本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
Arm v9架构,可以说是10年以来最大的升级。
在上月发布服务器端的Neoverse V1与N2平台之后,消费端的首批CPU终于亮相。
包括Cortex-X2超大核、Cortex-A710大核以及Cortex-A510小核,分别取代X1、A78和A55。
值得一提的是,小核系列上一次更新还是在2017年。
超大核X2和小核A510已经完全基于64位指令集,只有A710还兼容32位。
Arm说这是专为中国移动端市场保留的,因为只有中国还保留着大量32位的手机App。

Arm要在2023年前彻底抛弃32位,App开发商们,再不升级就要被淘汰了。
大中小核完整方案
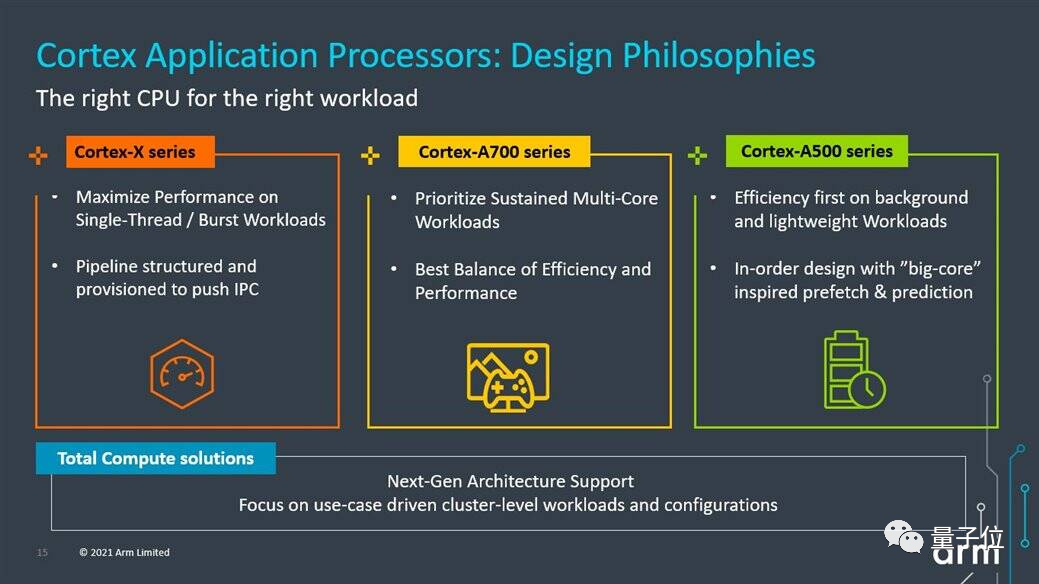
去年开始,Arm让A系列继续保持PPA (性能、功耗、面积)的设计理念。
大核A700系列将优先用于持续的主力多核负载,小核A500系列负责效率优先的轻型和后台任务。
而超大核X系列被允许在尺寸和功率上继续增长,以达到更高的单核性能和应对突发的工作负载。
下面来看看这次牙膏到底挤出了多少吧。
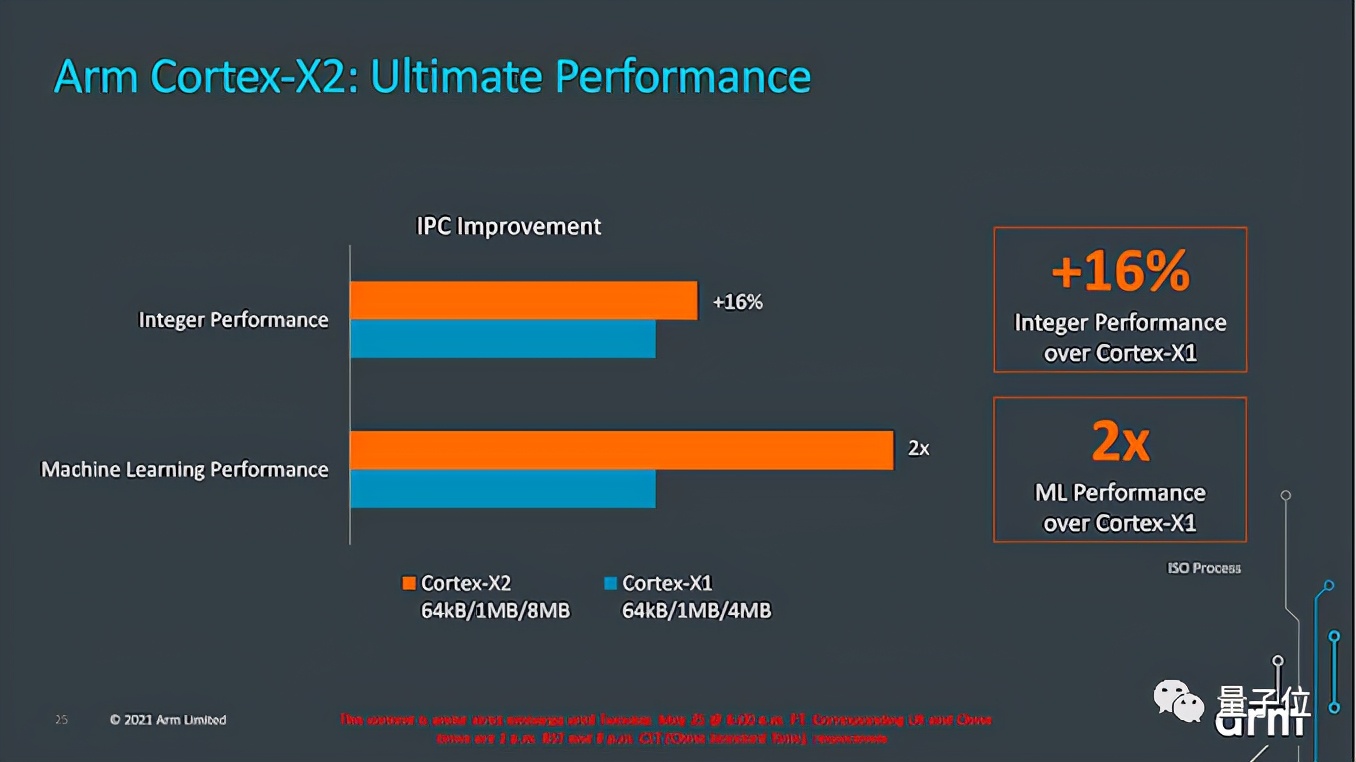
超大核X2:机器学习性能翻倍
X2与X1相比,机器学习性能则直接翻倍,在整数运算上性能也提高了16%。
具体的改进方面包括:
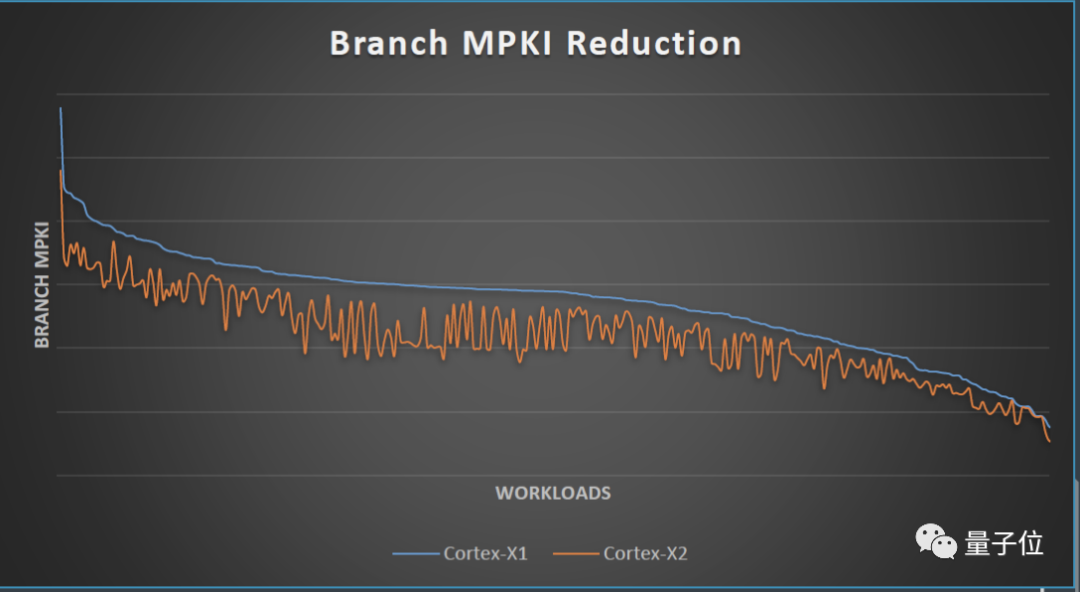
分支预测(Branch Prediction)与提取指令(Fetch)解耦,可有效减少MPKI(每千条指令失误)
调度阶段的指令周期从2个减少到1个,从而使总周期从11个减少到10个。
Arm表示,尽管这种变化会增加工程上的难度,以及有增加功耗和面积的代价,但相比于性能大幅提升来说还是值得的。
ROB(重新排序缓冲区)增加30%,提高乱序执行能力。
支持SVE2可伸缩矢量扩展,让开发人员减少代码编写和调试难度。
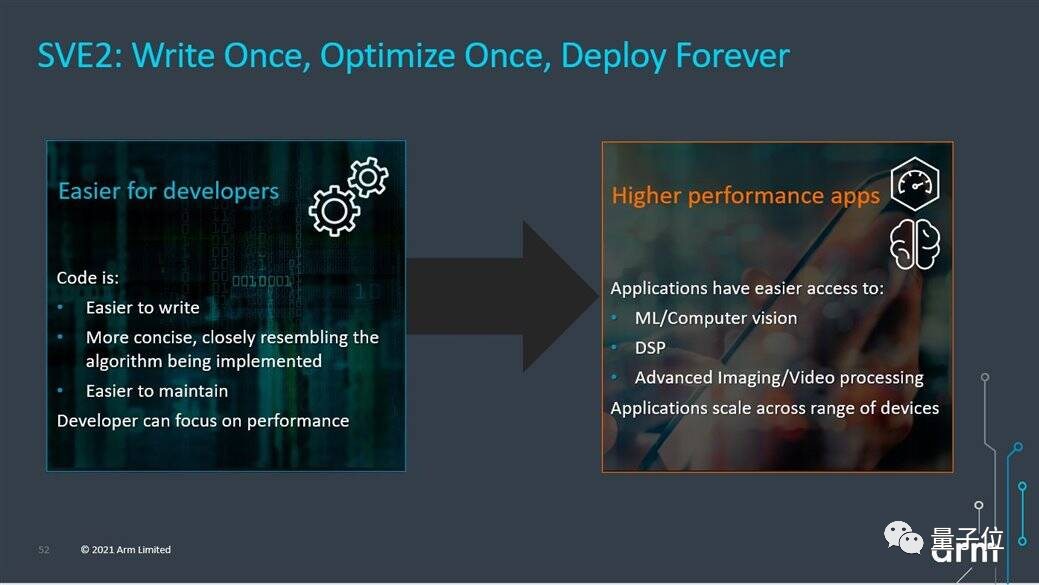
除了用于高端手机外,超大核X系列还将用在笔记本等大屏幕计算设备上。
大核A710:效率提升30%、性能10%
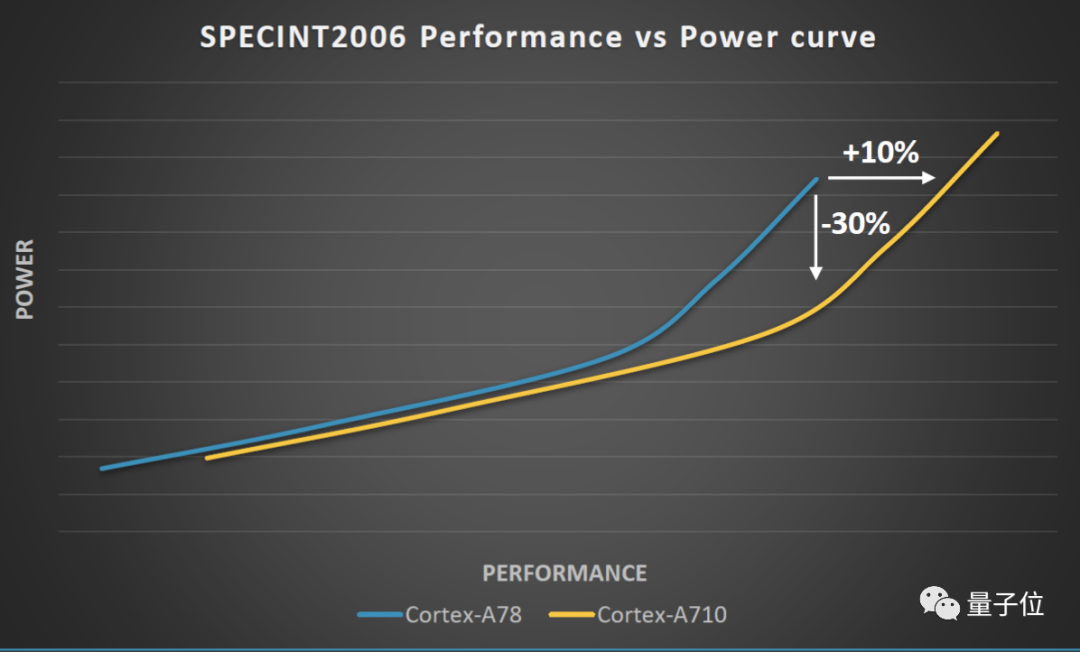
A710将继续维持性能与效率之间的平衡,有着与X2类似的改进分支预测、缩减指令周期以及支持SVE2等设计。
特别之处在于,将Macro-OP缓存的宽度从A78的6缩减到5,主要是出于功耗、效率方面的考量。
另外还有一些改进,使CPU核心、DSU及内存之间通讯效率更高。

小核A510:4年来首次更新,可以合并核心
小核系列将继续使用顺序执行(In-order Execution Flow),这与苹果M1的效率核心Icestorm采用的乱序执行流程不同,Arm表示这种设计是最省电的。
此外最大的改动是可以将两个核心合并在一起,再进一步组成集群。
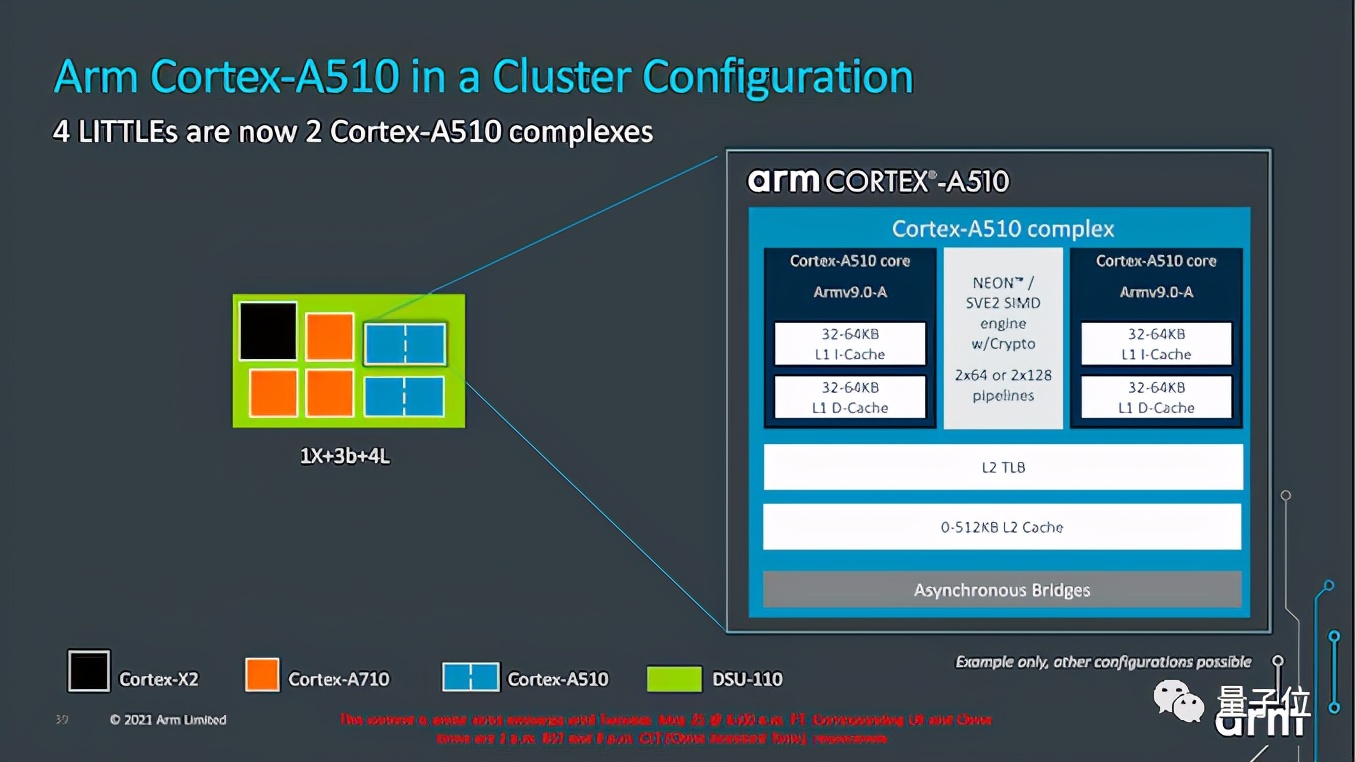
这样做可以减少面积,L2缓存、L2 TLB等可以在合并核心中共享。
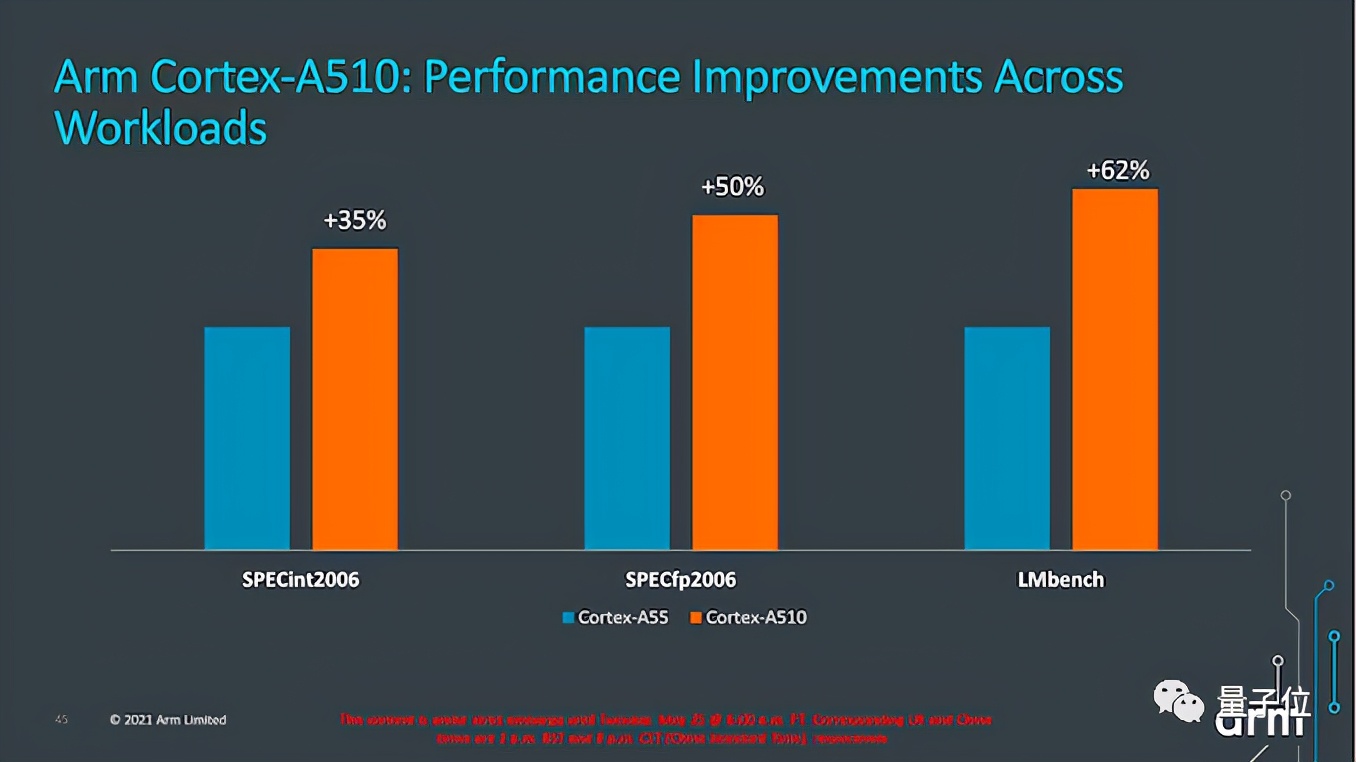
由于跨越了4年,A510的性能提升与上代A55相比较大,在35%到62%之间。
可配置的集群方式
所有这些CPU都可以通过全新的DynamIQ共享单元DSU-110以不同的CPU集群配置结合在一起。

新的DSU-110支持最高16MB的L3缓存,允许多达8个Cortex-X2内核集群。
这种可配置的集群方法可以满足从高端智能手机和笔记本电脑,到数字电视和可穿戴设备的不同市场需求。

新的CPU出现在市场上还需要一段时间,高通等芯片提供商一般在年底发布新产品。
所以Arm v9架构的手机、笔记本等产品,将会在2022年能见到。
华为或转投RISC-V
目前,英伟达与Arm的400亿美元收购案仍在进行,Arm v9架构最终能否授权给华为还未可知。
Arm v9的发布页面文末的合作伙伴中,有小米、OPPO、Vivo等国产厂商的寄语,其中却没有出现华为。

华为方面也在积极寻找替代方案,华为海思最新公布的鸿蒙开发版Hi3861。
虽然华为没有明确透露主芯片的型号,但其开发环境要求中需要用到RISC-V相关工具。
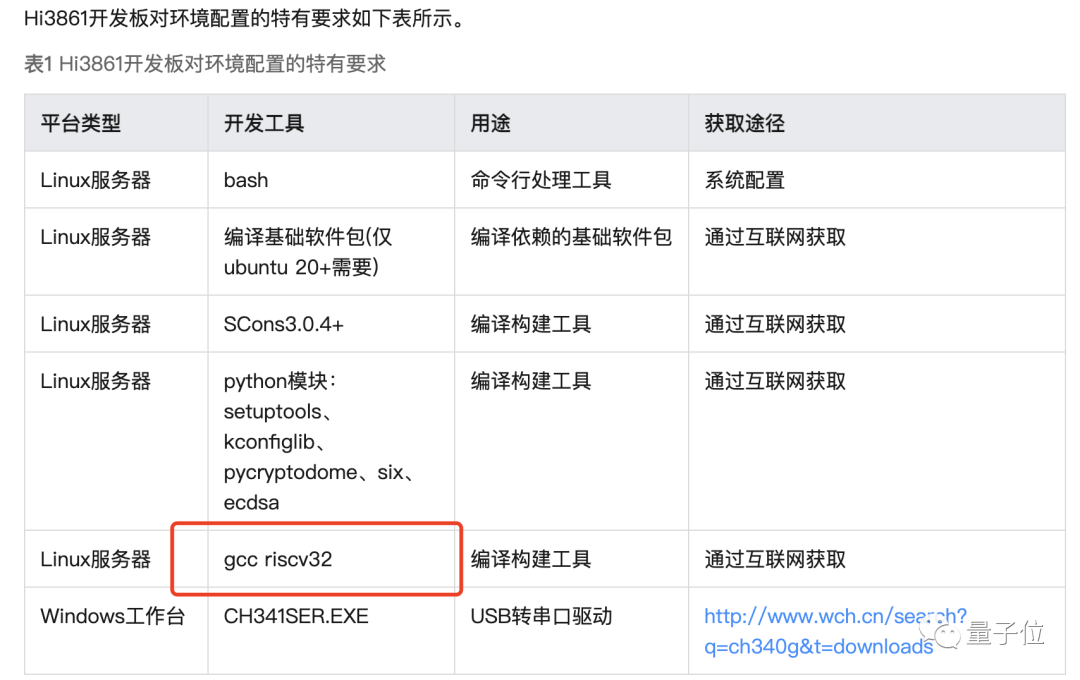
RISC-V是一款完全开源的指令集架构,采用宽松的BSD协议,企业可免费使用,并添加自有指令集拓展而不必开放共享。