【51CTO.com快译】很多组织在Kubernetes集群中创建资源时可能会遇到以下情况:
(1)没有为工作负载指定CPU资源请求或较低的CPU资源请求,这意味着更多Pod可能在同一节点上工作。而在流量突增的时候,服务器中的CPU会以更长的延迟以达到最大值,但某些服务器可能会出现CPU软锁定的情况。
(2)同样,没有为工作负载指定内存资源请求或较低的内存资源请求。一些Pod(尤其是那些运行Java商业应用程序的Pod)将会重新启动,尽管它们实际上可以在本地测试中正常运行。
(3)在Kubernetes集群中,工作负载通常并不会在节点之间平均分配。特别是在大多数情况下,内存资源分布并不均匀,这意味着某些节点可以比其他节点有着更高的内存利用率。作为容器编排事实上的标准,Kubernetes应该具有一个有效的调度程序,以确保资源的均匀分配。但真的是这样吗?
在通常情况下,如果流量突然出现爆发性增长,并在服务器出现宕机以至于SSH登录失败时,则集群管理员将无法执行任何操作,只能重新启动群集。在本文中,将通过分析可能出现的问题并讨论如今解决的最佳实践,深入探讨Kubernetes的资源请求和限制。如果你对其底层机制感兴趣,则还可以从源代码的角度找到分析。本文将对你了解Kubernetes的资源请求和限制的工作方式以及它们可以按预期的方式工作的原因有所帮助。
概念
为了充分利用Kubernetes集群中的资源,提高调度效率,Kubernetes使用资源请求和限制来控制容器的资源分配。每个容器都有自己的请求和限制。这两个参数由resources.requests和resources.limits指定。一般来说,请求在调度中更为重要,而限制在运行中更为重要。

请求定义了容器所需的最少资源。例如,对于运行Spring Boot业务的容器,其指定的请求必须是Java虚拟机(JVM)需要在容器映像中消耗的最少资源量。如果只是指定低内存请求,则Kubernetes调度程序很可能会将Pod调度到没有足够资源来运行JVM的节点。也就是说,Pod无法使用JVM启动过程所需的更多内存。因此导致Pod不断重启。
另一方面,限制决定了容器可以使用的最大资源量,从而防止了由于过度消耗资源而导致的资源短缺或服务器宕机的情况。如果将其设置为0,则表示该容器没有资源限制。特别是,如果在没有指定请求的情况下设置限制,Kubernetes会认为默认情况下请求的值与限制的值相同。
请求和限制适用于两种类型的资源——可压缩的(例如CPU)和不可压缩的(例如内存)。对于不可压缩资源,进行适当的限制是非常重要的。
以下是请求和限制的概述:
- 如果Pod中的服务使用的CPU资源超过了指定的限制值,则Pod将会受到限制,但不会被终止。如果未设置限制值,则Pod可以使用所有空闲的CPU资源。
- 如果Pod使用的内存资源超出了指定的限制值,Pod中的容器进程将因OOM而终止。在这种情况下,Kubernetes倾向于在原始节点上重新启动容器,或者简单地创建另一个Pod。
- 0≤请求≤节点可分配;请求≤限制≤无限。
场景分析
在了解了请求和限制的概念之后,回顾一下以上提到的三种情况:
(1)情况1
首先,需要知道CPU资源和内存资源是完全不同的。CPU资源是可压缩的,CPU的分配和管理基于完全公平调度程序(CFS)。简而言之,如果Pod中的服务使用的CPU资源超过了指定的限制值,它将受到Kubernetes的限制。对于没有CPU限制的Pod来说,一旦空闲的CPU资源耗尽,之前分配的CPU资源量将逐渐减少。在这两种情况下,最终,Pod将无法处理外部请求,从而导致更长的延迟和响应时间。
(2)情况2
与其相反,内存资源无法压缩,并且Pod无法共享内存资源。这意味着如果内存耗尽,分配新的内存资源肯定会失败。
Pod中的某些进程专门在初始化时需要一定数量的内存。例如,JVM在启动时会应用一定数量的内存。如果指定的内存请求小于JVM应用的内存,则内存应用程序将会失败(OOM终止)。因此,这个Pod将继续重启并发生故障。
(3)情况3
在创建Pod时,Kubernetes需要以平衡和全面的方式分配或配置不同的资源,其中包括CPU和内存。与此同时,Kubernetes调度算法需要考虑多种因素,例如NodeResourcesLeastAllocated和Pod affinity。内存资源常常分布不均的原因是,对于应用程序来说,内存被认为比其他资源更稀缺。
此外,Kubernetes调度程序根据集群的当前状态工作。换句话说,当创建新的Pod时,调度程序会根据此时集群的资源规范为Pod选择一个最佳节点来运行。由于Kubernetes集群是高度动态的,因此在这里可能会发生潜在问题。例如,要维护一个节点,可能需要对其进行锁定,并且在该节点上运行的所有Pod都将被调度到其他节点。而出现的问题是,在维护之后,这些Pod不会自动安排回原始节点。这是因为Kubernetes本身无法将运行中的Pod重新绑定到另一个节点,也就无法将其重新调度到另一个节点。
优秀实践
从以上分析可以知道,集群稳定性直接影响应用程序的性能。暂时的资源短缺通常是导致集群不稳定的主要原因,而在云平台不稳定意味着应用程序出现故障,甚至节点出现故障。
以下介绍两种提高集群稳定性的方法:
首先,通过编辑Kubelet配置文件来保留一定数量的系统资源。当处理不可压缩的计算资源(例如内存或磁盘空间)时,这一点尤其重要。
其次,为Pod配置适当的服务质量(QoS)类。Kubernetes使用QoS类来确定Pod的调度和逐出优先级。可以为不同的Pod分配不同的QoS类,其中包括“Guaranteed”(最高优先级)、“Burstable”和“BestEffort”(最低优先级)。
- Guaranteed。Pod中的每个容器(包括init容器)都必须具有为CPU和内存指定的请求和限制,并且它们必须相等。
- Burstable。Pod中至少有一个容器具有为CPU或内存指定的请求。
- BestEffort。Pod中没有容器具有为CPU和内存指定的请求和限制。
注:使用Kubelet的CPU管理策略,可以为特定Pod设置CPU亲和性。
当资源耗尽时,集群将首先用BestEffort的QoS类终止Pod,然后是Burstable。换句话说,优先级最低的Pod首先终止。如果具有足够的资源,可以给所有的Pod分配一个Guaranteed类。这可以看作是计算资源与性能和稳定性之间的权衡。你可能期望采用更多的资源,但集群可以更高效地工作。与此同时,为了提高资源利用率,你可以将运行业务服务的Pod分配为Guaranteed类。对于其他服务,根据优先级为它们分配Burstable或BestEffort类别。
接下来,将以KubeSphere容器平台为例,了解如何更好地为Pod配置资源。
使用KubeSphere分配资源
如上所述,请求和限制是集群稳定性的两个重要组成部分。作为Kubernetes的主要发行版之一,KubeSphere拥有简洁、清晰、交互式的用户界面,极大地降低了Kubernetes的学习难度。
1.在开始之前做的工作
KubeSphere具有功能强大的多租户系统,可对不同用户进行细粒度的访问控制。在KubeSphere 3.0中,可以分别为名称空间(ResourceQuotas)和容器(LimitRanges)设置请求和限制。要执行这些操作,需要创建一个工作区、一个项目(即名称空间)和一个帐户(ws-admin)。
2.设置资源配额
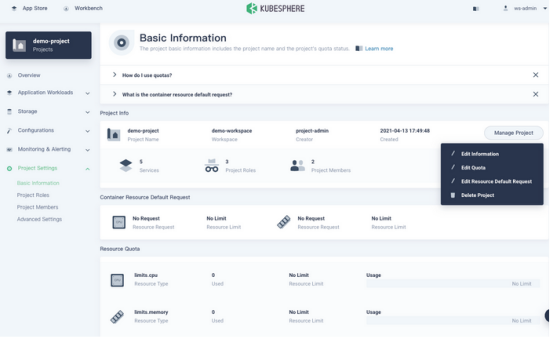
转到项目的“概述”页面,导航到“项目设置”中的“基本信息”,然后从“管理项目”下拉菜单中选择“编辑配额”。
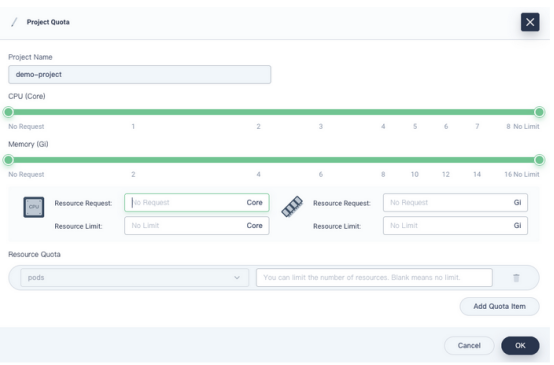
在出现的对话框中,为项目设置请求和限制。
需要记住:
- 在这个页面上设置的请求或限制必须大于为项目中所有Pod指定的总请求或限制。
- 在项目中创建容器而不指定请求或限制时,创建时将看到错误消息(记录在事件中)。
在配置项目配额后,需要为项目中创建的所有容器指定请求和限制。项目配额为所有容器设置了规则。
注:KubeSphere中的项目配额与Kubernetes中的ResourceQuotas相同。除了CPU和内存,还可以分别为其他对象(如Deployments和ConfigMaps)设置资源配额。
3.设置默认请求和限制
如上所述,如果指定了项目配额,则需要相应地配置Pod的请求和限制。实际上,在测试甚至生产中,请求的值和限制的值非常接近,甚至对于大多数Pod来说都是相等的。为了简化创建工作负载的过程,KubeSphere允许用户预先设置容器的默认请求和限制。这样无需在每次创建Pod时都设置请求和限制。
要设置默认请求和限制,需要执行以下步骤:
(1)同样在“基本信息”页面上,从“管理项目”下拉菜单中单击“编辑资源默认请求”。
在出现的对话框中,配置容器的默认请求和限制。
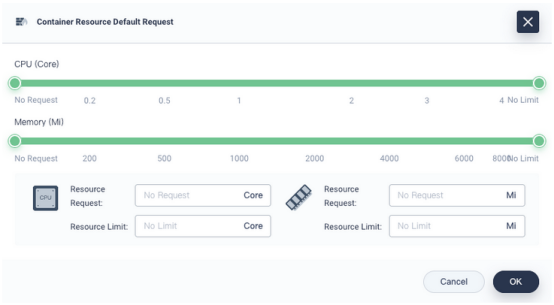
注:KubeSphere中的默认容器请求和限制在Kubernetes中称为LimitRanges。
(2)以后创建工作负载时,请求和限制将自动填充。
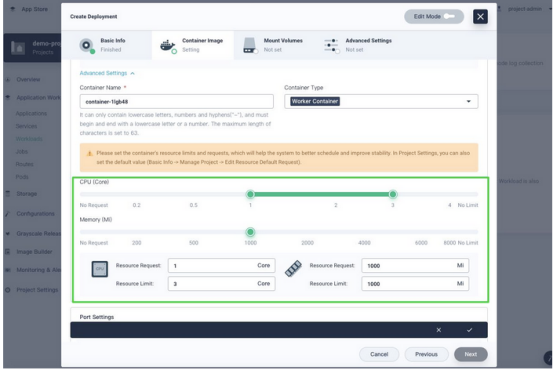
对于运行关键业务流程的容器,它们需要比其他容器处理更多的流量。实际上并没有什么万能的解决方案,你需要根据这些容器的要求和限制做出谨慎而全面的决定。因此需要考虑以下问题:
①容器是CPU密集型还是IO密集型?
②它们的可用性高吗?
③服务的上游和下游对象是什么?
如果长时间观察一些容器的运行,就会发现它是周期性的。因此,在配置请求和限制时,历史监视数据可以作为重要的参考。对于集成到平台中的Prometheus,KubeSphere具有强大而全面的可观察性系统,可以对资源进行更细致的监视。在纵向上,它涵盖了从集群到Pod的数据;在横向上,它跟踪有关CPU、内存、网络和存储的信息。通常情况下,可以基于历史数据的平均值来指定请求,而限制则需要高于平均值。也就是说,可能需要根据需要对最终决定进行一些调整。
源代码分析
现在已经了解了配置请求和限制的一些优秀实践,以下将更深入地研究源代码。
(1)请求和计划
以下代码显示了Pod的请求与Pod中容器的请求之间的关系。

从上面的代码可以看出,调度程序计算了要调度的Pod所需的资源。具体来说,它根据Pod规范分别计算初始化容器的总请求和工作容器的总请求,将会使用更大的一个。需要注意的是,对于轻量级虚拟机(例如kata容器),需要将自己的虚拟化资源消耗计入缓存中。在接下来的过滤阶段,将检查所有节点以查看它们是否满足条件。
注:调度过程需要不同的阶段,其中包括前置过滤器、过滤器、后置过滤器和评分。
在过滤之后,如果只有一个适用的节点,则会将Pod调度到该节点。如果有多个适用的Pod,则调度程序将选择加权分数总和最高的节点。计分插件的实现基于多种因素,调度插件实现一个或多个扩展点。需要注意的是,请求的值和限制的值直接影响插件NodeResourcesLeastAllocated的最终结果。以下是源代码:

对于NodeResourcesLeastAllocated,如果一个节点具有相同Pod的更多资源,则它将获得更高的分数。换句话说,一个Pod将更有可能被调度到具有足够资源的节点。
在创建Pod时,Kubernetes需要分配不同的资源,包括CPU和内存。每种资源都有权重(源代码中的resToWeightMap结构)。总体而言,它们告诉Kubernetes调度程序,最佳的决定可能是实现资源平衡。在评分阶段,除了NodeResourcesLeastAllocated外,调度程序还使用其他插件进行评分,例如InterPodAffinity。
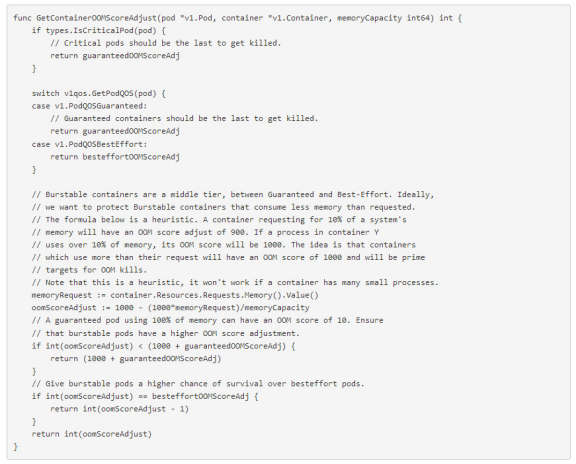
(2)QoS和调度
作为Kubernetes中的一种资源保护机制,QoS主要用于控制不可压缩的资源(例如内存)。它还会影响不同Pod和容器的OOM分数。当节点内存不足时,内核(OOM Killer)终止优先级较低的Pod(分数越高,优先级越低)。以下是源代码:
结语
作为一个可移植且可扩展的开源平台,Kubernetes诞生于管理容器化工作负载和服务。它拥有一个全面的、快速发展的生态系统,已经帮助其巩固了在容器编排中事实上的标准的地位。用户学习Kubernetes并不是那么容易,而这正是KubeSphere发挥作用的地方。 KubeSphere使用户可以在其仪表板上执行几乎所有操作,同时还可以选择使用内置的Web Kubectl工具来运行命令。本文重点介绍了请求和限制,它们在Kubernetes中的基本逻辑以及如何使用KubeSphere对其进行配置以简化集群的操作和维护。
原文标题:Dive Deep Into Resource Requests and Limits in Kubernetes,作者:Sherlock Xu
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】