













本文转载自微信公众号「石杉的架构笔记」,作者梦。转载本文请联系石杉的架构笔记公众号。
概要
本次会先从一个数据页中如何存储和查询数据开始,拓展到多个数据页中查询数据,分析无索引查询时的低效率问题,然后通过页分裂过渡到主键目录以及索引页相关内容,见证一颗索引树是如何一步步生长起来的。
最后站在更高的角度看下常见的一些索引名词、索引的优缺点以及如何才能设计出更好的索引来,开始分析前我们先来思考下如下的一些面试题:
1.InnoDB的索引数据结构是什么?为什么用这种数据结构?
2.聚簇索引和普通索引的区别是什么?
3.什么是回表操作?它对索引有什么影响吗?
Mysql索引的B+树的生长流程如下图所示:
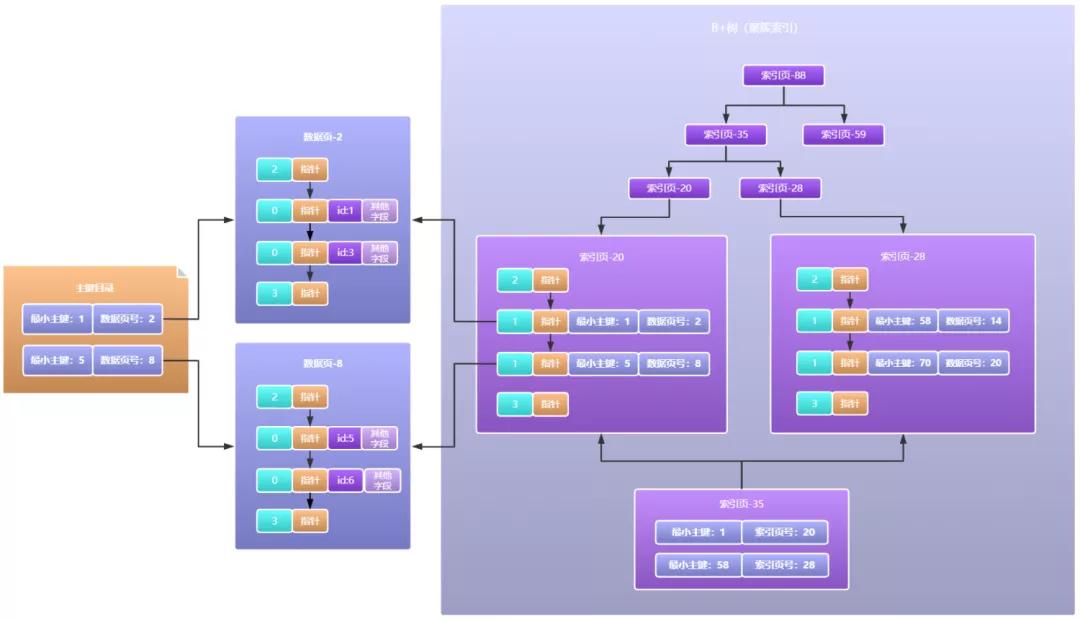
2.B+索引树是如何生长的
2.1 无索引时的数据查询
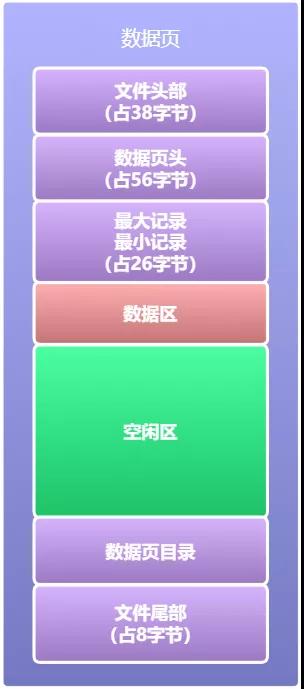
数据页是Mysql中数据管理的最小单元,既然我们要研究索引是如何高效查询数据的,首先我们肯定要搞清楚数据是如何存放的,数据页的结构通过上篇文章我们了解到大概是这样的:
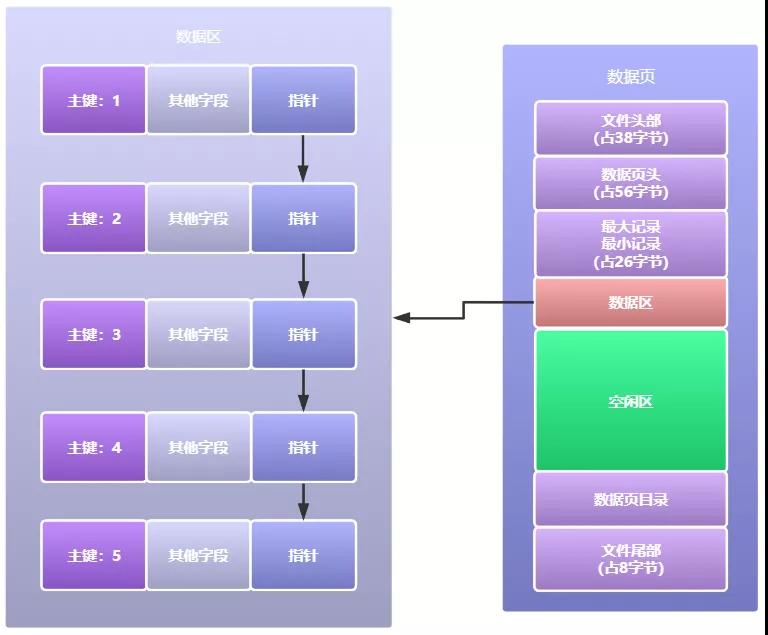
而数据表中的每行数据就存放在数据区中,数据区中每行数据以单向链表的方式,通过指针连接起来,如下图所示:
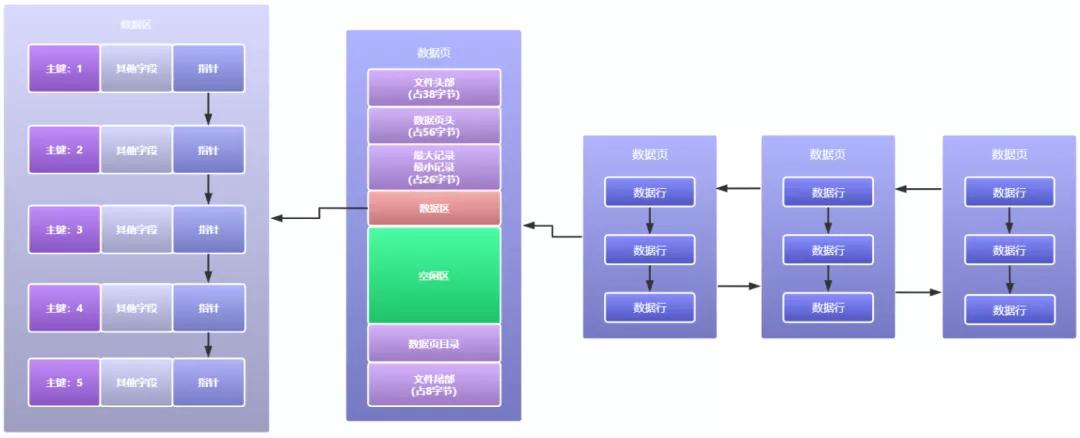
同时每个数据页之间再通过双向链表的方式组织连接起来,如下图所示:
(1)无索引时的数据查询
通过以上对数据页以及数据页内部数据结构初步的分析,现在我们就可以看下,如果说要查询某张表的某行数据会经过什么样的流程。
数据页一开始当然是存放在磁盘中的,一张表对一般会应着多个数据页,查询数据时从磁盘中依次加载数据页到InnoDB的缓冲池中,然后对缓冲池中缓存页的每行数据,通过数据页的单向链表一个一个去遍历查找,如果没有找到,那么就会顺着数据页的双向链表数据结构,依次遍历加载磁盘中的其他数据页到缓冲池中遍历查询。
大家可以看到,像上面这样的查询方式就有点傻了,因为如果恰好你要查的数据行在这张表最后一个数据页的最后一行,那岂不是所有的数据页都要被扫描一遍,然后每个数据页中也是遍历链表,整体的效果就是以O(n)的时间复杂度在遍历链表了,这样查询的性能肯定是不行的。
(2)优化数据页内查询效率-槽位
我们先把目光转移到单个数据页内的数据查询,假如说我们现在已经锁定数据就在某个数据页中了,但是我们该怎样快速的从这个数据页中找到我们想要的那行数据呢?
通过之前的分析我们可以知道,最傻的一种方式就是遍历数据页中的单向链表查询,一个节点一个节点去扫描,相对应的查询效率是肉眼可见的低。但是如果说可以像翻书一样,根据目录来减小我们查询的范围,相对应的查询效率不就上来了吗,根据这种想法,InnoDB存储引擎设计了槽位这种方式来组织数据页中的多个数据行,槽位信息存放在数据页中的数据页目录中。
槽位简单来说就是将数据页中的多个数据行分组划分,每个数据行组都找这个组中的主键值最大的那个数据行的地址作为槽位的信息,这样数据页目录中的一个个槽位不就是像是一个个目录了吗,标记好了多个数据行分组的位置信息,如下图所示:
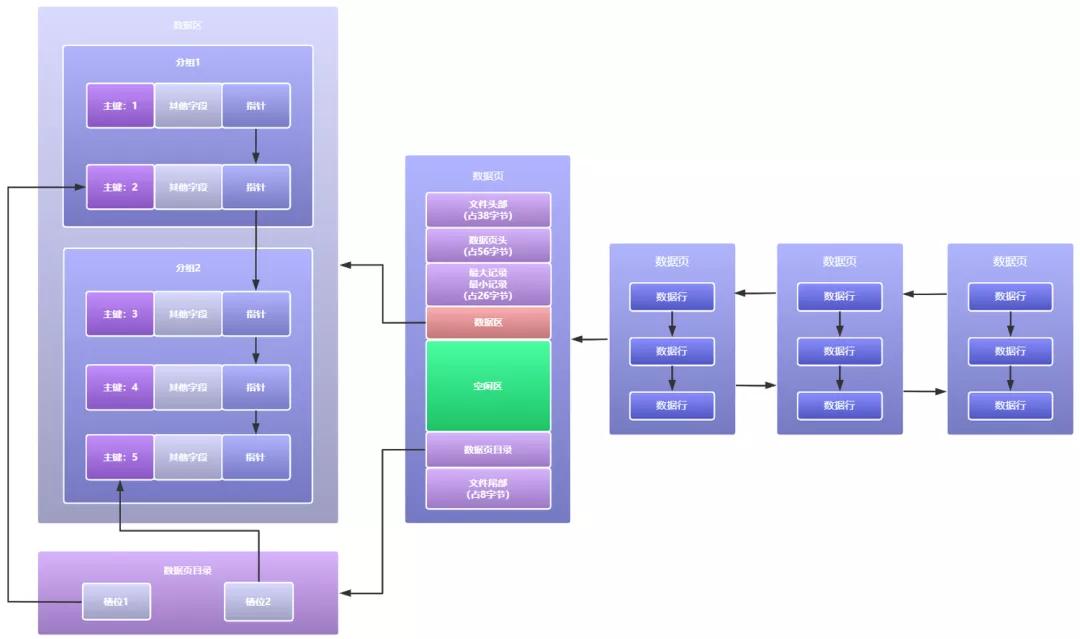
这下有了数据页目录中的槽位信息,此时要查询数据页中的某行数据不就很简答了,比如我们要查询主键为4的那行数据,直接通过二分法以O(logn)的时间复杂度锁定数据页目录中的槽位2,因为槽位之间都是紧密连接的,可以通过槽位2找到槽位1,从槽位1末尾开始,对分组2中的数据开始遍历,因为每个分组中的数据量都很少,此时在这么小的范围内简单遍历下就可以快速找到主键为4的那行数据,时间复杂度从之前的O(n)降低到O(logn)效率还是挺可观的。
但是如果你不是通过主键去查询的,槽位此时就排不上用场,你还得一个一个遍历数据页中的单向链表去找到你想要的那行数据。
2.2 索引的前夕-页分裂
这里我们先来个小插曲,简单了解下页分裂,这块内容也是后面索引机制能够正常运行的基础。
我们都知道一个数据页就是16KB大小,当一个数据页中的数据行足够多时就会重新创建一个数据页继续写数据行,如果说我们没有用到索引还好,但是如果我们要在表中创建索引,那么对多个数据页中的数据就有约束了。
如果新创建的数据页中的数据行的主键值,存在比它上一个数据页的主键值还小的情况,这种情况是不被允许的,如下图所示:
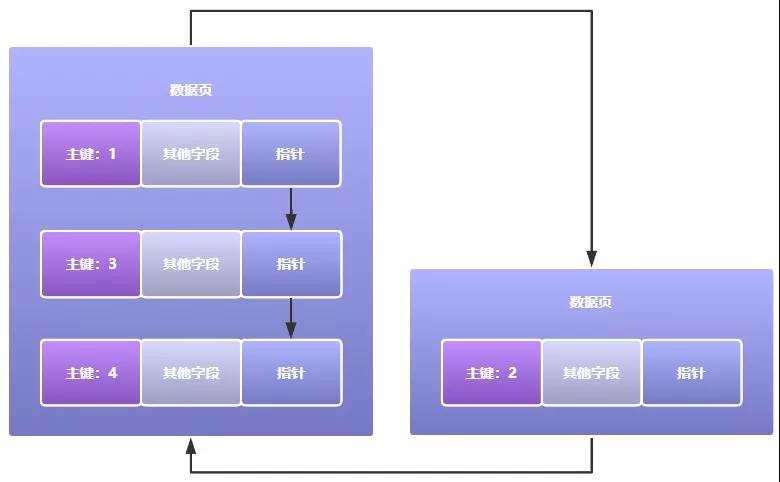
如果出现上图的情况,多个数据页之间的主键就无序了,而索引机制的实现是要基于多个数据页主键的大小是依次递增的,所以此时就会出现页分裂的情况。
其实页分裂目的也很明确,就是调整下不同数据页的数据顺序,使得最终按顺序创建的索引页之间,后一个数据页中的每一个数据行的主键值都要大于上一个数据页,当然一个数据页中当然是按照单向链表的方式依次递增的,页分裂流程如下图所示:
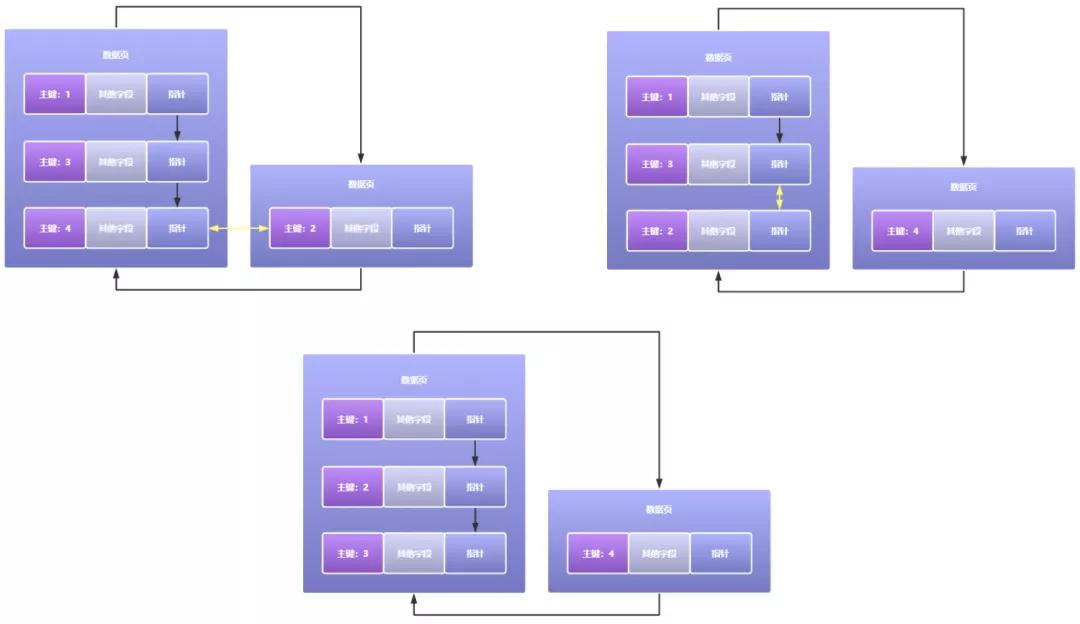
我们可以看到页分裂主要就是调整了下数据页之间数据行的数据的顺序,使得多个数据页之间的主键值是按照顺序来存放的,在这样有序的数据中,高效查询才变得可能。
频繁的出现页分裂情况,毕竟页分裂要涉及到数据的移动,在性能上也是会有损耗的,这也警示我们减少页分裂的出现概率是非常有必要的,在设计表结构时我们可以尽量使用主键自增长的方式,而不是用很难保证主键顺序的自定义创建主键的方式,使用主键自增长方式,能大大避免说数据页之间主键大小出现顺序错乱的问题,减少页分裂发生的概率。
2.3从主键目录到索引页
查询一行数据,在物理层面就是定位到哪一个数据页中的哪一行数据。在数据页中定位数据的问题,在之前我们已经通过槽位的方式优化了查询的效率,现在我们要解决的是如何在大量的数据页中定位数据页,这就是索引的目标。
(1)主键目录
InnoDB存储引擎一开始是使用主键目录的方式,将数据页号和数据页最小的主键值作为一条记录,如下图所示:
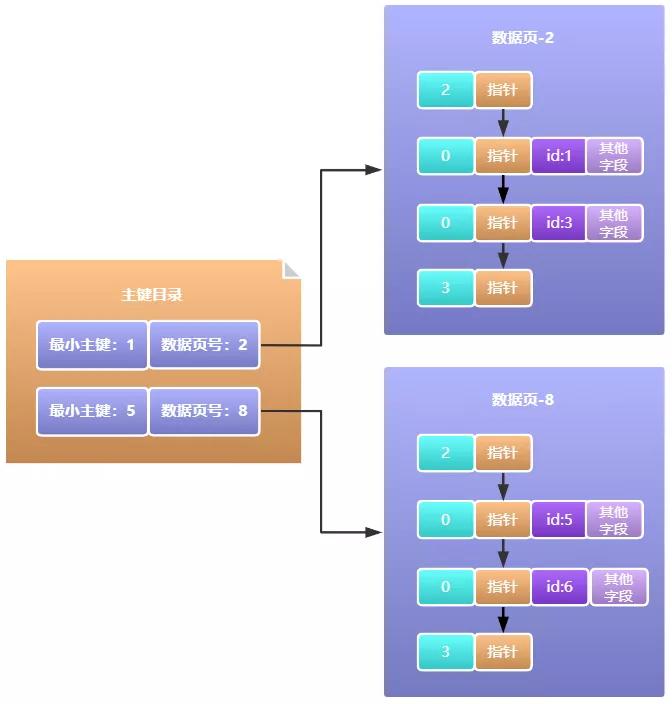
这样的话,我们要查哪一条数据就不用扫描一个数据页内的所有数据再扫描下一个了,直接通过id去主键目录看一下,通过二分查找定位到具体哪个数据页,然后数据页内部通过定位槽位,遍历那个槽位对应数据行分组找到具体的一行数据。
(2)索引页
现在有一个问题就是,每张表对应的数据页都有很多,主键目录就会有大量的数据、就有可能放不下,这时InnoDB设计者们就想存放目录数据也是数据啊,为什么不可以使用数据页来放呢,就这样主键目录的信息就被移到数据页来了,而这些数据页就被称为索引页,如下图所示:
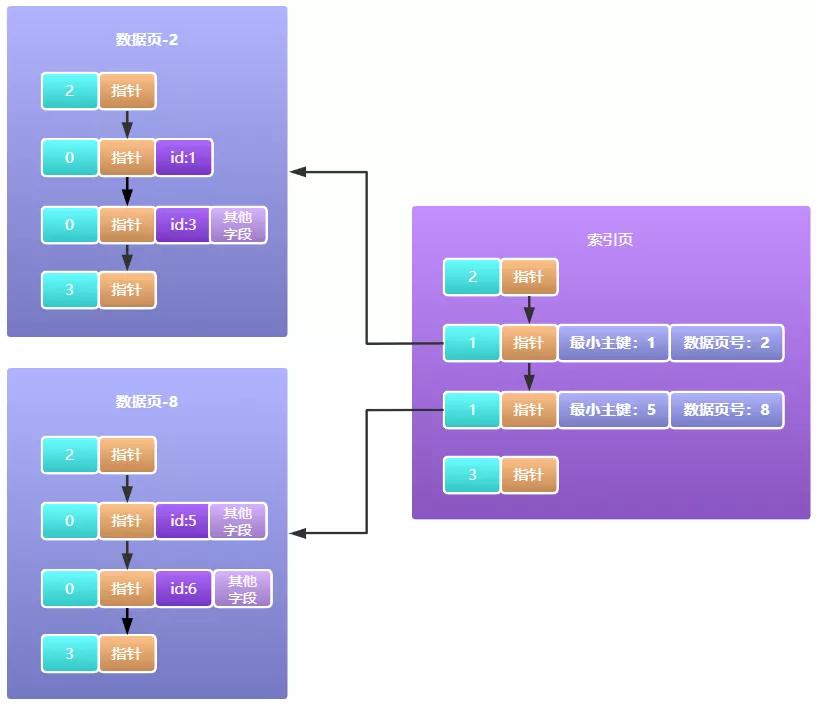
从这里我们可以知道数据页肯定不是简单只存放数据表中的数据的。好了,现在主键目录由于容量有限,我们把主键目录信息移动到了数据页中形成了索引页,但同样的问题不还是会出现吗,一个数据页的大小也才16KB,索引页本身的容量也是有限的,容量不够了该怎么办呢?
为了解决索引页容量不够的问题,索引页会重新创建和升级,先把超出容量的数据放到一个新的索引页中,然后再加一层索引页,如下图所示:
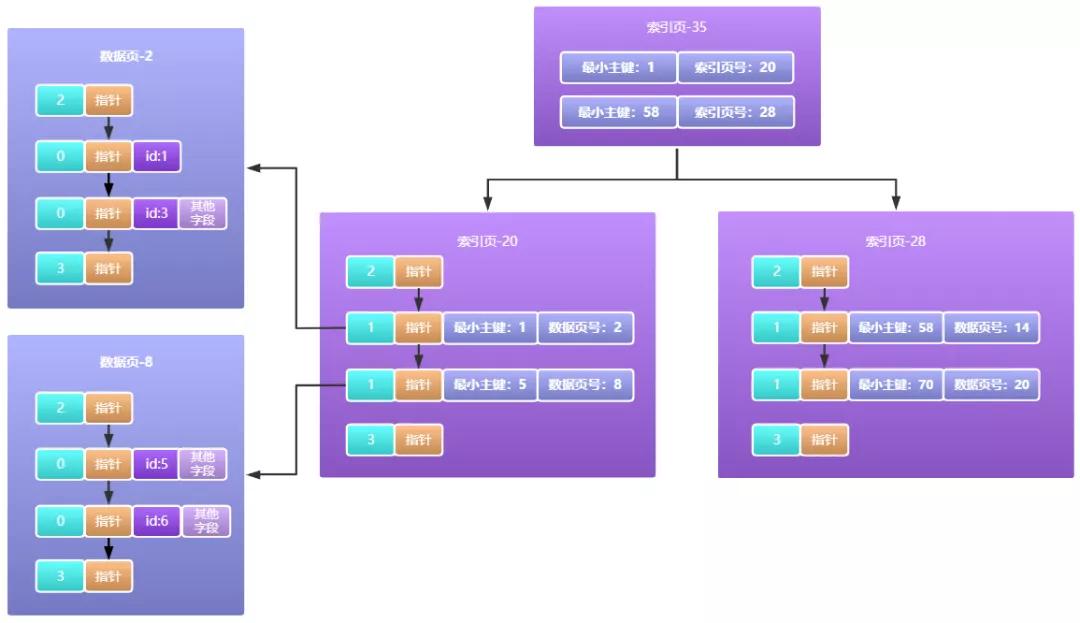
由上图我们可以看到,新的一层索引页35它存放的就不是最小主键对应的数据页目录了,而是最小主键对应的索引页目录了,以此类推如果索引页35这里容量也不够呢,那就继续往上一层扩展啊,最终效果看起来就像下面一样:
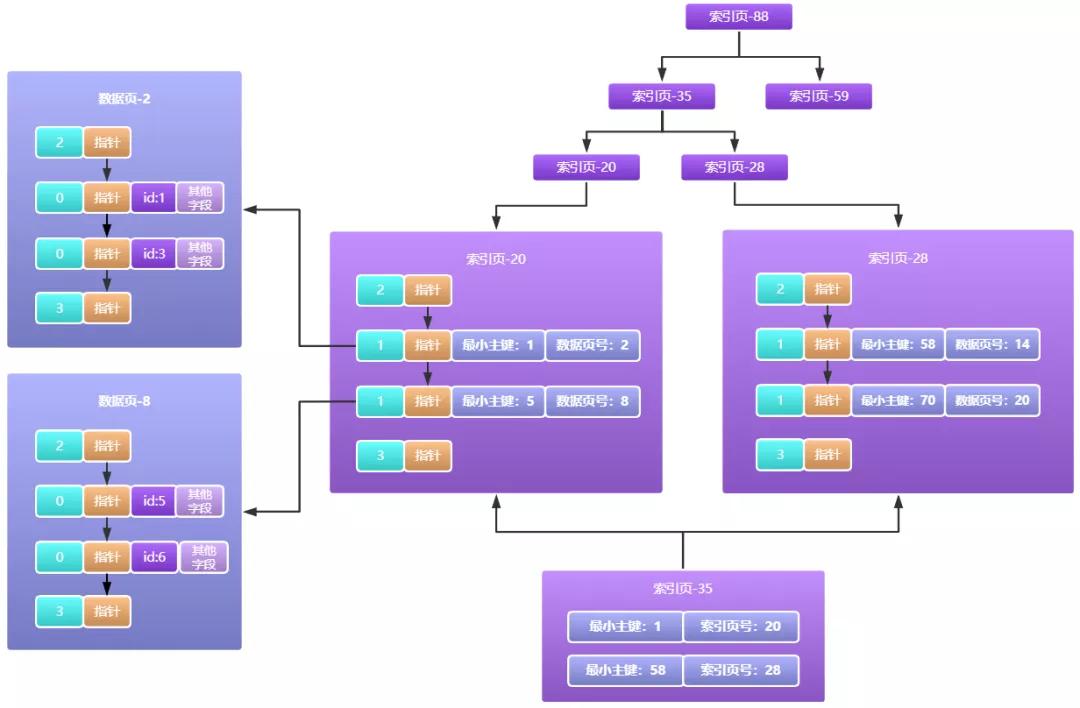
大家看出来了吗,由索引页一层一层组成的结构不就是我们经常说的索引树吗,而这棵树在mysql中称之为B+索引树。
树这种数据结构天然可以使用二分法查询,所以现在如果我们要查询一条数据,从树的根节点开始通过二分法查找,以O(logn)的时间复杂度锁定数据页,然后在数据页中同样使用二分法锁定槽位,在槽位中简单遍历下不就找到数据了吗,相比于没有索引的场景,速度那可是相当快了。
3.聚簇索引、普通索引和覆盖索引
关于索引有一些常见的名词我们需要加以区分。
首先聚簇索引就是像我们上面看到的一棵树一样,它的叶子节点是一个个数据页,这些数据页中存放的都是数据表中每一行的完整数据,所以说如果B+树是以完整数据的数据页为叶子节点的,我们把这个索引树称为聚簇索引;如果一个索引的索引树,叶子节点不是以数据页为叶子节点的,就称为二级索引或普通索引。
聚簇索引和普通索引最大的区别就是,聚簇索引的叶子节点存放了数据行的完整数据,而二级索引叶子节点只有数据的部分字段。
而覆盖索引本身并不是一种索引,而是一种查询数据的方式,比如我们对表table中的字段name建立了索引,然后我们执行查询如:select name from table where name like '张%',此时直接从name字段对应的B+树种查询到对应的一批name值,然后直接就返回就行了,也就是说我们想要的字段name它本来就在索引上,我们直接通过二分法高效的从树上直接摘下来就行了,而这种查询方式就称为覆盖索引。
当然相比于覆盖索引方式,如果查询改为:select * from table where name like '张%',这就不是覆盖索引了,因为此时你不光要从索引树上找到具体的name,还要利用id值回表查询所有的字段。
4.索引的优缺点分析
索引的优点当然就是高效查询数据,索引将遍历链表的O(n)的查询时间复杂度优化为了O(logn)的时间复杂度。
但是索引的缺点也是很明显的,首先在时间角度上,它必须要求主键是要按顺序增长的,无序的主键会带来频繁的页分裂,影响效率;对数据库表的增删改操作的同时也需要维护索引,这部分的维护也是一块性能损耗点;在空间角度上:索引相关的数据和实际数据一样都是要占内存空间的。
所以索引虽然能够提高查询效率,但是同时也要承担它给我们的系统带来的性能损耗,从这点上来看索引并不是建的越多越好。
5.三个维度设计好索引
下面我们从以下三个维度优化下索引的设计
(1)首先我们从时间角度上
我们需要为了避免频繁的页分裂,需要尽可能使用主键自增长等方式,保证新增的数据页中的数据行的主键都是递增,避免不必要的页分裂带来的性能损耗和拖慢查询效率。
另外选择合适的字段作为索引字段也很重要,需要选择基数较大的字段,也就是一个字段可能出现的值比较多,这样我们在B+树中查询时,才能最高效的发挥出二分法查询的威力,如果建立索引的字段基数比较小可能查询时二分查找就会退化成时间复杂度为O(n)的线性查询了。
(2)空间的角度上
因为索引数据本身也是要占空间的,可以选择字段长度较小的作为索引字段,这样整棵B+树不至于那么占空间。
但是如果非得要以长字段作为索引也不是不行,可以采用折中的以字段的前缀作为索引,这样的索引也称为前缀索引,但是这样可能只能用在模糊查询上了,用在group by和order by上就不太适合了。
(3)作用范围上
当然我们设计索引的目的,当然是为了更好的用上索引,索引在设计时,尽可能让where、group by、order by这些语句都能用上索引。
6.面试题剖析
(1)InnoDB的索引数据结构是什么?为什么用这种数据结构?
(2)聚簇索引、普通索引区别是什么?
(3)什么是回表操作?它对索引有什么影响吗?





















