本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
NER(命名实体识别)作为NLP的一项基本任务,其日常是训练人工智能(zhang)对一段文本中的专有名词(人名、地名、机构名等)进行识别和分类。
△烟台:我招谁惹谁了?
翻译成计算机语言,就是从一段非结构化的自然语言中找到各种实体,并将其分为合适的类别。且避免出现“江大桥同志到底就任了多少年南京市长”这样的问题
但在数据缺乏,样本不足的前提下,如何基于先验知识进行分类和学习,这就是目前NLPer面临的一道难题——少样本(Few-Shot)。
虽然已有越来越多针对少样本NER的研究出现(比如预训练语言模型BERT),但仍没有一个专属数据集以供使用。
而现在,共包含来自维基百科的18万条句子,49万个实体和460万标注,并具有8个粗粒度(coarse-grained types)实体类型和66个细粒度(fine-grained types)实体类型的数据集来了。

△目前已被ACL-IJCNLP 2021接受
这就是清华大学联合阿里达摩院共同开发的,行业内第一个人工标注(human-annotated)的少样本NER数据集,FEW-NERD。
什么样的数据集?
对比句子数量、标记数、实体类型等统计数据,FEW-NERD比相关领域内已有的NER数据集都要更大。
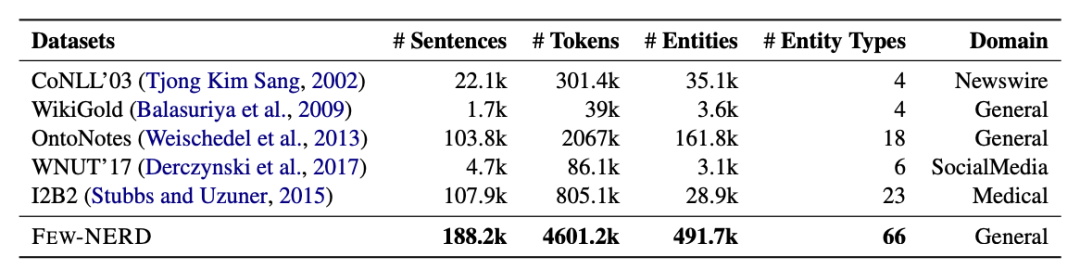
此外,它也是规模最大的人工标注的数据集。
为实体命名常常需要联系上下文,尤其是在实体类型很多时,注解难度将大大增加。
而FEW-NERD的注释来自70位拥有语言学知识的注释者,以及10位经验丰富的专家。
具体而言,每个段落会交由两人独立完成注释,然后由专家审查,再对分批抽取数据进行双重检查。这很好地保证了注释的准确性。

比如上述“London is the fifth album by the British rock band…”这句话中的实体“London”,就被准确标注成了“Art-Music”。
而在以段落为单位进行标注时,因为样本量并不多,所以FEW-NERD数据的类别分布预计是相对平衡的,这也是它与以往NER数据集的一个关键区别。
并且在实践中,大多数未见的实体类型都是细粒度的。而传统的NER数据集(如CoNLL’03、WNUT’17、OntoNotes)只包含4-18个粗粒度的类型。
这就难以构建足够多的N元任务(N-way metatasks),并训练学习相关特征。
相比之下,FEW-NERD共包含了112个实体标签, 并具有8个粗粒度实体类型,和66个细粒度实体类型。
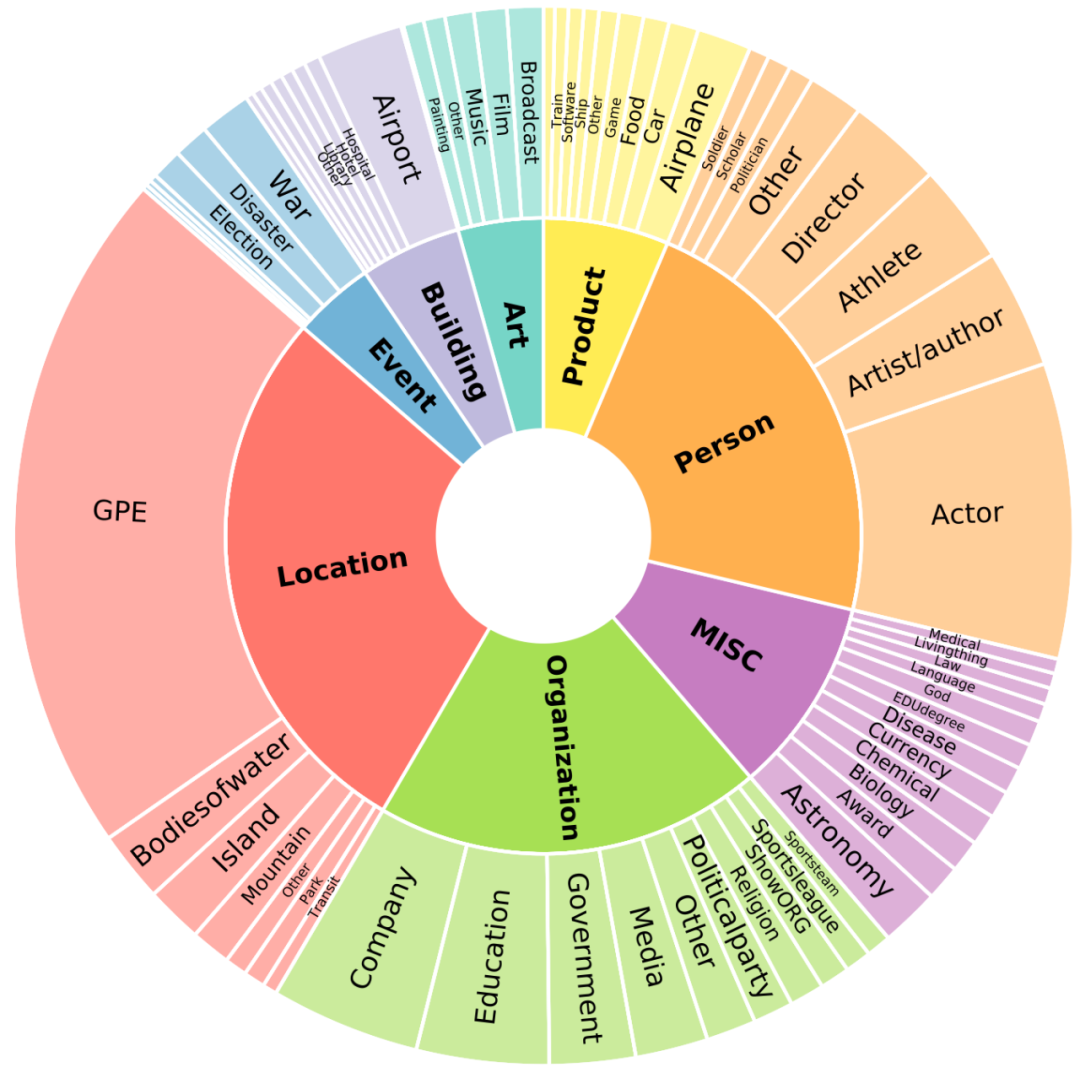
△内圈代表粗粒度的实体类型,外圈代表细粒度的实体类型。
基准的选择
为了探索FEW-NERD所有实体类型之间的知识相关性(knowledge correlations),研究者进行了实体类型相似性的实证研究。
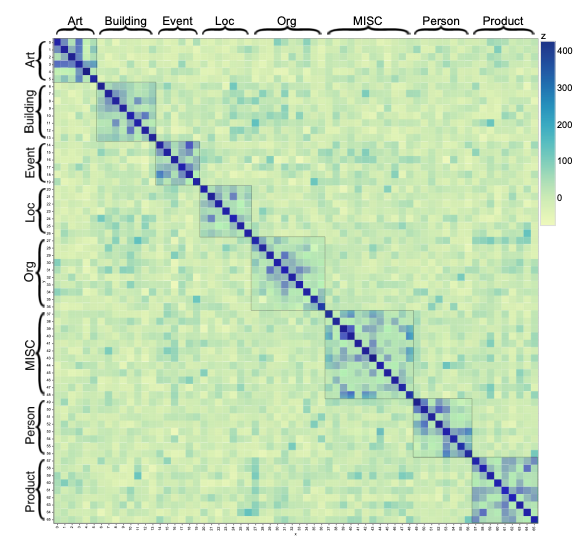
△方块代表两个实体类型的相似度。
从实验结果得知,相同粗粒度类型的实体类型具有较大的相似性,从而使知识迁移更加容易。
这启发了研究者从知识迁移的角度进行基准设定。最终设置了三个基准:
- FEW-NERD (SUP)
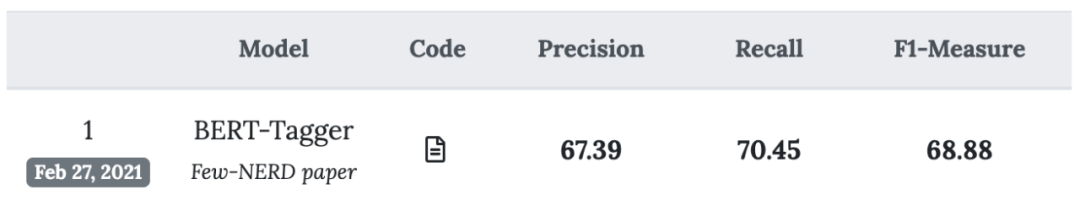
采用标准的监督式NER设置,将70%的数据随机分割为训练数据,10%为验证数据,20%为测试数据。
- FEW-NERD(INTRA)
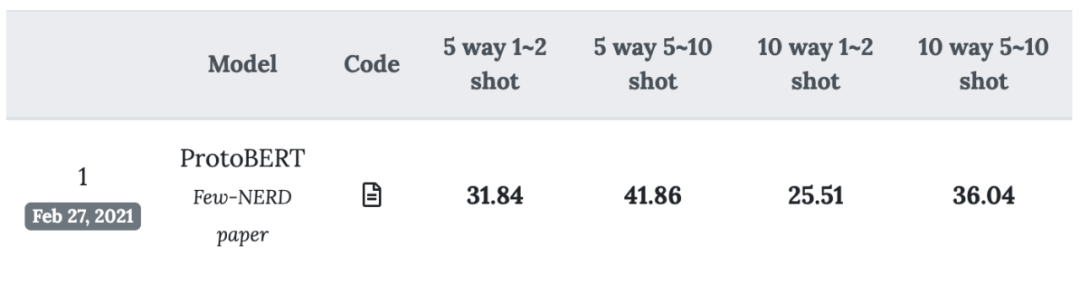
少样本学习任务,只包含粗粒度实体类型。

- FEW-NRTD (INTER)
少样本学习任务,包含60%的细粒度类型,20%的细粒度类型。
实际的应用
针对少样本命名实体识别,FEW-NERD提供了一个同时包含粗粒度和细粒度,且统一基准的大型数据集。
而作者也指出,由于精确的上下文标注,FEW-NERD数据集不仅可以用于少样本场景,在监督学习、终身学习、开放信息抽取、实体分类等任务上也可以发挥作用。
此外,建立在FEW-NERD基础上的模型和系统,还能帮助构建各个领域的知识图谱(KGs),包括生物医学、金融和法律领域,并进一步促进NLP在特定领域的应用发展。
开发者还表示,将在未来增加跨域注释、远距离注释和更精细的实体类型来扩展FEW-NERD。
数据集官网链接:
https://ningding97.github.io/fewnerd/
数据集下载:
https://github.com/thunlp/Few-NERD
论文地址:
https://arxiv.org/abs/2105.07464