












英国生物学家达尔文于 1859 年出版了震动整个学术界和宗教界的《物种起源》,达尔文在这本书里提出了生物进化论学说,认为生命在不断演变进化,物竞天择适者生存。
没有历史的计算机
生命是这样,实际上计算机技术也是如此。
计算机技术也和生命体一样在不断演变进化,在讨论一项技术时,如果不了解其演变过程而仅仅着眼于当下就会让人疑惑,不巧的是这正是当前计算机教育的现状——没有历史。
因此,在这里我将尝试从历史的角度来讲讲 CPU,以及 CPU 的发展历程。
本篇主要关注CPU与复杂指令集CISC。
首先来看下什么是CPU。
什么是CPU?
我们都是程序员,那么从程序员的角度来看,CPU的工作其实是很简单的。
我们编写的所有程序,不管是简单的Hello World,还是复杂的比如PhotoShop之类大型App,最终都会被编译器转为一条条简单的机器指令,因此在CPU看来所有程序是没有什么本质区别的,无非就是一个包含的指令多,一个包含的指令少,这些指令就保存在可执行文件中,程序运行时被加载到内存开始被CPU执行。
管你是简单程序还是复杂程序,CPU才不关心这些,它只需要简单一条一条的执行就可以了,因此,在程序员眼里 CPU 是一个很简单的家伙。
有很多同学可能会好奇CPU是怎么构造出来,你可以参考《你管这破玩意叫CPU》。
接下来我们的视角就可以进一步聚焦了,CPU执行的是什么机器指令呢?
CPU的能力圈:指令集
我们该怎样描述一个人的能力呢?写过简历的同学肯定都知道,就像这样:
会写代码
- 会炒菜
- 会唱歌
- 会跳舞
- 会炒股
- 。。。
巴菲特有一个词用的很好,这叫能力圈,如果一个人会“写代码”,那么你命令这个人“写代码”,他就能写出代码来(现实情况下你让他写代码他可能会过来打你)。
CPU也是同样的道理,每种类型的CPU都要自己的能力圈,只不过CPU的能力圈有一个特殊的名字,叫做 Instruction Set Architecture ,ISA,也就是指令集,指令集中包含各种各样的指令:
- 会加法
- 会从内存把数据搬运到寄存器
- 会跳转
- 会比较大小
- 。。。
指令集告诉我们一个CPU可以干嘛。
你从ISA中找一条指令发给CPU,CPU就是完成这条指令所代表的任务。
ISA有什么用呢,当然是程序员用来编程啦!
没错,最初的程序都是面向CPU直接用汇编来写程序,这一时期也非常的朴实无华,没有那么多花哨的概念,什么面向对象啦,什么设计模式啦,统统没有,总之这个时期的程序员写代码只需要看看ISA就可以了。
这就是指令集的概念,注意,指令集是CPU告诉程序员该怎么让自己工作的。
不同的CPU会有不同类型的指令集,指令集的类型除了影响程序员写汇编程序之外还会影响CPU的硬件设计,到底CPU该采用什么类型的指令集,CPU该如何设计,这一论战持续至今,并且愈发精彩。
接下来我们看一下第一种也是最先诞生的指令集类型:复杂指令集,Complex Instruction Set Computer,简称CISC。当今普遍存在于桌面PC以及服务器端的x86架构就是基于复杂指令集CISC,生产x86处理器的厂商就是我们熟悉的“等,等等等等”英特尔以及AMD。
抽象:少就是多
直到1970s年代,这一时期编译器还非常菜,不像现在这么智能,没多少人信得过编译器,大部分程序还是用汇编语言纯手工编写 (这一点极为重要,对于接下来理解复杂指令集非常关键),这对现代程序员来说是无法想象的,不要说手写汇编语言,就是看懂汇编语言的程序员都不会很多。
当然,现代编译器已经足够强大足够智能,编译器生成的汇编语言已经足够优秀,因此当今程序员,除了编写操作系统以及部分驱动的那帮家伙,剩下的几乎已经意识不到汇编语言的存在了,不要觉得可惜,这是生产力进步的表现,用高级语言编写程序的效率可是汇编语言望尘莫及的。
题外话说的有点多,总之,这一时期的大部分程序都是直接通过汇编语言编写的,因此大家普遍认为指令集应该更加丰富一些、指令本身功能更强大一些,程序员常用的操作最好都有对应的特定指令,毕竟大家都在直接用汇编语言来写程序,如果指令集很少或者指令本身功能单一,那么程序员用汇编指令写起程序会会非常繁琐,很不方便,如果你在这个时期用汇编写程序你也会这样想。
这就是这个时期一些计算机科学家所谓的抹平差异,semantic gap,抹平什么差异呢?
大家认为高级语言中的一些概念比如函数调用、循环控制、复杂的寻址模式、数据结构和数组的访问等都应该直接有对应的机器指令,这些就是现代大家认为的复杂指令集CISC非常鲜明的特点。
除了更方便的使用汇编语言写程序,另一点需要考虑就是存储。
物种起源
当今的计算机都遵从冯诺依曼架构,该架构的核心思想之一是“程序应该和数据一样都作为比特保存在计算机存储设备中”,下面这张图是所有计算设备的鼻祖,你现在看这篇文章用计算设备,不管是智能手机或者iPad、PC,亦或是存放这篇文章的微信数据中心服务器,其本质都是下面这张简单的图,这张图是一切计算设备的起源。
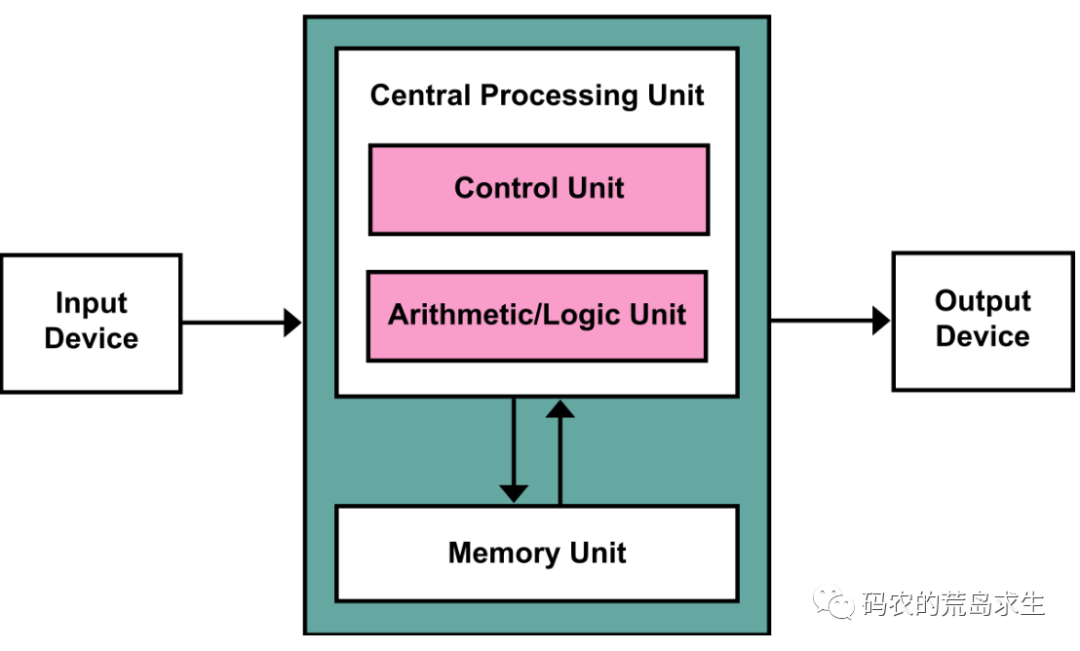
代码也是要占存储空间的
从冯诺依曼结构中我们就能知道为什么当今可执行程序中,比如Windows下的EXE或者Linux下的ELF文件,即包含机器指令也包含数据,对于程序员来说我们可以简单的认为可执行程序中有两部分内容:数据段以及代码段:

由此可见,程序员写的代码是要占据存储空间的,要知道在1970s年代,内存大小仅仅数KB到数十KB,这是当今程序员不可想象的,因为现在(2021年)的智能手机内存都已经数GB。如图所示是1974年发布的Intel 1103内存芯片:
大小只有 1KB 的英特尔1103存储芯片的于1974年发布,这标志着计算机工业界开始进入动态随机存储DRAM时代,DRAM也就是我们熟知的内存。
大家可以思考一下,几KB的内存,可谓寸土寸金,这么小的内存要想装入更多的程序就必须仔细的设计机器指令以节省程序占据的空间,这就要求:
- 一条机器指令尽可能完成更多的任务,这很容易理解,就像在《你管这破玩意叫编程语言》这篇中的例子一样,你更希望有一条“给我端杯水”的指令,而不是自己去写“迈出左脚;停住;迈出右脚;直到饮水机;伸出右手;拿起水杯;接水。。。”等等这样的汇编代码
- 机器指令长度不固定,也就是变长机器指令,简单的指令占据更少的空间
- 机器指令高度编码(encoded),提高代码密度,节省空间
复杂指令集诞生的必然
基于对程序员方便编写汇编语言以及节省代码存储空间的需要,直接促成了复杂指令集的设计,因此我们可以看到复杂指令集是这一时期必然的选择,该指令集就这样诞生了并开始成为主流。
就这样经过一段时间后,人们发现了新的问题,由于单条指令比较复杂,设计解码机器指令的硬件(CPU的一部分)成了一件非常麻烦的事情,该怎样解决这一问题呢?
CPU真的在直接执行机器指令吗?
作为程序员,我们知道,对于重复使用的代码其实是没有必要一遍遍编写的,你可以把这些代码封装到函数中,这样每次使用时只需要调用这个函数就好了,这个思路可以解决上述问题。
对于指令集中的每一条机器指令都有一小段对应的程序,这些程序存储在CPU中,这些程序都是由更简单的指令组成,这些指令就是所谓的微代码,Microcode。
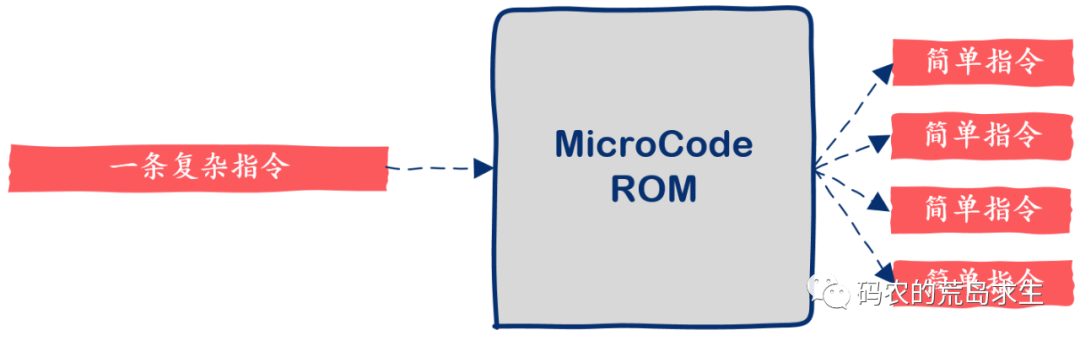
就这样CPU的指令集可以添加更多的指令,代价仅仅是再多一些简单的微代码而已,是不是很天才的设计。
在这里也可以看到,一般我们认为CPU直接执行机器指令,严格来说这是不正确的,对于含有微代码设计的CPU来说,CPU直接执行的并不是机器指令,而是微代码,微代码是CPU以及机器指令的中间层,机器指令相对于微代码来说是“更高级的语言”,机器指令对程序员来说可见,但微代码对程序员来说不可见,程序员无法直接使用微代码来控制CPU。

而在这一时期,这些微代码普遍存放在ROM中,Read-Only Memory,而ROM普遍要比内存便宜,因此依靠存储在ROM中的微代码来设计更多复杂指令进而减少程序本身对内存的占用是非常划算的。
新的问题
一切看上去都很好,有了复杂指令集,程序员可以更方便的编写汇编程序,这些程序也不需要占用很多存储空间,代价就是CPU中需要有微代码来简化CPU设计。
然而这一设计随着时间的推移又出现了新的问题。
作为程序员我们知道代码难免会有bug,微代码也不会有例外。但修复微代码的bug要比修复普通程序的bug困难的多,你无法像普通程序那样来测试、调试微代码,这一切都太复杂了。
而且微代码设计非常消耗晶体管,1979年代的Motorola 68000 处理器就采用该设计,其中三分之一的晶体管都用在了微代码上。
同年,计算机科学家Dave Patterson被委以重任来改善微代码设计,为此他还专门发表了论文,但他后来又推翻了自己想法,认为微代码设计的复杂性问题很难解决,有问题的是微代码这种设计本身。。
因此,有人开始反思,是不是还会有更好的设计。。。
预知后事如何请听下回分解。
总结
CPU是整个计算机系统的核心,CPU指令集ISA更是核心中的核心。
本文从历史的角度讲述了复杂指令集出现的必然,复杂指令集对于那些直接使用汇编语言进行编程的程序员来说是很方便的,同时复杂指令集的指令密度更高,相同的存储空间可以存储更多程序,这一切都推动了复杂指令集的发展。
然而任何事物都有其必然性以及局限性,复杂指令集也不例外,随着时间的推移采用复杂指令集的CPU设计出现各种各样的问题,面对这些问题一部分人开始重新思考指令集到底该如何设计,我们将在下篇文章中继续讲述这一话题。
希望本篇对大家理解复杂指令集有所帮助。
本文转载自微信公众号「码农的荒岛求生」,可以通过以下二维码关注。转载本文请联系码农的荒岛求生公众号。















