUID.randomUUID().toString(); //随机生成1W字符串
if (bf.mightContain(test)) {
if (sets.contains(test)) {
right++;
} else {
wrong++;
}
}
}
System.out.println("========right=======" + right);
System.out.println("========wrong=======" + wrong);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
上文中提到的两种方法,比较:
| 解决方案 | 适用场景 | 优缺点 |
|---|---|---|
| 缓存空数据 | 1. 数据命中不高2. 数据频繁变化实时性高 | 1.维护简单2.需要更多的缓存空间3.可能数据不一致 |
| 布隆过滤器 | 1. 数据命中不高2. 数据相对固定实时性低 | 1.代码维护复杂2.缓存空间占用少 |
缓存雪崩问题
缓存雪崩一般是由两个原因导致的
第一个原因是:缓存中有大量数据同时过期,导致大量请求无法得到处理。
如图所示:
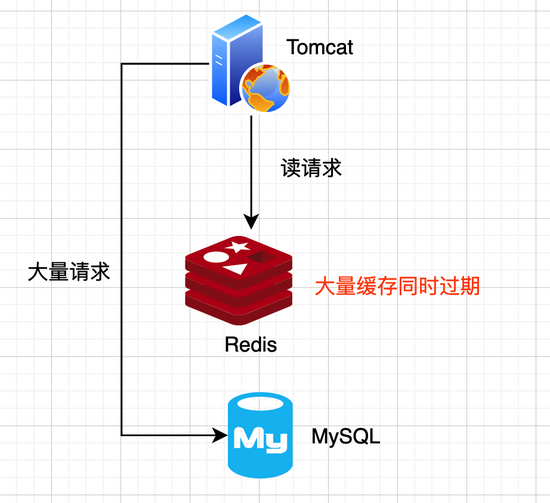
解决方案:
设计不同的过期时间
我们可以避免给大量的数据设置相同的过期时间。如果业务层的确要求有些数据同时失效,你可以在用EXPIRE命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数(例如,随机增加1~3分钟),这样一来,不同数据的过期时间有所差别,但差别又不会太大,既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求
服务降级处理
发生缓存雪崩时,针对不同的数据采取不同的处理方式。
-
当业务应用访问的是非核心数据时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
-
当业务应用访问的是核心数据时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
对缓存增加多个副本
缓存异常或请求 miss 后,再读取其他缓存副本,而且多个缓存副本尽量部署在不同机架,从而确保在任何情况下,缓存系统都会正常对外提供服务
对缓存体系进行实时监控
当请求访问的慢速比超过阀值时,及时报警,通过机器替换、服务替换进行及时恢复;也可以通过各种自动故障转移策略,自动关闭异常接口、停止边缘服务、停止部分非核心功能措施,确保在极端场景下,核心功能的正常运行。
第二个原因是:
如果Cache层由于某些原因(宕机、cache服务挂了或者不响应了)整体crash掉了,也就意味着所有的请求都会达到DB层,所有DB调用量会暴增,所以它有点扛不住了,甚至也会挂掉。
如图所示:
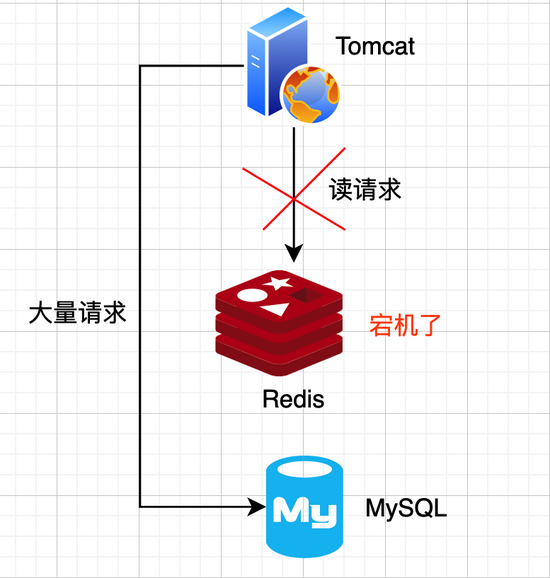
雪崩过后缓存已经crash,解决方案无非是让DB能承受更大数据压力,我们可以DB扩容解决,但不是长久之计,最好解决办法是如何预防缓存雪崩。
如何预防我们可以从以下方面入手:
保证Cache服务高可用性。
如果我们的cache也是高可用的,即使个别实例挂掉了,影响不会很大(主从切换或者可能会有部分流量到了后端),实现自动化运维。
例如:memcache的一致性hash、redis的sentinel和cluster机制
依赖隔离组件为后端限流。
其实无论是cache或者是mysql、hbase、甚至别人的RPC都会出现问题,我们可以将这些视同为资源,作为并发量较大的系统,假如有一个资源不可访问了,即使设置了超时时间,依然会hold住所有线程,造成其他资源和接口也不可以访问。
提前演练预估。
在项目上线前,通过演练,观察cache crash后,整体系统和DB的负载,提前做好预案。

















