当前,深度学习在越来越多的任务上超越了人类,涉及的领域包括游戏、自然语言翻译、医学图像分析。然而,电子处理器上训练和运行深度神经网络的高能量成本阻碍了深度学习的进步空间。因此,光学神经网络代替深度学习物理平台的可行性受到了广泛的关注。
理论上,光学神经网络比部署在常规数字计算机上的神经网络具有更高的能源效率。在最近的一项研究中,来自美国康奈尔大学等的研究者们证明了,光学神经网络可实现在手写数字分类上的极高准确度:其中,在权重相乘中使用约 3.2 个检测到的光子使得准确度达到了 99%,而仅使用约 0.64 个光子(约 2.4×10^-19 J 光能)就能达到 90%以上的准确度。

论文链接:https://arxiv.org/pdf/2104.13467.pdf
该研究的实验结果是通过自定义的自由空间光学处理器所实现的,该处理器可以执行大规模并行矩阵矢量乘法运算,最多可同时执行约 50 万次标量(权重)乘法。
使用市售的光学组件和标准的神经网络训练方法,光学神经网络可以在标准量子极限附近通过极低的光功率达到很高的精度。这样的结果证明了低光功率操作的原理,并为实现光学处理器开辟了一条道路:只要仔细设计用于数据存储和控制的电子系统,每个标量乘法只需要 10^-16 J 的总能量,这要比当前的数字处理器高效好几个数量级。
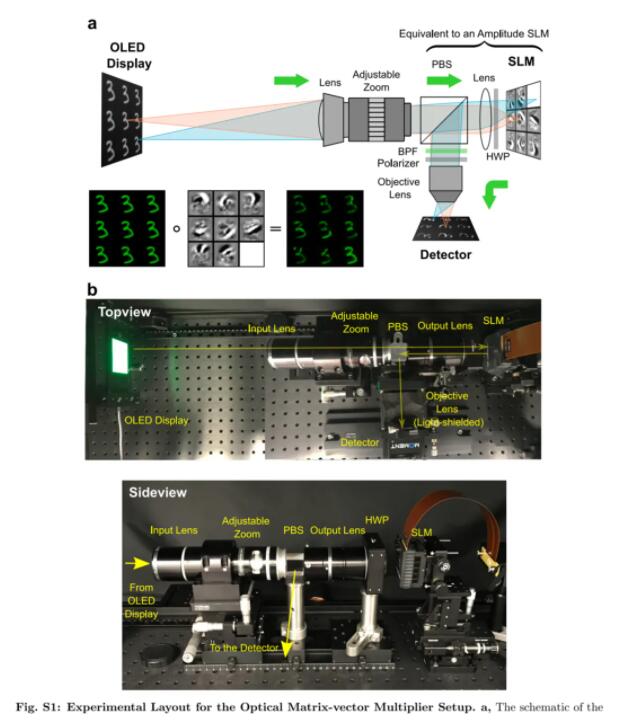
光学矩阵向量乘法器的实验仪器配置。a 为光学装置原理图,b 为与原理图相对应的主要实验仪器。
大规模光学矩阵向量相乘
在光学矩阵矢量乘法器中实现能量优势的关键是尽可能放大要相乘的矩阵和向量。被放大后,大规模的乘法和累加操作就可以完全在光学领域并行执行,而且电子和光信号之间的转换成本有缓冲空间。在光学中,有几种不同的方法来实现并行操作:波长多路复用、光子中的集成电路空间多路复用和 3D 自由空间光学处理器中的空间多路复用。
迄今为止,在所有多路复用方法和架构中,模拟 ONN 都使用较小的向量 - 向量点积(作为实现卷积层和完全连层的基本操作)或矩阵向量乘法(用于实现完全连接的层),将向量限制最多 64 维(远低于 10^3),这也是光处理器能耗高于理论预测的根本原因。
因此,运用了可以进行大规模矩阵矢量乘法的 3D 自由空间光学处理器,研究者构建了如下图 a 所示的 ONN 架构,用每次标量相乘少于一个光子进行图片分类,达到了 ONN 的量子限制理论效率峰值。
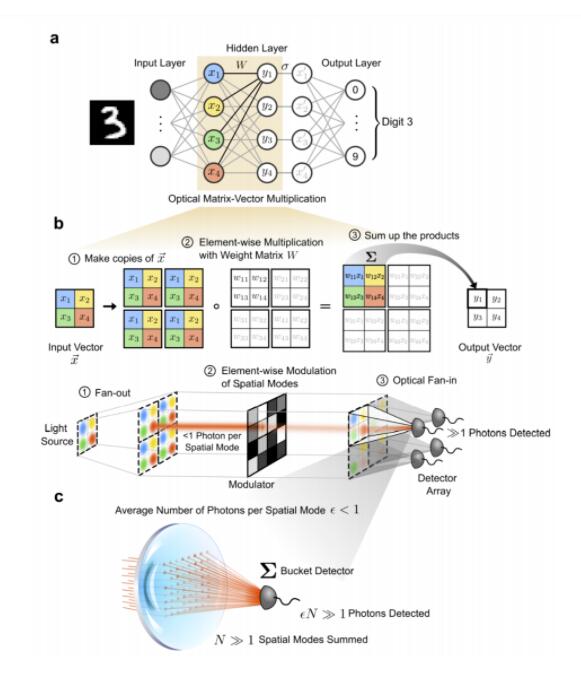
研究者设计和构造的光学处理器使用以下方案执行矩阵向量乘法图片:
- 把输入向量 ~x 的每个元素 x_j 编码为一个光源像素照射的单独空间模式强度;
- 把每个矩阵元素 w_ij 编码为调制器像素的透射率;
- 使用有机发光二极管(OLED)显示器作为光源;
- 使用空间光调制器(SLM)进行强度调制。
矩阵向量乘法是通过三个物理步骤计算的:
- 扇出:输入向量的元素在空间上排列为 2D 块(图 1b,左上方)。代表输入向量图片的 2D 块被复制了与矩阵 W 中的行数相等的次数,然后平铺在 OLED 显示上,如图 1b 所示(顶行)。
- 逐项积:将编码单个标量元素 x_j 的每个 OLED 像素对齐并成像到 SLM 上的相应像素,其透射率设置为∝w_ij,执行标量乘法 w_ij x_j(图 1b 底部中间)。
- 光学扇入:将每个块的强度调制像素通过将其透射的光聚焦到检测器上进行物理求和。撞击在第 i 个检测器上的光子总数与矩阵向量乘积 y 的元素 y_i 成正比(图片)(图 1b 右下)。每个 y_i 可以解释为输入向量图片与矩阵 W 的第 i 行之间的点积。
当光通过设置,矩阵向量乘法中涉及的所有标量乘法和加法被并行计算完成。向量元素在光强度中的编码将设置限为使用矩阵和具有非负元素的向量执行矩阵向量乘法。而且,该系统还可以用于对具有正负的元素的矩阵和向量执行矩阵向量乘法,方法是使用偏移量和缩放比例将计算转换为仅涉及非负数的矩阵向量乘法。
对于系统计算的每个向量 - 向量点积,将与逐项积相对应的空间模式聚焦到单个检测器上,来进行逐项积的求和。因此,检测器的输出与点积答案成正比,其信噪比(SNR)在散粒噪声极限下缩放为√N。如果向量足够大,那么即使每个空间模式的平均光子数都远小于 1,撞击到检测器上的光子总数也可能远远大于 1,因此正如图 1c 所示,精确地读出了点积答案是可能的。
亚光子点积的精度
为了了解系统在低光功耗情况下的实际性能,研究者在调整光子的数量的同时描述其准确性。在第一个表征实验中,研究者计算了随机选择的向量对的点积(图 2a),将通过点积计算得到的表征结果直接应用于通用矩阵向量乘法的设置(看作向量 - 向量点积计算)。
而点积计算的答案是标量,因此只需使用单个检测器,编码点积答案的光信号由能够分辨单个光子的灵敏光电检测器测量。通过改变检测器的积分时间并在 OLED 显示后立即插入中性滤光片,可以控制每个点积所使用的光子数。
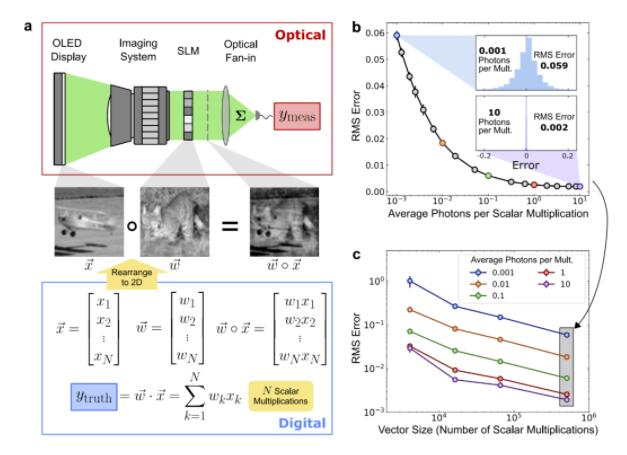
如上图 2b 所示,为了证明设置可以基于大尺寸向量使用每个标量乘积少于 1 个光子的计算,研究者测量了尺寸约为 50 万的向量之间点积的数值精度。每个标量乘法 0.001 个光子的情况下,测得的误差约为 6%,导致此误差的主要因素是检测器的散粒噪声。随着增加所使用的光子数量,误差逐渐减小,直到在每次乘法 2 个或以上光子时达到大约 0.2%的最小误差。
为了使实验获得的模拟数字精度与数字处理器中的数字精度之间能够进行对比,研究者将每个测得的模拟误差百分比解释为对应于计算出的点积答案的有效位精度。使用度量噪声等效位的模拟 RMS 误差 6%对应于 4 位,而 0.2%RMS 误差则对应于大约 9 位。
研究者还证实了,当每个标量乘法使用较少数量的光子时,可以计算出较短向量之间的点积(图 2c)。对于每次乘法范围为 0.001 至 0.1 个光子的光子预算,无论所测试的所有向量有多大,数值误差都由散粒噪声决定。当使用的光子数量足够大时,误差不再由散粒噪声控制,这与图 2b 中所示的单向量大小结果一致。对于测试的每个光子预算,较大向量之间的点积误差较低。这可能是因为较大向量之间的点积涉及了更大量项的有效平均。
使用亚光子乘法的 ONN
由于使用非常有限的光子预算,导致了乘法误差。为了确定 ONN 可以容忍多少误差,研究者运行经过训练的神经网络,并根据使用的光子数量来测量分类精度。
如下图 3a 所示,研究者将带有 MNIST 数据集的手写数字分类作为基准任务,并训练了一个具有用于低精度推理硬件(量化感知训练)的反向传播的四层全连接多层感知器(MLP)。
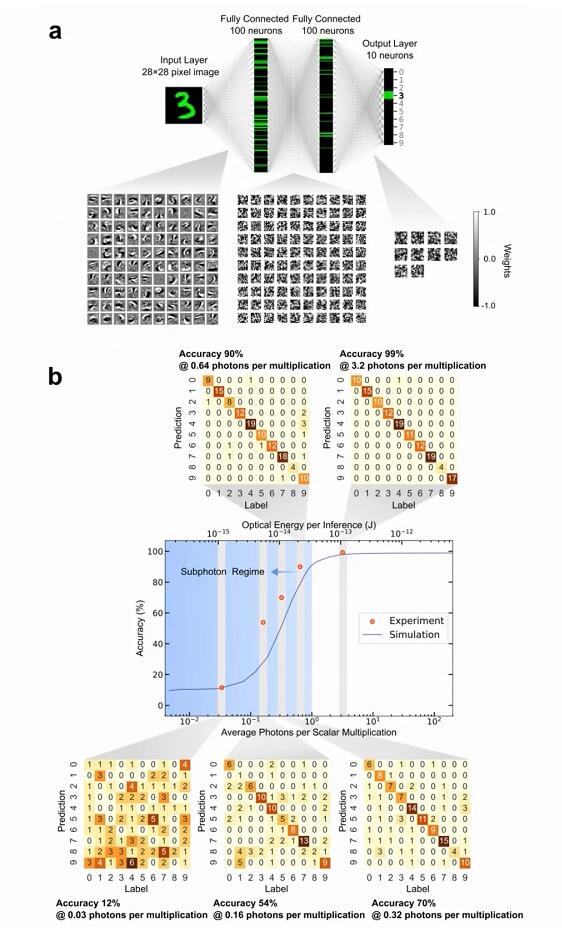
研究者首先评估了 MNIST 数据集中 5 个不同光子预算下的前 130 个测试图像:每个标量乘法的光子分别为 0.03、0.16、0.32、0.64 和 3.2 个光子(图 3b 中间图橙色点)。
然后他们发现了每次乘法使用 3.2 个光子会导致~ 99%的分类精度(图 3b 右上),几乎与在数字计算机上运行的同一训练过的神经网络的精度(99%)相同。在亚光子状态下,每个乘法使用 0.64 个光子,ONN 达到大于 90%的分类精度(图 3b 中上)。
实验结果与遭受散粒噪声的 ONN 所执行的同一神经网络的仿真结果非常吻合(图 3b 中间面板,深蓝色线)。如图 3b 所示,为了达到 99%的精度,每次推断手写数字所检测到的总光能约为 1 pJ。对于这些实验中使用的权重矩阵,平均 SLM 透射率约为 46%。
因此,当考虑到 SLM 不可避免的损耗时,每次推断所需的总光能约为 2.2 pJ。而 1 pJ 接近电子处理器中仅用于一个标量乘法的能量,而研究者的模型每次推断需要 89,400 标量乘法。
康奈尔大学的研究者使用标准的神经网络模型架构和训练技术,无须执行任何重新训练就可以运行模型。软件和硬件开发的成功分离也表明,研究者的光学神经网络(ONN )在无需对 ML 软件的工作流程进行任何重大更改的条件下,可以替代其他更传统的神经网络加速器硬件。
同时,这些研究结果表明,光学神经网络在原理上比电子神经网络具有更多基本的能量优势。光学神经网络可以在光子预算体制下运行,其中标准量子极限(即光学散粒噪声)决定了可达到的精度。