作者:datonli,腾讯 WXG 后台开发工程师
背景
开发在定位问题时需要查找日志,但企业微信业务模块日志存储在本机磁盘,这会造成以下问题:
- 日志查找效率低下:一次用户请求涉及近十个模块,几十台机器,查找日志需要登录机器 grep 日志文件。这一过程通常需要耗费 10 分钟以上,非常低效;
- 日志保存时间短:单机磁盘存储容量有限,为保存最新日志,清理脚本周期清理旧日志文件腾出磁盘空间,比如:现网一核心存储 7 天日志占用了 90%的磁盘空间,7 天前日志都会被清理,用户投诉因日志被清理而得不到解决;
- 日志缺失:虽然现网保留 7 天最新日志,但是由于某些模块请求量大或日志打印不合理,我们也会限制一个小时日志打印量,超过阈值后不再保存,比如:现网一核心存储前 10 分钟打了 10G 日志达到阈值,后 50 分钟日志不再保存了,用户投诉因日志缺失无法得到解决。
我们希望有这样一个日志系统:
- 存储全量日志:由于 To B 业务的特殊性,至少需要保存 30 天的全量日志(数 PB 日志量,日志达数万亿条),方便回查日志定位问题;
- 日志快速定位:根据模块+时间段+关键字或用户请求信息快速定位日志;
- 实时性:日志峰值达数亿条每秒,需要做到秒级入库、秒级可查;
- 支持日志模糊匹配和统计:单机日志查询常用到模糊匹配以及 awk/uniq/sort 等复杂统计,在新日志系统同样希望能够支持;
- 支持模块级全量日志查询:日常运营中有些用户投诉的问题并不确定具体发生时间,需要对模块进行全量日志(日志量达 TB 级别)查询。
业界方案对比
公司内外有很多日志系统方案,根据是否对日志做全文检索可以分为两类:
- 全文检索的日志系统:对日志内容切分词和建倒排,通过查询关键词的倒排取交集支持模糊匹配,这类系统一般入库资源消耗较多,也不支持日志统计,典型实现有:ELK、Hermes 以及腾讯云日志服务(Cloud Log Service, CLS)等系统;
- 部分字段检索的日志系统:只对部分字段建索引,支持特定字段的快速检索,入库资源消耗较低,但是这类系统对模糊匹配未能很好支持,也不支持日志统计,不支持模块级全量日志查询,如 wxlog、LogTrace 等系统。
我们新设计的检索系统在资源消耗较小的前提下,很好满足背景所提的所有检索需求。
方案设计的考虑
保存时间短和日志缺失的问题
单机存储空间的限制导致日志丢失,日志也没法长时间保存,如何突破单机存储空间限制呢?
嗯,是的,使用分布式文件系统替换单机文件系统就可以了!在可水平扩展的分布式文件系统支撑下,存储空间无限大,日志不再因存储空间而丢失了。
日志查找效率低下问题
日志查找效率低下,其根源是日志散落到多台机器,需要登录到机器做日志 grep。引入了分布式文件系统存储全网日志后,我们看到的仍然是一个一个不相关的日志文件,快速定位日志仍然困难。如何提高日志定位的效率呢?
索引!就像是利用索引提升数据库表查询效率一样,我们对日志数据建立索引,快速定位到所需日志。那么,需要构建怎样的索引呢?先看看面临的两种问题定位场景:
- 开发收到模块告警,通过告警信息结合代码找到关键字,使用关键字查找模块告警时间段内的日志;
- 根据用户投诉找到用户请求信息,使用用户请求信息查找所有关联模块的日志。从以上场景看出,我们通常根据模块+时间段+关键字或者用户请求信息查找日志。所以,对模块、时间、用户请求信息建索引提升日志查找效率。
入库资源消耗问题
为了支持模糊查询,业界方案一般都会对日志内容分词建索引,这会消耗大量资源。日志查询系统有两个特点:每天只有数百次查询请求,日志存储模块(分布式文件系统)IO 密集、CPU 利用率低。为了支持用户模糊查询请求,入库时不对日志内容分词建索引。用户查询时,日志存储模块使用关键字对日志内容正则匹配过滤(利用本机空闲 CPU)。这样既解决了入库资源消耗高的问题,又解决了存储机 CPU 低利用率的问题。
面临的挑战
我们通过分布式文件系统和索引解决了目前的问题,同时也带来了新的挑战:
高性能:目前企业微信日志量月级数 PB,日志数万亿条,天级数百 TB,面对如此海量日志,如何做到入库和查询的高性能?
可靠性:引入了分布式文件系统以及索引带来更大的复杂性,如何保证整个日志系统可靠性?
支持灵活多变的用户查询需求:通过调研发现,用户主要有以下 4 种日志查询使用场景:a) 一次用户请求关联的所有模块日志查询;b) 模块一段时间内日志模糊查询;c) 模块全量日志模糊查询;d) 查询日志统计(如:awk/uniq/sort 指令等)。如何支持如此灵活多变的用户查询需求?
名词解释
在介绍系统前,先对使用的名词进行解释:
callid:唯一标识一次用户请求,每条日志中都会携带 callid 信息;
模糊查询:根据用户输入模块、时间段和关键字查询日志;
全链路查询:根据 callid 查询一次用户请求所有关联的模块日志。
系统架构
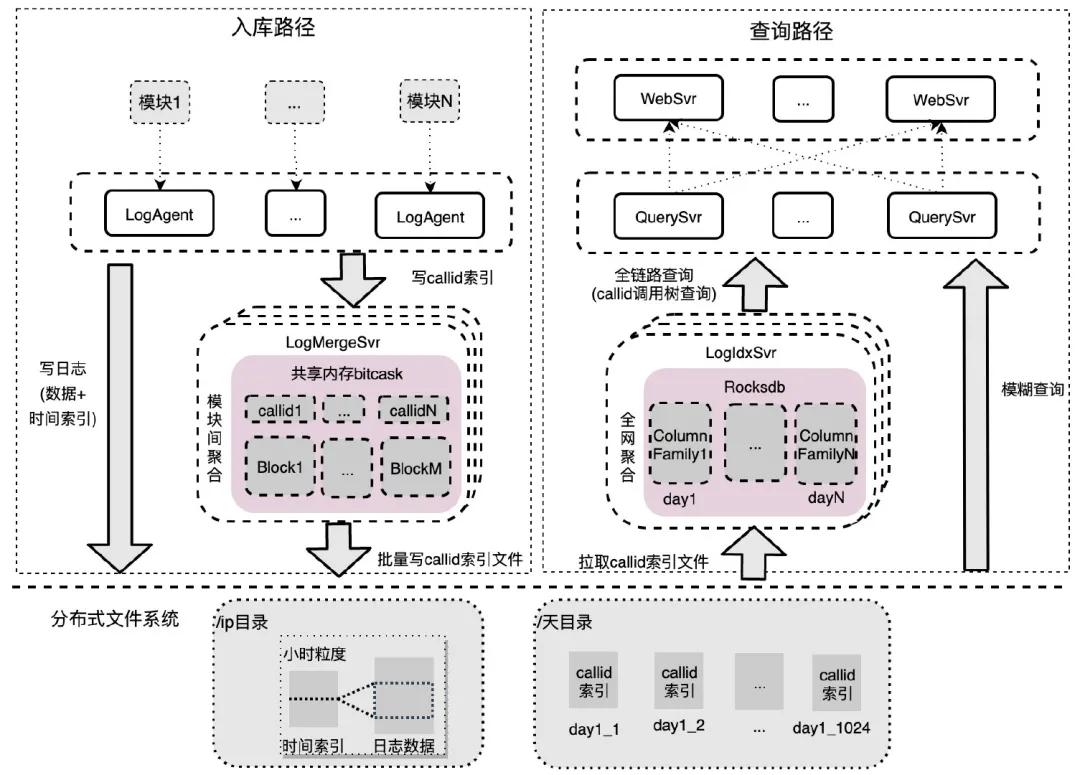
企业微信日志检索系统主要分为 6 个模块:
- LogAgent:和业务模块同机部署,对模块内日志进行聚集,数据批量写分布式文件系统,callid 索引批量发送到 LogMergeSvr 聚集;
- LogMergeSvr:对一段时间内的 callid 索引进行模块间聚集,批量写分布式文件系统;
- 存储模块(分布式文件系统):存储原始日志数据、时间索引和 callid 索引数据;
- LogIdxSvr:对 callid 索引进行全网聚合,底层存储用的是 Rocksdb;
- WebSvr:接收用户网页请求,并发查询 QuerySvr。
- QuerySvr:查询执行模块,支持全链路查询、模糊查询、awk 统计等。
接下来分别阐述系统设计和实现中面临的挑战点以及解决办法。
如何实现系统高性能
日志入库高性能
目前,企业微信全网日志入库峰值 qps 数亿条每秒,而分布式文件系统数据节点仅仅 20 台(单台 12 块 SATA 盘,单盘 IOPS 约 100 左右),我们如何使用少量数据节点支撑如此高峰值的日志秒级入库呢?
数据入库高性能
在模糊查询场景下,用户使用模块/机器+时间段+关键字进行查询。为提升数据入库性能,我们以每台机器的 IP 作为分布式文件系统的目录,机器上模块打印的日志写入小时粒度的日志文件,这样不同机器写入自己独占的日志数据文件,相互间数据写入无竞争,入库性能最佳。与此同时,目录结构就相当于一个快速区分不同模块/机器的索引,这也能提升日志查询效率。
为了进一步提升数据入库性能,LogAgent 使用缓冲队列缓存日志数据,累积 8MB 数据后批量顺序写入日志文件中,写 qps 降低为原本的 4 万分之一。同时为了快速查找日志数据,对 8MB 日志数据的时间戳采样,批量写入同目录下的时间索引文件中。
callid 索引入库高性能
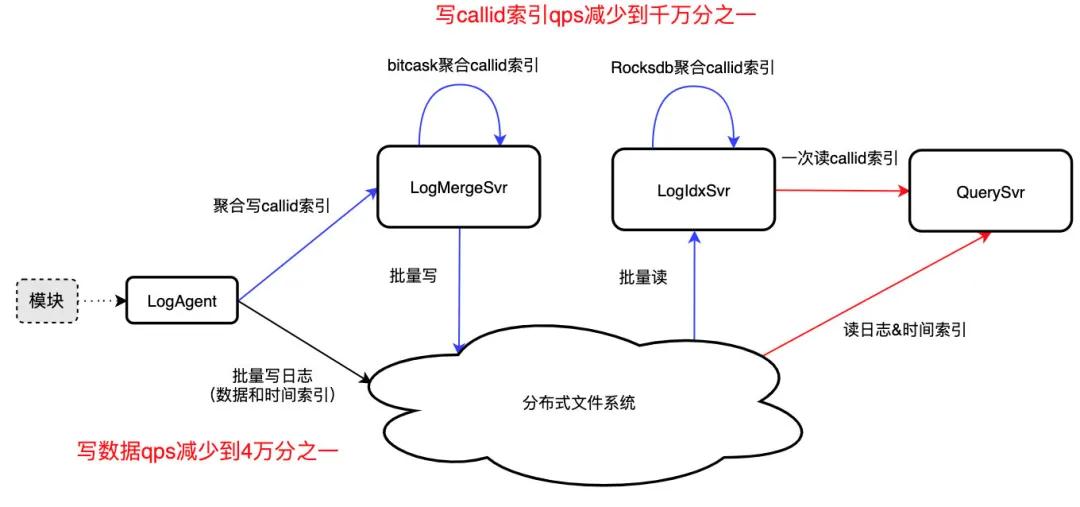
同一 callid 索引散落在不同模块不同机器,为了全链路查询,需要对数亿条/秒的 callid 索引做秒级聚合,以支持秒级入库、秒级可查,这无疑是一个技术难题。
为了解决这一难题,我们通过三重聚合减少 callid 索引写入压力,最终达到 qps 减少到千万分之一、一次 IO 读取 callid 所有日志位置的效果:
- 模块内聚合:LogAgent 聚合模块内 callid 索引,批量写入 LogMergeSvr,qps 约减少到万分之一;
- 模块间聚合:LogMergeSvr 聚合模块间一段时间内的 callid 索引,批量写分布式文件系统,qps 约减少到千分之一;
- 全网聚合:callid 索引文件不利于高效读取,LogIdxSvr 利用 Rocksdb 的 Merge 聚合全网的 callid 索引,一次 IO 可读取 callid 所有日志位置。
日志查询高性能
增加索引提升查询性能
开发通常依据模块、时间段、callid 这 3 个维度查询日志,为了加快查询性能也对这 3 个维度分别增加索引:
- 模块:一个模块包含若干机器,每台机器在分布式文件系统中拥有独占的日志目录(用 IP 区分),用于保存机器小时粒度日志文件。通过模块找到所有机器 IP 后,可快速找到该模块的日志在分布式文件系统中的日志目录。
- 时间段:日志数据保存在机器目录的小时粒度文件中,通过对日志时间采样保存为相应时间索引文件。当按照时间段查找日志时,可根据时间索引文件快速找到该时间段的日志位置范围。
- callid:解析日志建立 callid 到日志位置的索引,散落在多个模块的 callid 索引通过 LogAgent、LogMergeSvr 以及 LogIdxSvr 三重聚合后,最终存储在 LogIdxSvr 的 Rocksdb 中。全链路日志查询可通过读取一次 Rocksdb 获取所有相关日志位置,快速读取到所需日志。
模糊查询高性能
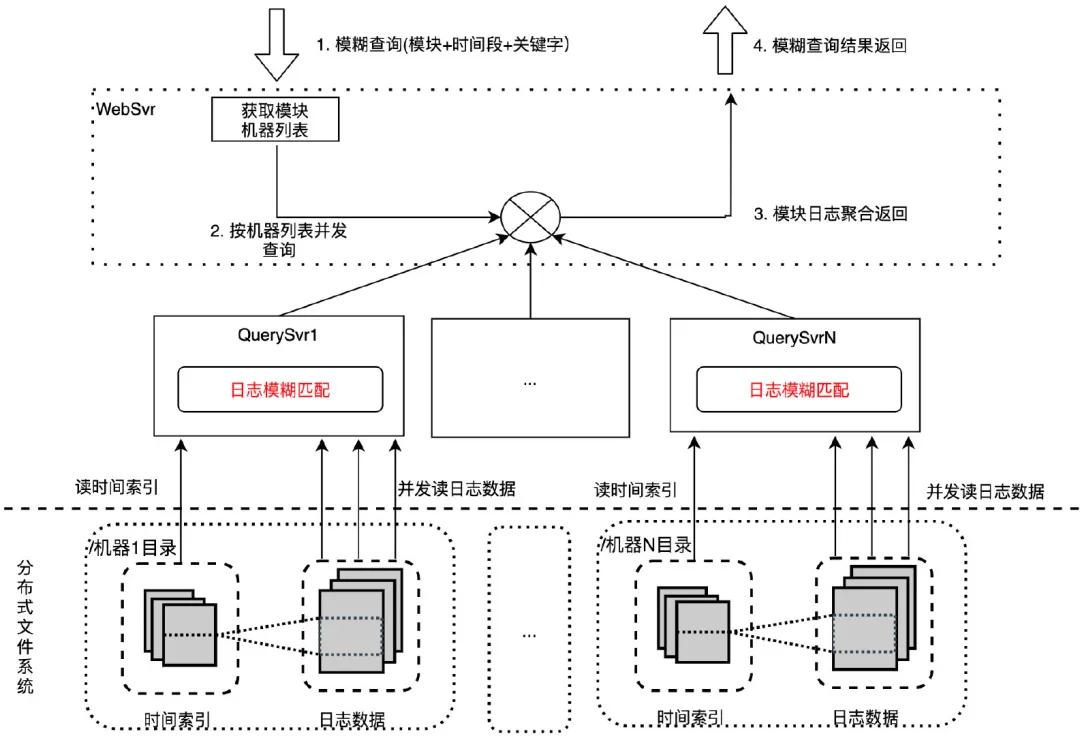
原始版本:并发检索 WebSvr 接收用户模糊查询请求(模块+时间段+关键字),依据模块获取机器列表后,按机器列表并发请求到多台 QuerySvr 执行机器粒度日志查询:通过机器 IP 找到机器日志目录,根据时间段拉取时间索引文件,确定日志数据范围,并发拉取日志到本机用关键字做模糊匹配。最终将匹配后的日志返回给 WebSvr 聚合展示给用户。
通过并发检索的优化手段,模糊查询一个模块一小时日志(12 台机器,7.95GB 日志量)耗时从 1 分钟降到 5.6 秒。
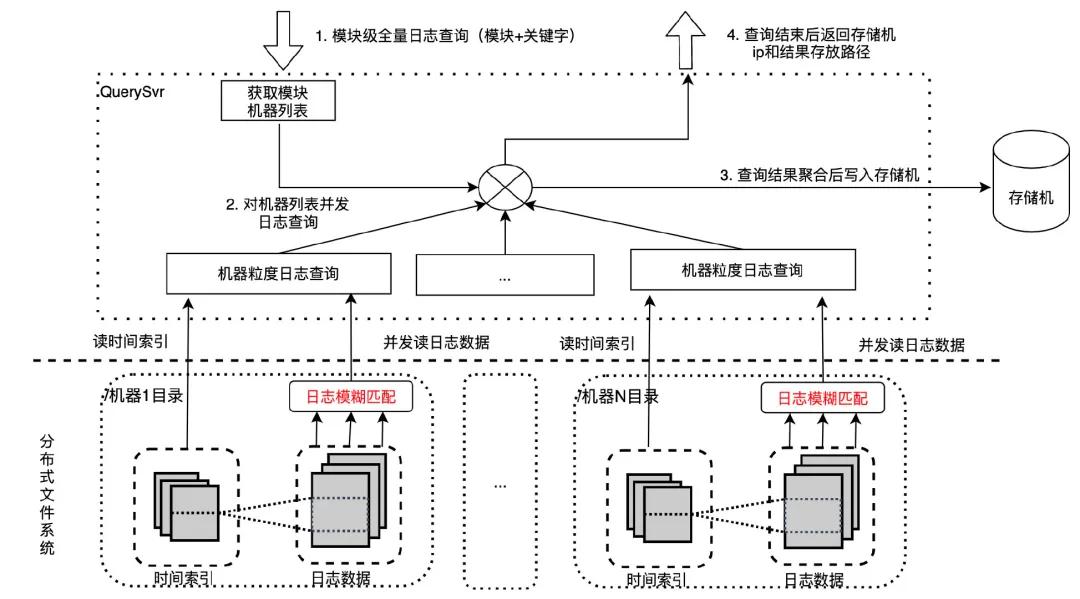
优化版本:模糊匹配下沉分布式文件系统 在系统压测时我们发现 QuerySvr 带宽和 cpu 存在性能瓶颈,原因是 QuerySvr 读取大量未模糊匹配的日志数据,打满了网络带宽,并且在 QuerySvr 做模糊匹配也会消耗大量 cpu 资源。我们需要进行性能优化。考虑到分布式文件系统是重 IO 操作,cpu 利用率很低,将模糊匹配逻辑下沉到分布式文件系统,这样既解决了 QuerySvr 带宽和 cpu 性能瓶颈问题,又充分利用了文件系统的 cpu,避免资源浪费。通过模糊匹配下沉的优化手段,模糊查询一个模块一小时日志(12 台机器,7.95GB 日志量)耗时从 5.6 秒降到 2.5 秒。
全链路查询高性能
全链路查询和模糊查询类似,同样利用了并发提升查询性能,稍有不同的是全链路查询根据 callid 读取 LogIdxSvr 确定日志位置列表,按照位置列表并发读取日志数据,聚合后将日志返回给用户。
如何保证系统可靠性
我们通过引入了分布式文件系统和索引服务解决了日志丢失、保存时间短和快速定位问题,但系统复杂性导致的可靠性问题,是我们面临的第二大挑战。
数据可靠性保证
日志数据缓冲队列(共享内存+本机磁盘文件)
LogAgent 负责将日志数据和时间索引写入分布式文件系统,当分布式文件系统抖动时,为了不丢弃待写日志数据,LogAgent 使用缓冲队列(共享内存+本机磁盘文件)缓存日志数据,待抖动恢复后读出缓存数据写入文件系统。
索引可靠性保证
服务抖动 LogIdxSvr 使用 Rocksdb 作为底层存储聚合全网 callid 索引,但是 Rocksdb 在高并发写入时容易出现写入抖动进而导致索引丢失,为了保证 callid 索引可靠性,LogMergeSvr 先将 callid 索引写入分布式文件系统保存,LogIdxSvr 从分布式文件系统拉,分布式文件系统当做 queue 使用起到削峰填谷作用,保证 callid 索引可靠性。
机器坏盘 LogIdxSvr 出现坏盘会导致已聚合到本机的 callid 索引数据丢失,新起的 LogIdxSvr 重新拉取分布式文件系统的 callid 索引文件,可以重建 Rocksdb 的 callid 索引,保证系统可靠性。
如何支持灵活多变的用户查询请求
通过前面的设计,目前可以根据模块+时间段+关键字或者 callid 查找到日志了,但是还不够,用户往往还需要对日志做任意维度模糊匹配、日志统计(如:uniq/sort/awk 等)以及模块级全量日志查询。
支持任意维度模糊匹配
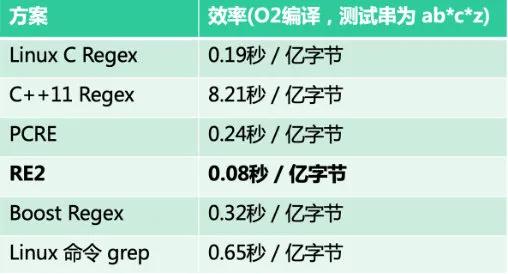
如前所述,通过在分布式文件系统实现模糊匹配逻辑,系统支持对日志做任意维度模糊匹配的需求。通过对比,选择性能最优的 RE2 正则匹配库实现模糊匹配逻辑。
支持 awk/uniq/sort 等统计指令
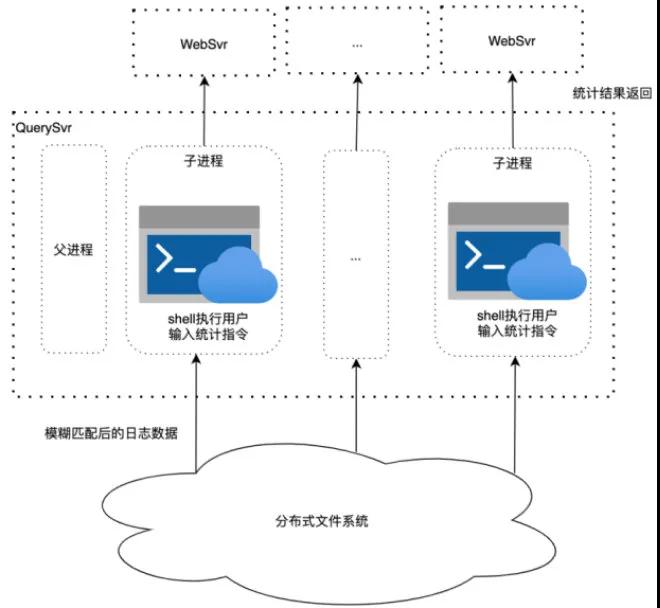
支持统计指令 用户不仅需要对日志做模糊匹配,还需要对匹配后的日志执行 awk/uniq/sort 等统计指令,其中涉及到指令相互嵌套执行,非常复杂,难以调用相关库实现。我们通过子进程调用系统 shell 支持这一需求。QuerySvr 从分布式文件系统拉取日志数据到本机后,子进程 shell 调用用户传入统计指令处理日志数据,最终结果返回给 WebSvr。子进程处理超时父进程将 kill 掉子进程,防止用户统计任务耗光 QuerySvr 资源。
安全考虑 由于用户指令可由用户自定义输入,指令执行的安全问题需要重点考虑。通过两个方法确保执行指令的安全:
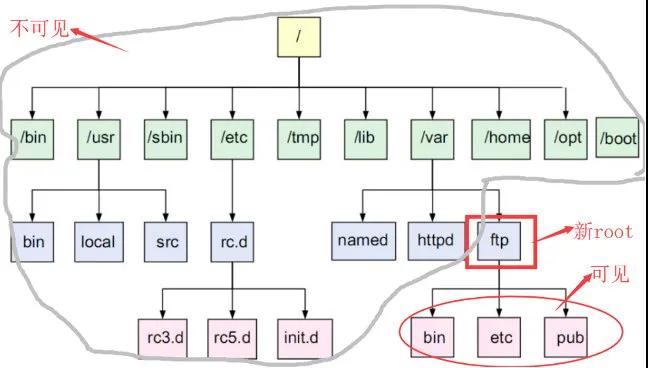
changeroot:使用 Linux 的 changeroot 避免用户指令操作系统重要目录;
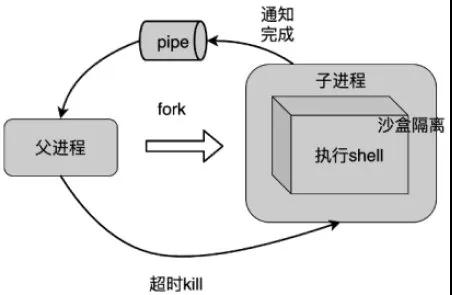
沙盒限制:使用 Linux 支持的沙盒隔离技术,只允许执行特定指令。
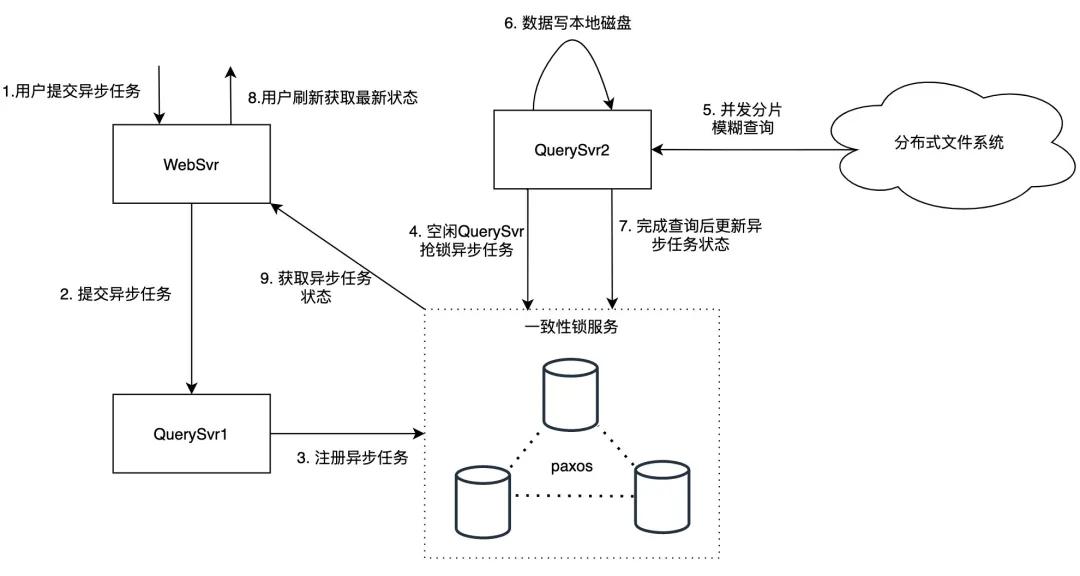
支持模块级全量日志查询——异步任务
模块级全量日志查询通常涉及 TB 级别日志量,因为涉及的数据量过大,查询耗时一般较长,无法给用户提供实时返回,我们通过提供异步任务功能支持这一需求。
用户异步任务请求通过 WebSvr 转发到 QuerySvr,为避免 QuerySvr 宕机导致异步任务丢失,QuerySvr 会将异步任务写入一致性锁服务中存储,空闲的 QuerySvr 会从一致性锁服务抢锁,抢锁成功后执行该异步任务。
QuerySvr 根据异步任务的模块信息读取机器列表,按照机器列表并发读取匹配的日志数据,按顺序写入本机磁盘中,在查询结束后更新一致性锁服务状态(存储机 ip 和路径),用户页面刷新会拉取到异步任务最新状态。