













对于科研人开心莫过于paper被「Accept」,发表后你的论文影响力如何?你所研究领域在未来潜力怎么样?......现在,机器学习「突破」传统评价标准,将以一种新方式去诠释。
目前,有许多基于论文引用的度量指标,比如引用次数、h指数、期刊影响因子等。这些指标不仅是论文质量的次优指标,而且还会影响后续学术招聘、晋升和资金筹措方面的次优决策等。
而这些指标只能提供不完善的、不一致的且易于操纵的研究质量度量。随着机器学习的兴起,可以从更多角度去评判他们发表研究的潜在影响力
基于此,美国麻省理工学院(MIT)的研究人员建立了一个名为DELPHI(Dynamic Early-warning by Learning to Predict High Impact,通过学习预测高影响实现动态预警)的人工智能框架,可以通过学习以前的科学出版物中的模式,为未来的高影响力技术提供「预警」信号。并解锁大量现有的但尚未开发的资源。以更有效、更公平的方式分配有限的资源,从而提高集体部署到科学中的资源回报率和技术。
该研究于5月17日以题为「 Learning on knowledge graph dynamics provides an early warning of impactful research 」发表在《自然•生物技术》( Nature Biotechnology )杂志上。

科学事业的有效发展取决于在一组有前途的研究人员和项目中识别和优化分配资源的集体能力。反过来,此过程主要取决于直接采用的分配方法,这种分配方法间接地通过雇用、晋升和社论出版物进行。
数字科学语料库的规模激增,有助于开发新的数据驱动方法。从人工智能到现代科学企业产生的大量数据的方法应用,可提供更早或更有意义的新科学影响和创新信号。
数据驱动的算法将消化现有的大量高维数字科学信息,产生有意义的低维信号,然后将其与人类专业知识和直觉相结合。此外,这样的方法可以包含多个目标函数,可扩展到一系列期望的结果上。
此前的研究已经证明从知识图中提取信号的价值。但是,目前还没有框架将这些方法与人工智能方法相结合,从而使我们能够从过去中学到东西,以提高我们识别未来最具影响力的科学技术的能力。
本研究提出一个机器学习框架DELPHI,通过分析科学文献中计算的一系列特征之间的高维关系,预测可能产生高影响力的工作。研究人员使用的数据集包含1980-2019年期间发表的1,687,850篇研究论文(42种与生物技术相关的期刊),从中得到了论文发表后1-5年与每篇论文、作者、期刊、网络相关的29个特征。再用每篇论文的特征训练一个机器学习模型,让这个模型给出影响力「预警」信号。
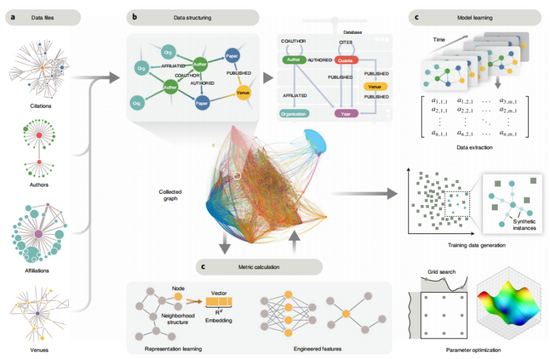
从动态知识图中收集、构建、计算和学习科学影响预警信号。(来源:论文)
研究人员使用DELPHI预测了到2023年将产生巨大影响的50篇最新科学论文。论文涵盖的主题包括:用于癌症治疗的DNA纳米机器人、高能量密度锂氧电池和利用深层神经网络的化学合成。
「本质上,我们的算法通过从科学史中学习模式,然后在新出版物上进行模式匹配来发现有高影响力的早期信号,」 Weis说。「通过追踪思想的早期传播,我们可以预测它们以有意义的方式传播到更广泛的学术界的可能性有多大。」
预测潜在影响力
Weis和Jacobson开发的机器学习算法利用了自1980年代以来科学出版物呈指数增长的大量数字信息。但DELPHI并没有使用诸如引用次数之类的一维度量来判断出版物的影响,而是接受了期刊文章元数据的完整时间序列网络的培训,以揭示其在整个科学生态系统中的高维分布。
结果是一个知识图,包含代表论文、作者、机构和其他类型数据的节点之间的连接。这些节点之间复杂连接的强度和类型决定了它们在框架中使用的属性。「这些节点和边定义了一个基于时间的图形,DELPHI使用它来学习预测未来高影响的模式。」 Weis解释说。
论文在发表5年后在时间尺度节点中心位置的前5%的论文被认为DELPHI旨在识别的「高度影响」目标集。前5%的论文占图表总影响力的35%。

可视化的低影响力和高影响力出版物的共同作者和引文网络结构的比较演变。(来源:论文)
与引文数量相比,DELPHI识别出的高度影响力的论文的数量是其两倍多,包括60%的「隐藏宝石」或被引文阈值遗漏的论文。
研究人员惊讶地发现,在某些情况下,使用DELPHI能够显示出高影响力的论文「警报信号」时间如此之早。「在发布的一年内,我们已经确定了『隐藏宝石』,这些『宝石』将在以后产生重大影响。」 Weis说。
他警告说,「但DELPHI并不能完全预测未来。我们正在使用机器学习来提取和量化隐藏在现有数据的维度和动态中的信号。」
公平、高效
过去,论文影响力的衡量标准(如引文和期刊影响因子等指标)都可以被操纵,研究人员说,「希望DELPHI将提供一种偏见更少的方式来评估论文的影响力。」
Weis说,「与所有机器学习框架一样,设计人员和用户应警惕偏见。我们需要不断意识到数据和模型中的潜在偏差。我们希望DELPHI能够以较少偏见的方式帮助找到最佳的研究——因此,我们需要注意,我们的模型不能仅根据次优指标(例如h-Index,作者引用计数或机构隶属关系)来预测未来的影响。」
Weis在为生物技术初创公司启动风险投资基金和实验室孵化设施之后,思考了很多的问题。
他说:「我越来越意识到,包括我自己在内的投资者一直在相同的地点,以相同的观念来寻找新公司。」 「我开始瞥见大量的人才和惊人的技术,但这常常被忽视。我认为一定有一种方法可以在这个领域工作——机器学习可以帮助我们发现并更有效地实现所有这些未被挖掘的潜力。」
参考内容:
https://news.mit.edu/2021/using-machine-learning-predict-high-impact-research-0517
论文链接:
https://www.nature.com/articles/s41587-021-00907-6


















