本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
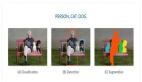
正如大家所知,在进行图像语义分割时,图像被编码成一系列补丁后往往很模糊,需要借助上下文信息才能被正确分割。
因此上下文建模对图像语义分割的性能至关重要!
而与以往基于卷积网络的方法不同,来自法国的一个研究团队另辟蹊径,提出了一种只使用Transformer的语义分割方法。
 最先进的卷积方法">
最先进的卷积方法">该方法“效果拔群”,可以很好地捕捉图像全局上下文信息!
 最先进的卷积方法">
最先进的卷积方法">要知道,就连取得了骄人成绩的FCN(完全卷积网络)都有“图像全局信息访问限制”的问题。(卷积结构在图像语义分割方面目前有无法打破的局限)
而这次这个方法在具有挑战性的ADE20K数据集上,性能都超过了最先进的卷积方法!
不得不说,Transformer跨界计算机视觉领域真是越来越频繁了、效果也越来越成功了!
那这次表现优异的Transformer语义分割,用了什么不一样的“配方”吗?
使用Vision Transformer
没错,这次这个最终被命名为Segmenter的语义分割模型,主要基于去年10月份才诞生的一个用于计算机视觉领域的“新秀”Transformer:Vision Transformer,简称ViT。
ViT有多“秀”呢?
ViT采用纯Transformer架构,将图像分成多个patches进行输入,在很多图像分类任务中表现都不输最先进的卷积网络。
缺点就是在训练数据集较小时,性能不是很好。
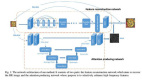
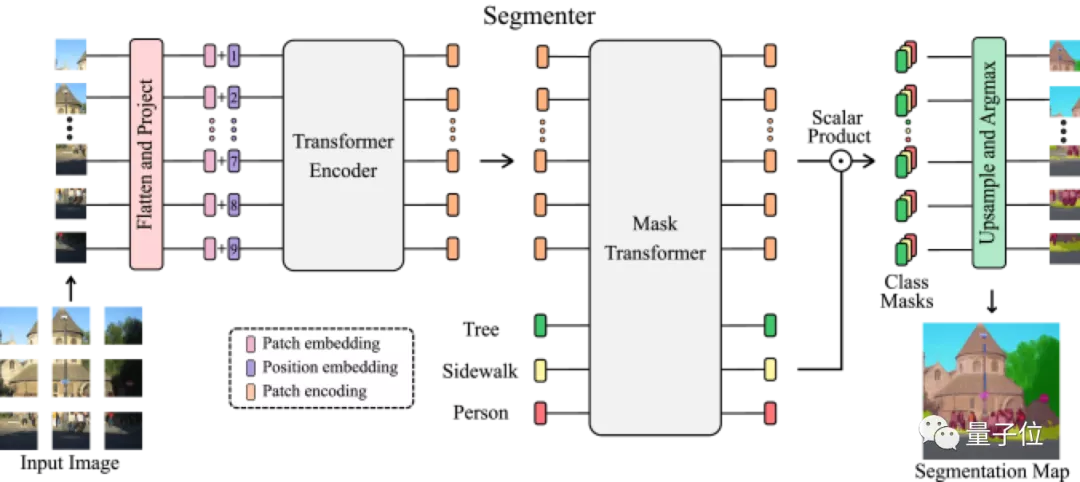
Segmenter作为一个纯Transformer的编码-解码架构,利用了模型每一层的全局图像上下文。
基于最新的ViT研究成果,将图像分割成块(patches),并将它们映射为一个线性嵌入序列,用编码器进行编码。再由Mask Transformer将编码器和类嵌入的输出进行解码,上采样后应用Argmax给每个像素一一分好类,输出最终的像素分割图。
下面是该模型的架构示意图:
 最先进的卷积方法">
最先进的卷积方法">解码阶段采用了联合处理图像块和类嵌入的简单方法,解码器Mask Transformer可以通过用对象嵌入代替类嵌入来直接进行全景分割。
效果如何
多说无益,看看实际效果如何?
首先他们在ADE20K数据集上比较不同Transformer变体,研究不同参数(正则化、模型大小、图像块大小、训练数据集大小,模型性能,不同的解码器等),全方面比较Segmenter与基于卷积的语义分割方法。
其中ADE20K数据集,包含具有挑战性的细粒度(fine-grained)标签场景,是最具挑战性的语义分割数据集之一。
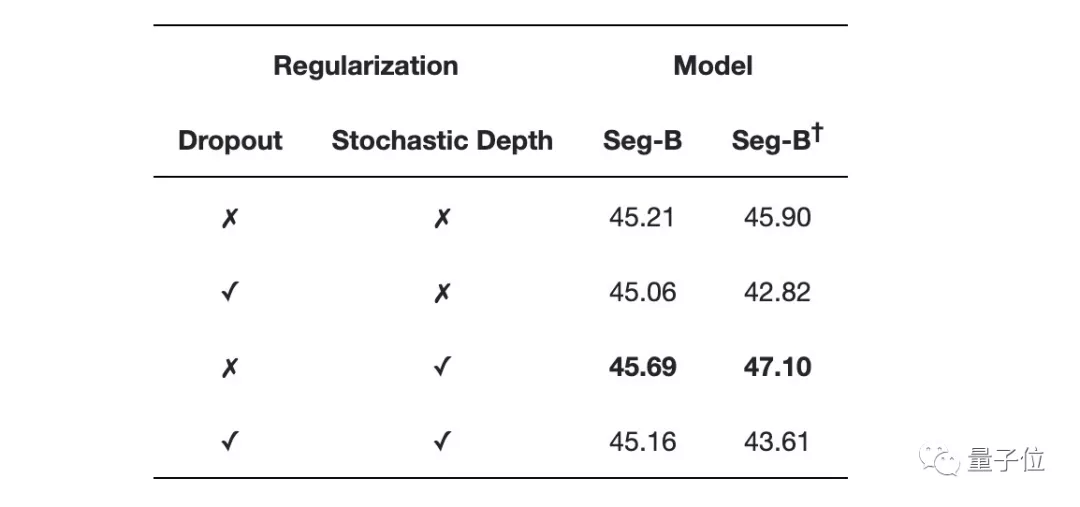
下表是不同正则化方案的比较结果:
他们发现随机深度(Stochastic Depth)方案可独立提高性能,而dropout无论是单独还是与随机深度相结合,都会损耗性能。
 最先进的卷积方法">
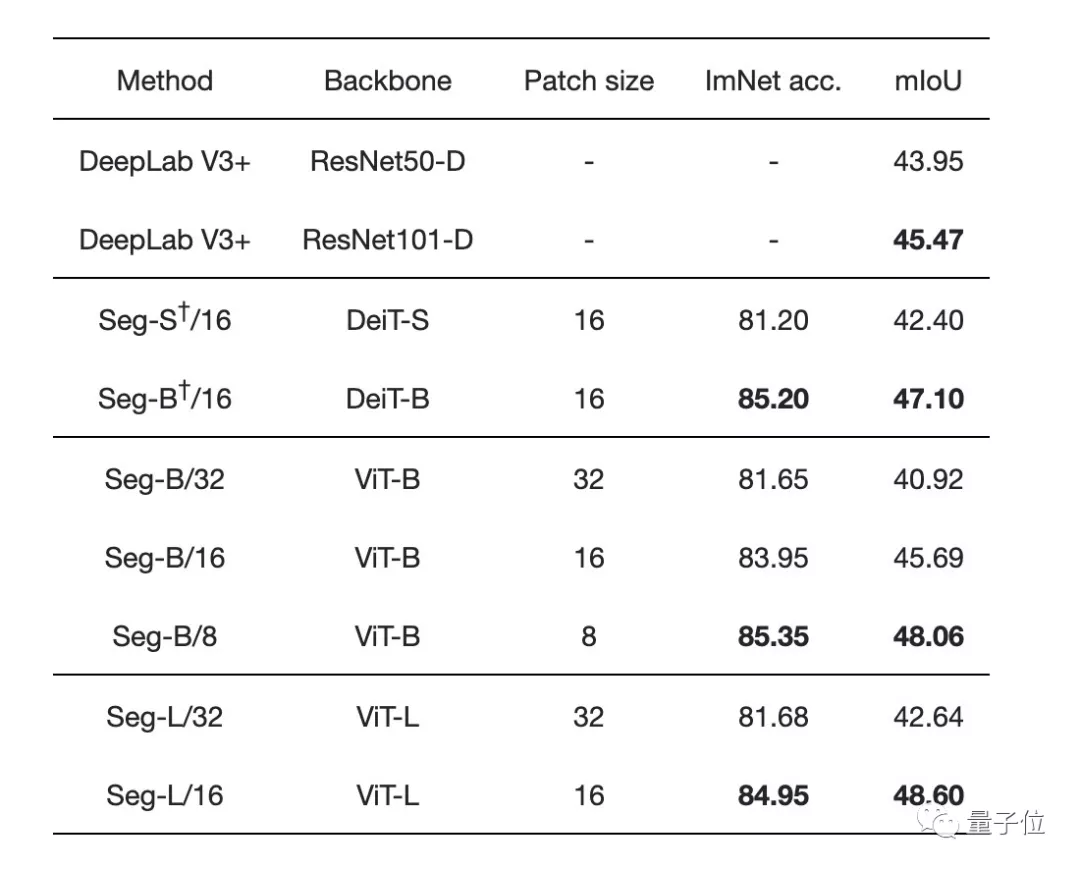
最先进的卷积方法">不同图像块大小和不同transformer的性能比较发现:
增加图像块的大小会导致图像的表示更粗糙,但会产生处理速度更快的小序列。
减少图像块大小是一个强大的改进方式,不用引入任何参数!但需要在较长的序列上计算Attention,会增加计算时间和内存占用。
 最先进的卷积方法">
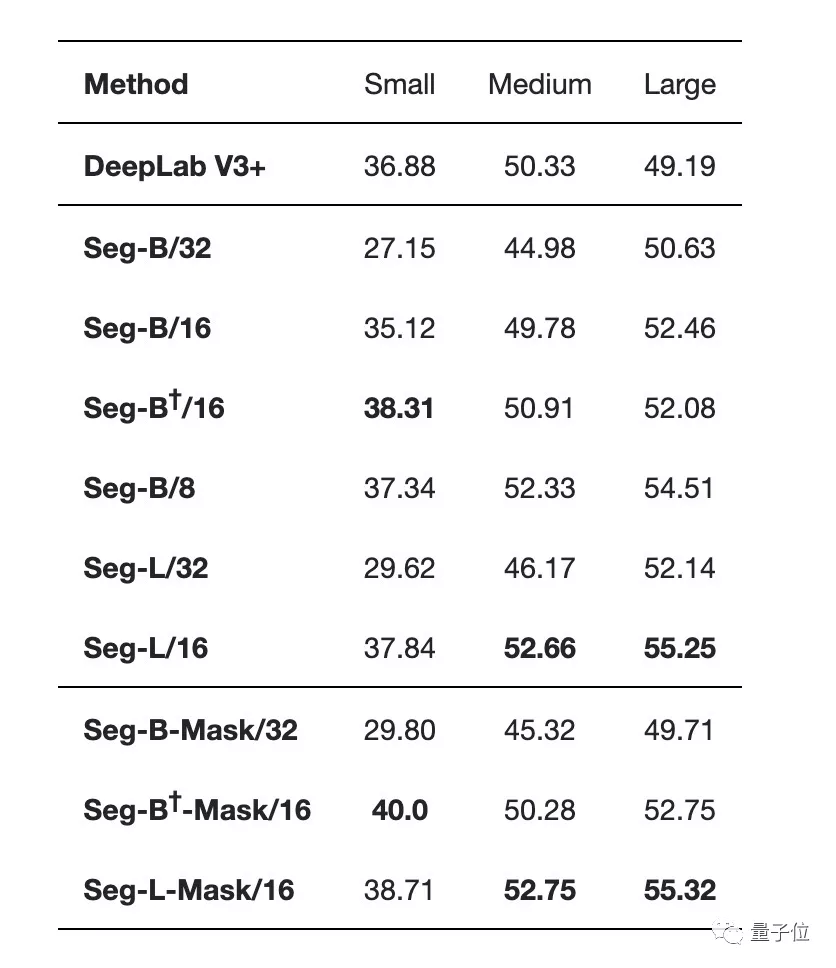
最先进的卷积方法">Segmenter在使用大型transformer模型或小规模图像块的情况下更优:
 最先进的卷积方法">
最先进的卷积方法">(表中间是带有线性解码器的不同编码器,表底部是带有Mask Transformer作为解码器的不同编码器)
下图也显示了Segmenter的明显优势,其中Seg/16模型(图像块大小为16x16)在性能与准确性方面表现最好。
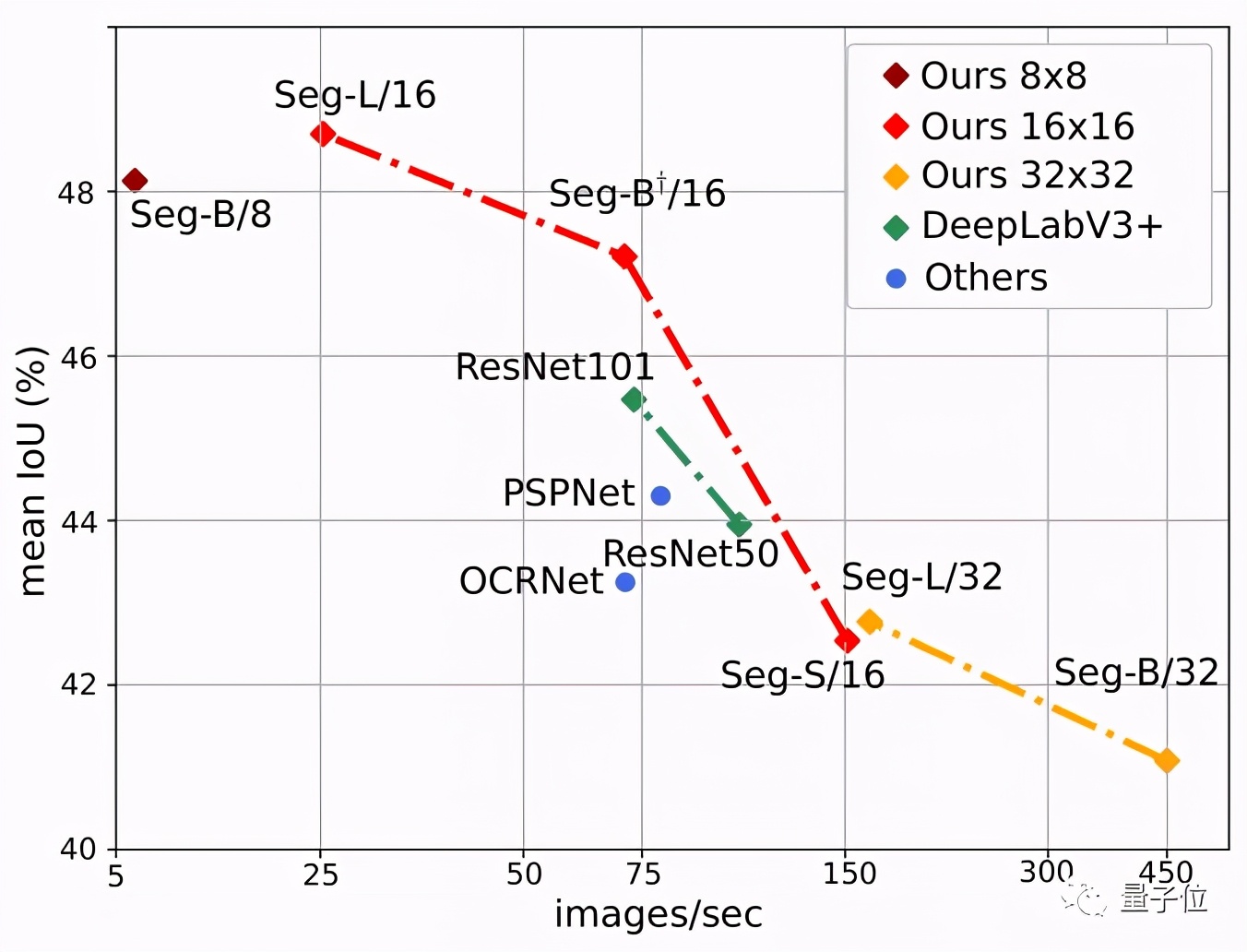 最先进的卷积方法">
最先进的卷积方法">最后,我们再来看看Segmenter与SOTA的比较:
在最具挑战性的ADE20K数据集上,Segmenter两项指标均高于所有SOTA模型!
 最先进的卷积方法">
最先进的卷积方法">(中间太长已省略)
 最先进的卷积方法">
最先进的卷积方法">在Cityscapes数据集上与大多数SOTA不相上下,只比性能最好的Panoptic-Deeplab低0.8。
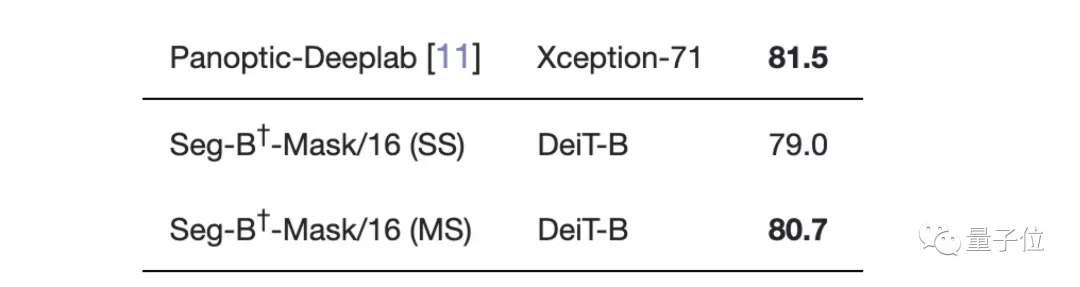 最先进的卷积方法">
最先进的卷积方法">在Pascal Context数据集上的表现也是如此。
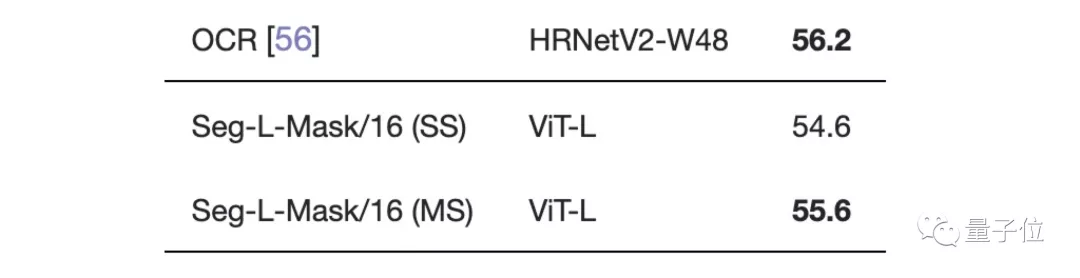 最先进的卷积方法">
最先进的卷积方法">剩余参数比较,大家有兴趣的可按需查看论文细节。
论文地址:
https://www.arxiv-vanity.com/papers/2105.05633/