












初次见面
大家好,我是 ELF 文件,大名叫 Executable and Linkable Format。
经常在 Linux 系统中开发的小伙伴们,对于我肯定是再熟悉不过了,特别是那些需要了解编译、链接的家伙们,估计已经把我研究的透透的。
为了结识更多的小伙伴,今天呢,就是我的开放日,我会像洋葱一样,一层一层地拨开我的心,让更多的小伙伴来了解我,欢迎大家前来围观。
以前啊,我看到有些小伙伴在研究我的时候,看一下头部的汇总信息,然后再瞅几眼 Section的布局,就当做熟悉我了。
从科学的态度上来说,这是远远不够的,未达究竟。
当你面对编译、链接的详细过程时,还是会一脸懵逼。
今天,我会从字节码的颗粒度,毫无保留、开诚布公、知无不言、言无不尽、赤胆忠心、一片丹心、鞠躬尽瘁、死而后已的把自己剖析一遍,让各位看官大开眼界、大饱眼福。
您了解这些知识之后呢,在今后继续学习编译、链接的底层过程,以及一个可执行程序在从硬盘加载到内存、一直到 main 函数的执行,心中就会非常的敞亮。
也就是说,掌握了 ELF 文件的结构和内容,是理解编译、链接和程序执行的基础。
你们不是有一句俗话嘛:磨刀不误砍柴工!
好了,下面我们就开始吧!
文件很单纯,复杂的是人
作为一种文件,那么肯定就需要遵守一定的格式,我也不例外。
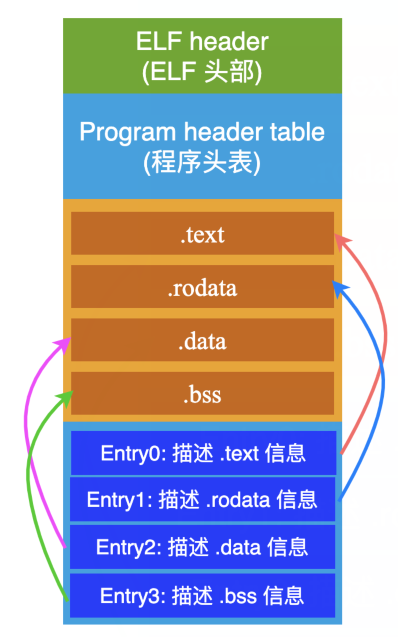
从宏观上看,可以把我拆卸成四个部分:
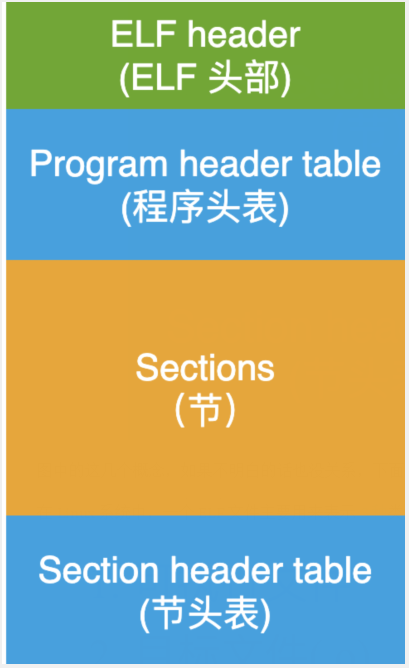
图中的这几个概念,如果不明白的话也没关系,下面我会逐个说明的。
在 Linux 系统中,一个 ELF 文件主要用来表示 3 种类型的文件:

既然可以用来表示 3 种类型的文件,那么在文件中,肯定有一个地方用来区分这 3 种情况。
也许你已经猜到了,在我的头部内容中,就存在一个字段,用来表示:当前这个 ELF 文件,它到底是一个可执行文件?是一个目标文件?还是一个共享库文件?
另外,既然我可以用来表示 3 种类型的文件,那么就肯定是在 3 种不同的场合下被使用,或者说被不同的家伙来操作我:
- 可执行文件:被操作系统中的加载器从硬盘上读取,载入到内存中去执行;
- 目标文件:被链接器读取,用来产生一个可执行文件或者共享库文件;
- 共享库文件:在动态链接的时候,由 ld-linux.so 来读取。
就拿链接器和加载器来说吧,这两个家伙的性格是不一样的,它们看我的眼光也是不一样的。
链接器在看我的时候,它的眼睛里只有 3 部分内容:

也就是说,链接器只关心 ELF header, Sections 以及 Section header table 这 3 部分内容。
加载器在看我的时候,它的眼睛里是另外的 3 部分内容:
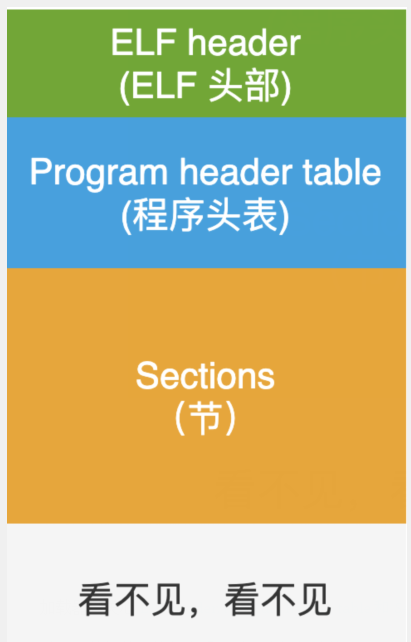
加载器只关心 ELF header, Program header table 和 Segment 这 3 部分内容。
对了,从加载器的角度看,对于中间部分的 Sections, 它改了个名字,叫做 Segments(段)。换汤不换药,本质上都是一样一样的。
可以理解为:一个 Segment 可能包含一个或者多个 Sections,就像下面这样:
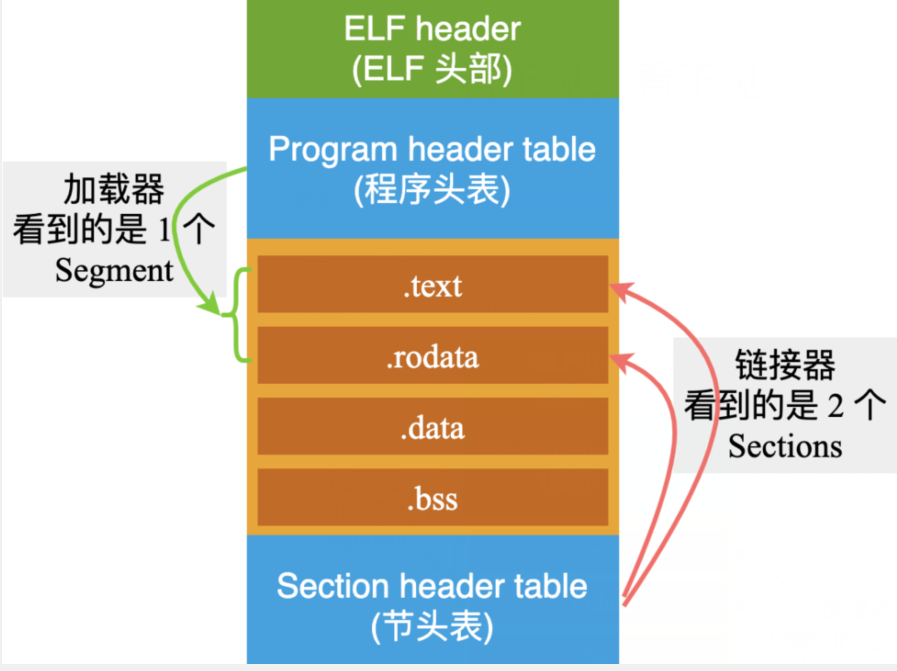
这就好比超市里的货架上摆放的商品:有矿泉水、可乐、啤酒,巧克力,牛肉干,薯片。
从理货员的角度看:它们属于 6 种不同的商品;但是从超市经理的角度看,它们只属于 2 类商品:饮料和零食。
怎么样?现在对我已经有一个总体的印象了吧?
其实只要掌握到 2 点内容就可以了:
- 一个 ELF 文件一共由 4 个部分组成;
- 链接器和加载器,它们在使用我的时候,只会使用它们感兴趣的部分。
还有一点差点忘记给你提个醒了:在 Linux 系统中,会有不同的数据结构来描述上面所说的每部分内容。
我知道有些小伙伴比较性急,我先把这几个结构体告诉你。
初次见面,先认识一下即可,千万不要深究哦。
描述 ELF header 的结构体:
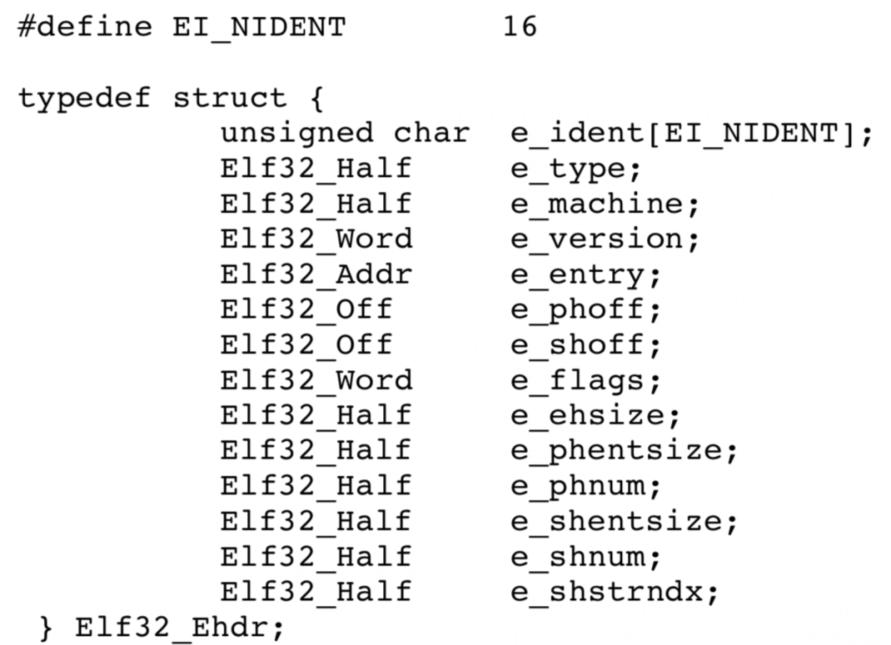
描述 Program header table 的结构体:

描述 Section header table 的结构体:

ELF header(ELF 头)
头部内容,就相当于是一个总管,它决定了这个完整的 ELF 文件内部的所有信息,比如:
- 这是一个 ELF 文件;
- 一些基本信息:版本,文件类型,机器类型;
- Program header table(程序头表)的开始地址,在整个文件的什么地方;
- Section header table(节头表)的开始地址,在整个文件的什么地方。
你是不是有点纳闷,好像没有说 Sections(从链接器角度看) 或者 Segments(从加载器角度看) 在 ELF 文件的什么地方。
为了方便描述,我就把 Sections 和 Segments 全部统一称为 Sections 啦!
其实是这样的,在一个 ELF 文件中,存在很多个 Sections,这些 Sections 的具体信息,是在 Program header table 或者 Section head table 中进行描述的。
就拿 Section head table 来举例吧:
假如一个 ELF 文件中一共存在 4 个 Section: .text、.rodata、.data、.bss,那么在 Section head table 中,将会有 4 个 Entry(条目)来分别描述这 4 个 Section 的具体信息(严格来说,不止 4 个 Entry,因为还存在一些其他辅助的 Sections),就像下面这样:
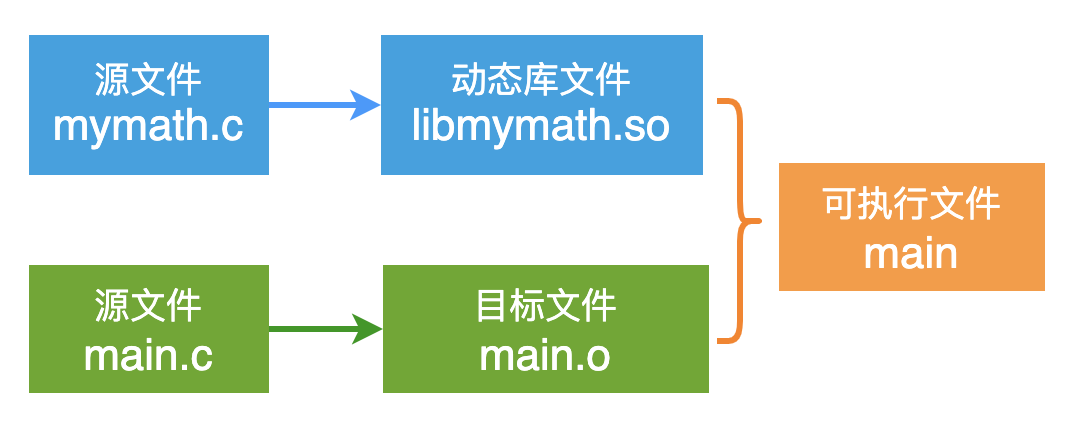
在开头我就说了,我要用字节码的粒度,扒开来给你看!
为了不耍流氓,我还是用一个具体的代码示例来描述,只有这样,你才能看到实实在在的字节码。
程序的功能比较简单:
- // mymath.c
- int my_add(int a, int b)
- {
- return a + b;
- }
- // main.c
- #include <stdio.h>
- extern int my_add(int a, int b);
- int main()
- {
- int i = 1;
- int j = 2;
- int k = my_add(i, j);
- printf("k = %d \n", k);
- }
从刚才的描述中可以知道:动态库文件 libmymath.so, 目标文件 main.o 和 可执行文件 main,它们都是 ELF 文件,只不过属于不同的类型。
这里就以可执行文件 main 来拆解它!
我们首先用指令 readelf -h main 来看一下 main 文件中,ELF header 的信息。
- readelf 这个工具,可是一个好东西啊!一定要好好的利用它。
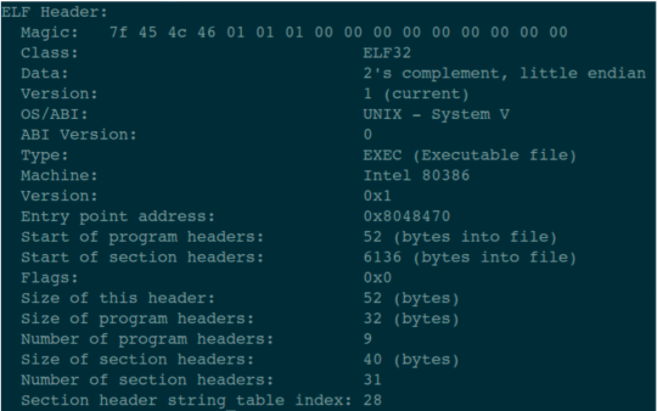
这张图中显示的信息,就是 ELF header 中描述的所有内容了。这个内容与结构体 Elf32_Ehdr 中的成员变量是一一对应的!
有没有发现图中第 15 行显示的内容:Size of this header: 52 (bytes)。
也就是说:ELF header 部分的内容,一共是 52 个字节。那么我就把开头的这 52 个字节码给你看一下。
这回,我用 od -Ax -t x1 -N 52 main 这个指令来读取 main 中的字节码,简单解释一下其中的几个选项:
- -Ax: 显示地址的时候,用十六进制来表示。如果使用 -Ad,意思就是用十进制来显示地址;
- -t -x1: 显示字节码内容的时候,使用十六进制(x),每次显示一个字节(1);
- -N 52:只需要读取 52 个字节;

这 52 个字节的内容,你可以对照上面的结构体中每个字段来解释了。
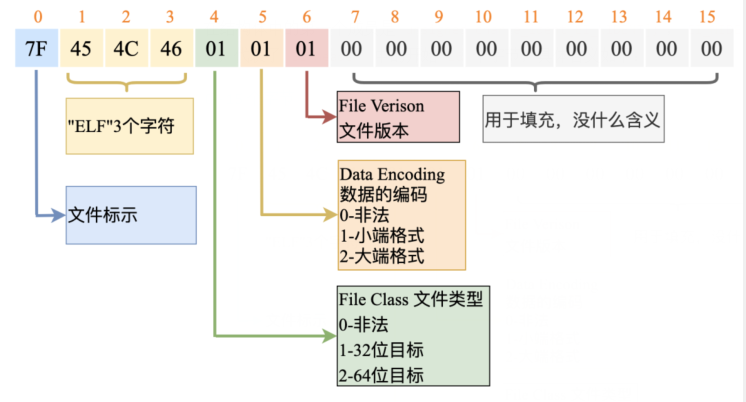
首先看一下前 16 个字节。
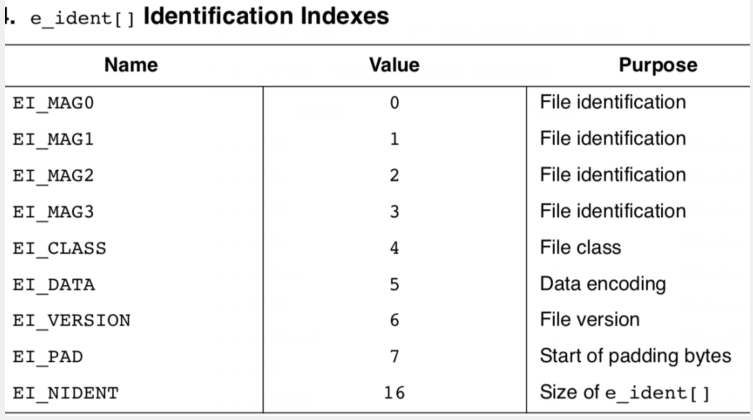
在结构体中的第一个成员是 unsigned char e_ident[EI_NIDENT];,EI_NIDENT 的长度是 16,代表了 EL header 中的开始 16 个字节,具体含义如下:
0 - 15 个字节
怎样样?我以这样的方式彻底暴露自己,向你表白,足以表现出我的诚心了吧?!
如果被感动了,别忘记在文章的最底部,点击一下在看和收藏,也非常感谢您转发给身边的小伙伴。赠人玫瑰,手留余香!
为了权威性,我把官方文档对于这部分的解释也贴给大家看一下:
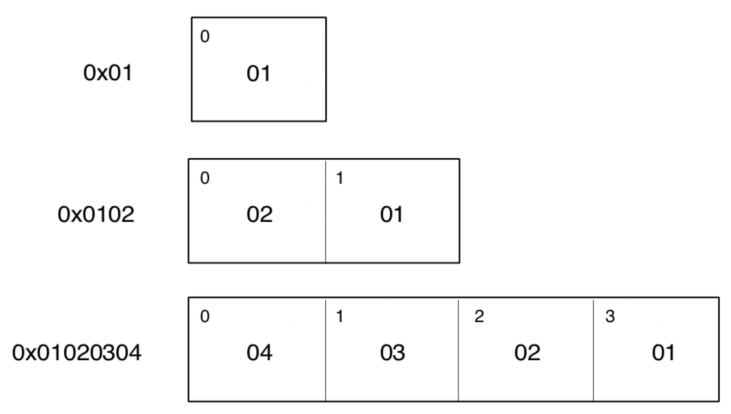
关于大端、小端格式,这个 main 文件中显示的是 1,代表小端格式。啥意思呢,看下面这张图就明白了:
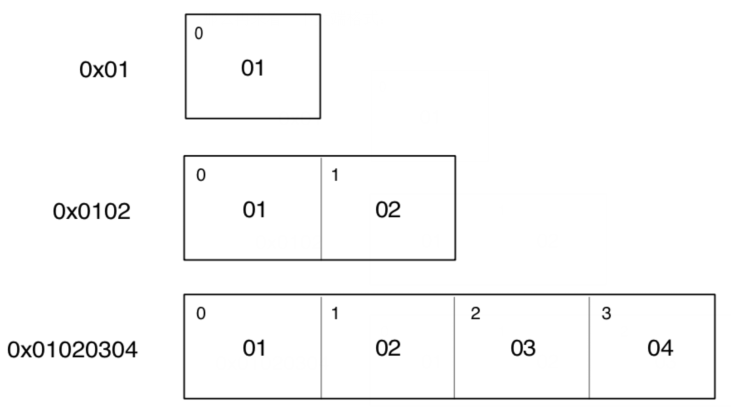
那么再来看一下大端格式:
好了,下面我们继续把剩下的 36 个字节(52 - 16 = 32),也以这样的字节码含义画出来:
16 - 31 个字节:
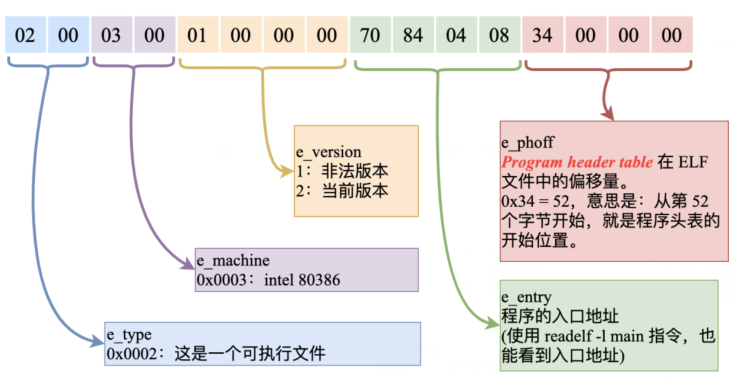
32 - 47 个字节:
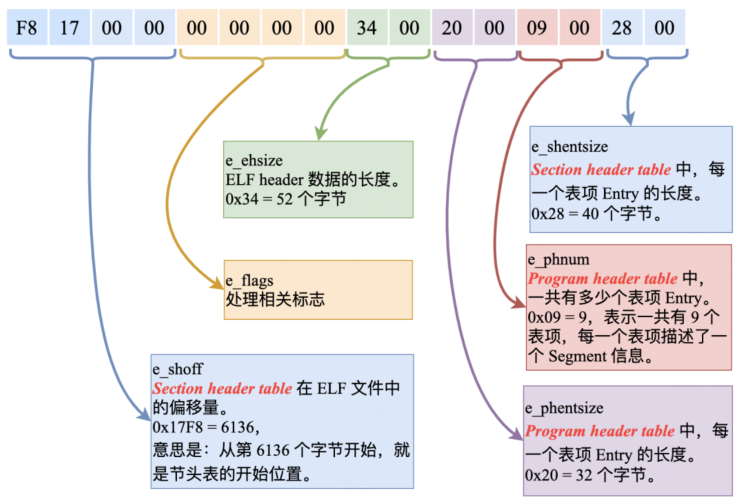
48 - 51 个字节:
具体的内容就不用再解释了,一切都在感情深、一口闷,话不多说,都在酒里~~ 哦不对,重点都在图里!
字符串表表项 Entry
在一个 ELF 文件中,存在很多字符串,例如:变量名、Section名称、链接器加入的符号等等,这些字符串的长度都是不固定的,因此用一个固定的结构来表示这些字符串,肯定是不现实的。
于是,聪明的人类就想到:把这些字符串集中起来,统一放在一起,作为一个独立的 Section 来进行管理。
在文件中的其他地方呢,如果想表示一个字符串,就在这个地方写一个数字索引:表示这个字符串位于字符串统一存储地方的某个偏移位置,经过这样的按图索骥,就可以找到这个具体的字符串了。
比如说啊,下面这个空间中存储了所有的字符串:

在程序的其他地方,如果想引用字符串 “hello,world!”,那么就只需要在那个地方标明数字 13就可以了,表示:这个字符串从偏移 13 个字节处开始。
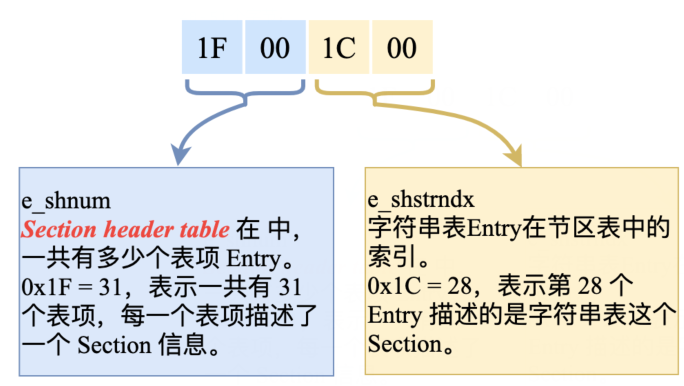
那么现在,咱们再回到这个 main 文件中的字符串表,
在 ELF header 的最后 2 个字节是 0x1C 0x00,它对应结构体中的成员 e_shstrndx,意思是这个 ELF 文件中,字符串表是一个普通的 Section,在这个 Section 中,存储了 ELF 文件中使用到的所有的字符串。
既然是一个 Section,那么在 Section header table 中,就一定有一个表项 Entry 来描述它,那么是哪一个表项呢?
这就是 0x1C 0x00 这个表项,也就是第 28 个表项。
这里,我们还可以用指令 readelf -S main 来看一下这个 ELF 文件中所有的 Section 信息:
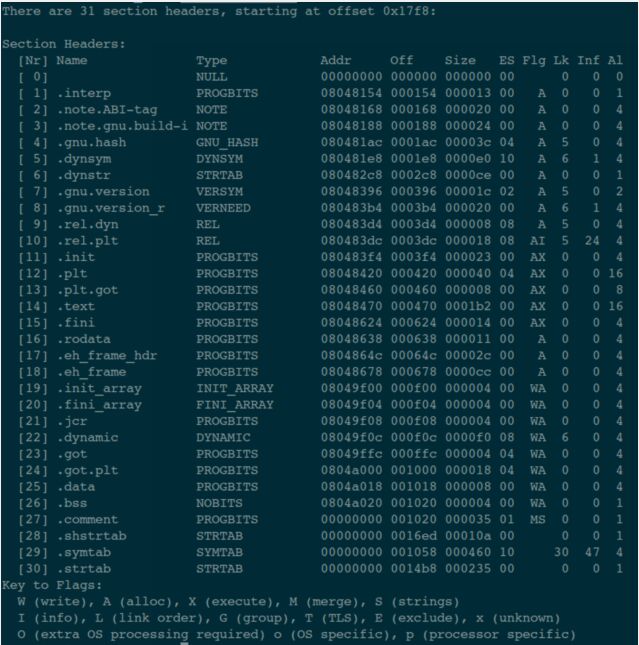
其中的第 28 个 Section,描述的正是字符串表 Section:

可以看出来:这个 Section 在 ELF 文件中的偏移地址是 0x0016ed,长度是 0x00010a 个字节。
下面,我们从 ELF header 的二进制数据中,来推断这信息。
读取字符串表 Section 的内容
那我就来演示一下:如何通过 ELF header 中提供的信息,把字符串表这个 Section 给找出来,然后把它的字节码打印出来给各位看官瞧瞧。
要想打印字符串表 Section 的内容,就必须知道这个 Section 在 ELF 文件中的偏移地址。
要想知道偏移地址,只能从 Section head table 中第 28 个表项描述信息中获取。
要想知道第 28 个表项的地址,就必须知道 Section head table 在 ELF 文件中的开始地址,以及每一个表项的大小。
正好最后这 2 个需求信息,在 ELF header 中都告诉我们了,因此我们倒着推算,就一定能成功。
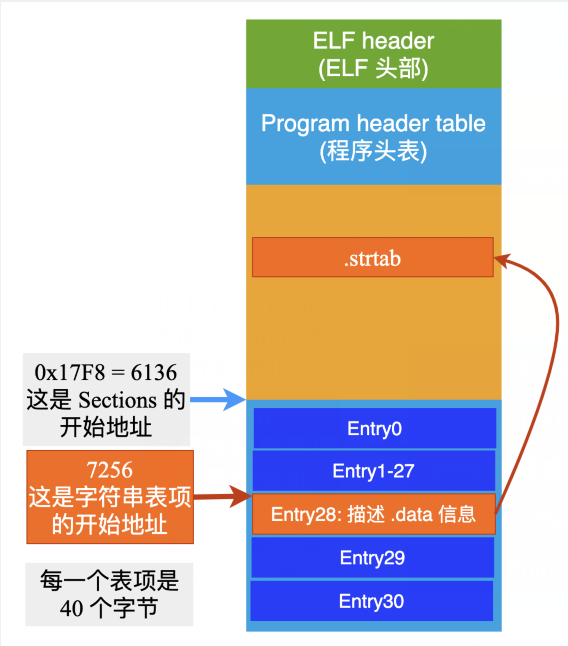
ELF header 中的第 32 到 35 字节内容是:F8 17 00 00(注意这里的字节序,低位在前),表示的就是 Section head table 在 ELF 文件中的开始地址(e_shoff)。
0x000017F8 = 6136,也就是说 Section head table 的开始地址位于 ELF 文件的第 6136个字节处。
知道了开始地址,再来算一下第 28 个表项 Entry 的地址。
ELF header 中的第 46、47 字节内容是:28 00,表示每个表项的长度是 0x0028 = 40 个字节。
注意这里的计算都是从 0 开始的,因此第 28 个表项的开始地址就是:6136 + 28 * 40 = 7256,也就是说用来描述字符串表这个 Section 的表项,位于 ELF 文件的 7256 字节的位置。
既然知道了这个表项 Entry 的地址,那么就扒开来看一下其中的二进制内容:
执行指令:od -Ad -t x1 -j 7256 -N 40 main。
其中的 -j 7256 选项,表示跳过前面的 7256 个字节,也就是我们从 main 这个 ELF 文件的 7256 字节处开始读取,一共读 40 个字节。

这 40 个字节的内容,就对应了 Elf32_Shdr 结构体中的每个成员变量:
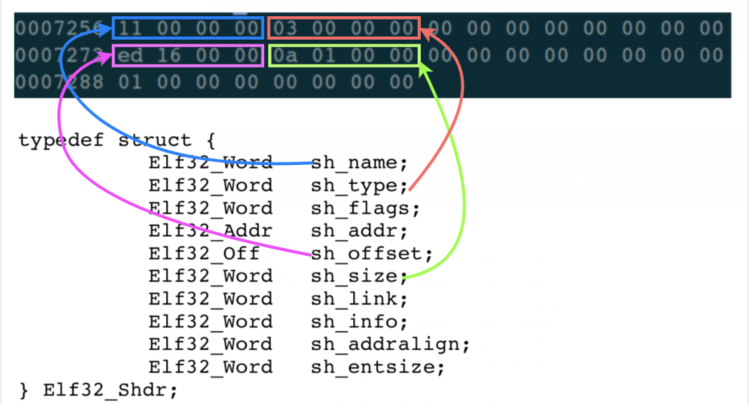
这里主要关注一下上图中标注出来的 4 个字段:
- sh_name: 暂时不告诉你,马上就解释到了;
- sh_type:表示这个 Section 的类型,3 表示这是一个 string table;
- sh_offset: 表示这个 Section,在 ELF 文件中的偏移量。0x000016ed = 5869,意思是字符串表这个 Section 的内容,从 ELF 文件的 5869 个字节处开始;
- sh_size:表示这个 Section 的长度。0x0000010a = 266 个字节,意思是字符串表这个 Section 的内容,一共有 266 个字节。
还记得刚才我们使用 readelf 工具,读取到字符串表 Section 在 ELF 文件中的偏移地址是 0x0016ed,长度是 0x00010a 个字节吗?
与我们这里的推断是完全一致的!
既然知道了字符串表这个 Section 在 ELF 文件中的偏移量以及长度,那么就可以把它的字节码内容读取出来。
执行指令: od -Ad -t c -j 5869 -N 266 main,所有这些参数应该不用再解释了吧?!
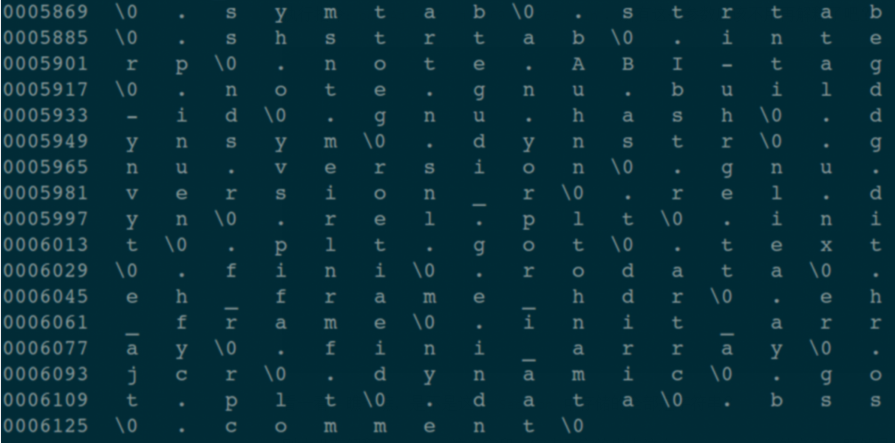
看一看,瞧一瞧,是不是这个 Section 中存储的全部是字符串?
刚才没有解释 sh_name 这个字段,它表示字符串表这个 Section 本身的名字,既然是名字,那一定是个字符串。
但是这个字符串不是直接存储在这里的,而是存储了一个索引,索引值是 0x00000011,也就是十进制数值 17。
现在我们来数一下字符串表 Section 内容中,第 17 个字节开始的地方,存储的是什么?
不要偷懒,数一下,是不是看到了:“.shstrtab” 这个字符串(\0是字符串的分隔符)?!
好了,如果看到这里,你全部都能看懂,那么关于字符串表这部分的内容,说明你已经完全理解了,给你一百个赞!!!
读取代码段的内容
从下面的这张图(指令:readelf -S main):
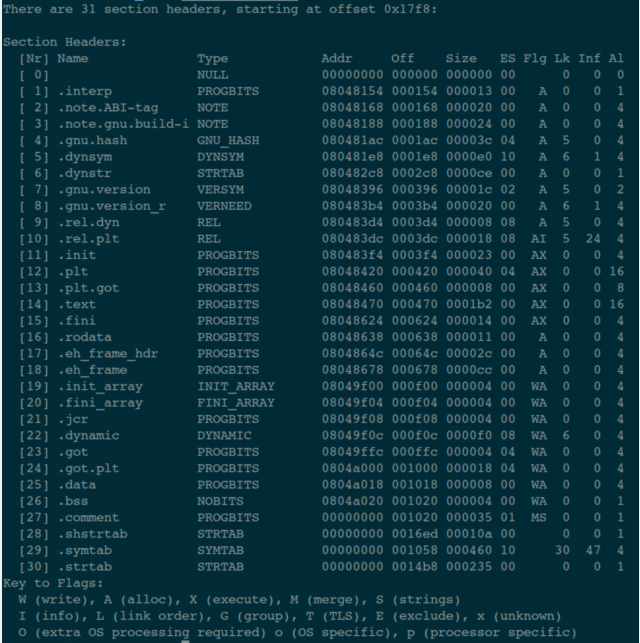
可以看到代码段是位于第 14 个表项中,加载(虚拟)地址是 0x08048470,它位于 ELF 文件中的偏移量是 0x000470,长度是 0x0001b2 个字节。
那我们就来试着读一下其中的内容。
首先计算这个表项 Entry 的地址:6136 + 14 * 40 = 6696。
然后读取这个表项 Entry,读取指令是 od -Ad -t x1 -j 6696 -N 40 main:

同样的,我们也只关心下面这 5 个字段内容:
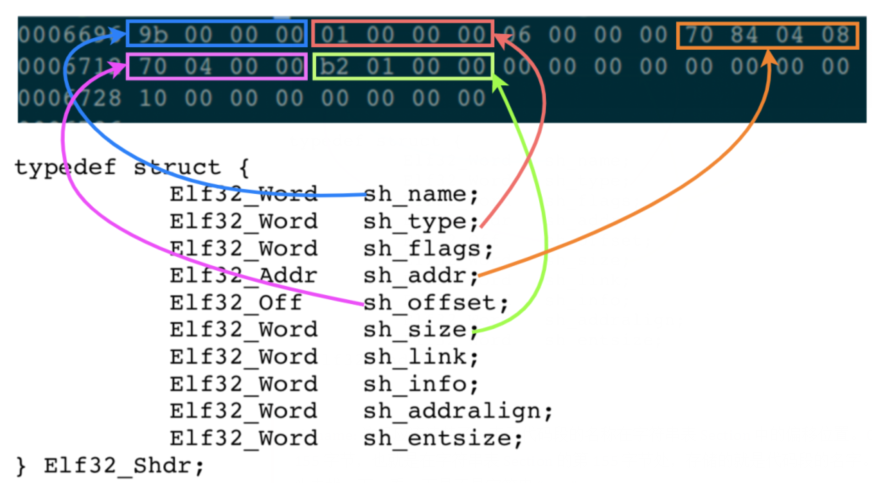
- sh_name: 这回应该清楚了,表示代码段的名称在字符串表 Section 中的偏移位置。0x9B = 155 字节,也就是在字符串表 Section 的第 155 字节处,存储的就是代码段的名字。回过头去找一下,看一下是不是字符串 “.text”;
- sh_type:表示这个 Section 的类型,1(SHT_PROGBITS) 表示这是代码;
- sh_addr:表示这个 Section 加载的虚拟地址是 0x08048470,这个值与 ELF header 中的 e_entry 字段的值是相同的;
- sh_offset: 表示这个 Section,在 ELF 文件中的偏移量。0x00000470 = 1136,意思是这个 Section 的内容,从 ELF 文件的 1136 个字节处开始;
- sh_size:表示这个 Section 的长度。0x000001b2 = 434 个字节,意思是代码段一共有 434 个字节。
以上这些分析结构,与指令 readelf -S main 读取出来的完全一样!
PS: 在查看字符串表 Section 中的字符串时,不要告诉我,你真的是从 0 开始数到 155啊!可以计算一下:字符串表的开始地址是 5869(十进制),加上 155,结果就是 6024,所以从 6024 开始的地方,就是代码段的名称,也就是 “.text”。
知道了以上这些信息,我们就可以读取代码段的字节码了.使用指令:od -Ad -t x1 -j 1136 -N 434 main 即可。
内容全部是黑乎乎的的字节码,我就不贴出来了。
Program header
文章的开头,我就介绍了:我是一个通用的文件结构,链接器和加载器在看待我的时候,眼光是不同的。
为了对 Program header 有更感性的认识,我还是先用 readelf 这个工具来从总体上看一下 main 文件中的所有段信息。
执行指令:readelf -l main,得到下面这张图:
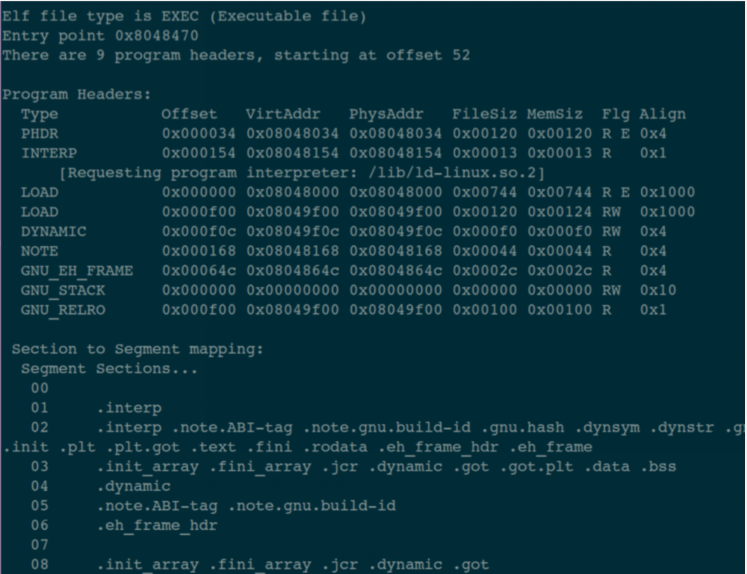
显示的信息已经很明白了:
- 这是一个可执行程序;
- 入口地址是 0x8048470;
- 一共有 9 个 Program header,是从 ELF 文件的 52 个偏移地址开始的;
布局如下图所示:
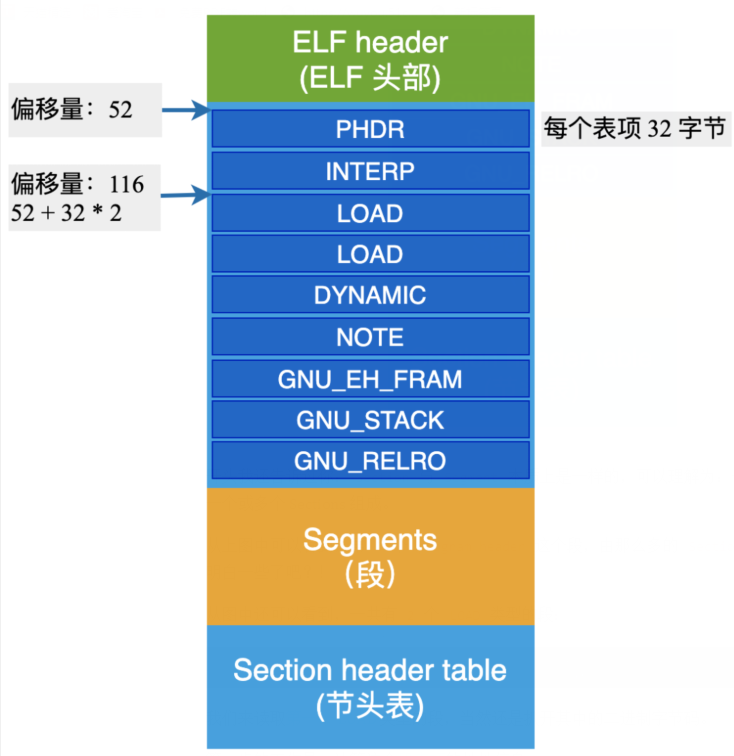
开头我还告诉过你:Section 与 Segment 本质上是一样的,可以理解为:一个 Secgment 由一个或多个 Sections 组成。
从上图中可以看到,第 2 个 program header 这个段,由那么多的 Section 组成,这下更明白一些了吧?!
从图中还可以看到,一共有 2 个 LOAD 类型的段:

我们来读取第一个 LOAD 类型的段,当然还是扒开其中的二进制字节码。
第一步的工作是,计算这个段表项的地址信息。
从 ELF header 中得知如下信息:
- 字段 e_phoff :Program header table 位于 ELF 文件偏移 52 个字节的地方。
- 字段 e_phentsize: 每一个表项的长度是 32 个字节;
- 字段 e_phnum: 一共有 9 个表项 Entry;
通过计算,得到可读、可执行的 LOAD 段,位于偏移量 116 字节处。
执行读取指令:od -Ad -t x1 -j 116 -N 32 main:

按照上面的惯例,我还是把其中几个需要关注的字段,与数据结构中的成员变量进行关联一下:
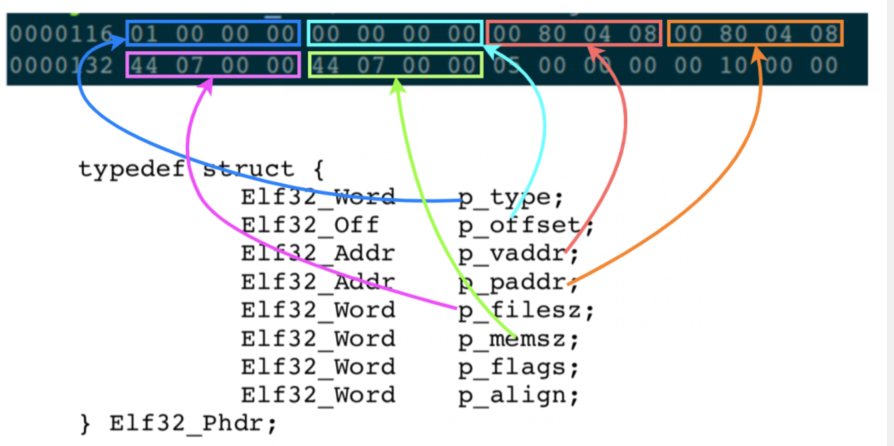
- p_type: 段的类型,1: 表示这个段需要加载到内存中;
- p_offset: 段在 ELF 文件中的偏移地址,这里值为 0,表示这个段从 ELF 文件的头部开始;
- p_vaddr:段加载到内存中的虚拟地址 0x08048000;
- p_paddr:段加载的物理地址,与虚拟地址相同;
- p_filesz: 这个段在 ELF 文件中,占据的字节数,0x0744 = 1860 个字节;
- p_memsz:这个段加载到内存中,需要占据的字节数,0x0744= 1860 个字节。注意:有些段是不需要加载到内存中的;
经过上述分析,我们就知道:从 ELF 文件的第 1 到 第 1860 个字节,都是属于这个 LOAD段的内容。
在被执行时,这个段需要被加载到内存中虚拟地址为 0x08048000 这个地方,从这里开始,又是一个全新的故事了。
再回顾一下
到这里,我已经像洋葱一样,把自己的层层外衣都扒开,让你看到最细的颗粒度了,这下子,您是否对我有足够的了解了呢?
其实只要抓住下面 2 个重点即可:
- ELF header 描述了文件的总体信息,以及两个 table 的相关信息(偏移地址,表项个数,表项长度);
- 每一个 table 中,包括很多个表项 Entry,每一个表项都描述了一个 Section/Segment 的具体信息。
链接器和加载器也都是按照这样的原理来解析 ELF 文件的,明白了这些道理,后面在学习具体的链接、加载过程时,就不会迷路啦!















