前言
基本职场上的程序员用来统计数据库表的行数都会使用count(*),count(1)或者count(主键),那么它们之间的区别和性能你又是否了解呢?
其实程序员在开发的过程中,在一张大表上统计总行数是非常耗时的一个操作,那么我们应该用哪个方法统计会更快呢?
接下来我们就来聊一聊MySQL中统计总行数的方法和性能。
count(*),count(1),count(主键)哪个更快?
1、建表并且插入1000万条数据进行实验测试:
- # 创建测试表
- CREATE TABLE `t6` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `name` varchar(50) NOT NULL,
- `status` tinyint(4) NOT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_status` (`status`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- # 创建存储过程插入1000w数据
- CREATE PROCEDURE insert_1000w()
- BEGIN
- DECLARE i INT;
- SET i=1;
- WHILE i<=10000000 DO
- INSERT INTO t6(name,status) VALUES('god-jiang-666',1);
- SET i=i+1;
- END WHILE;
- END;
- #调用存储过程,插入1000万行数据
- call insert_1000w();
2、分析实验结果
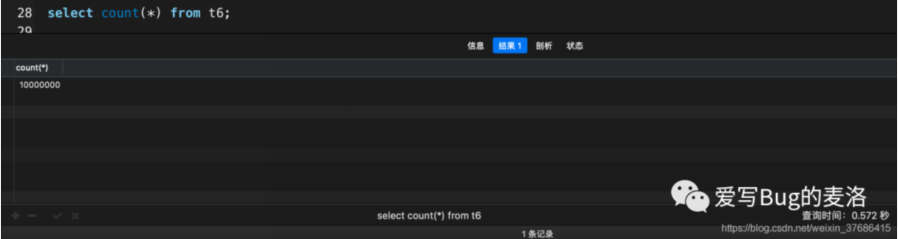
- # 花了0.572秒
- select count(*) from t6;
在这里插入图片描述
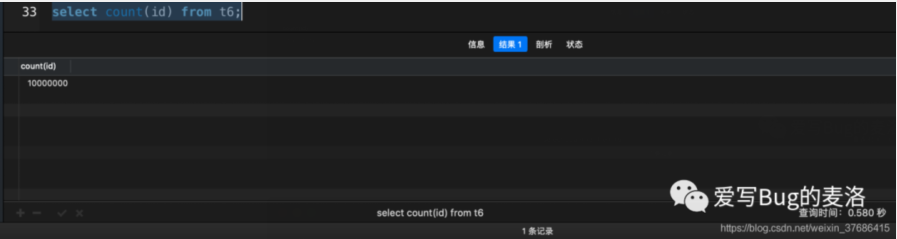
- # 花了0.572秒
- select count(1) from t6;
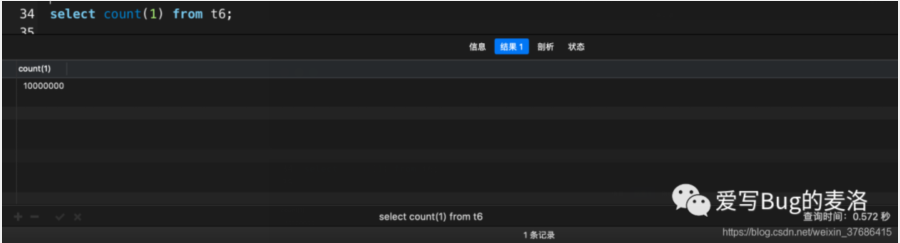
- # 花了0.580秒
- select count(id) from t6;
- # 花了0.620秒
- select count(*) from t6 force index (primary);
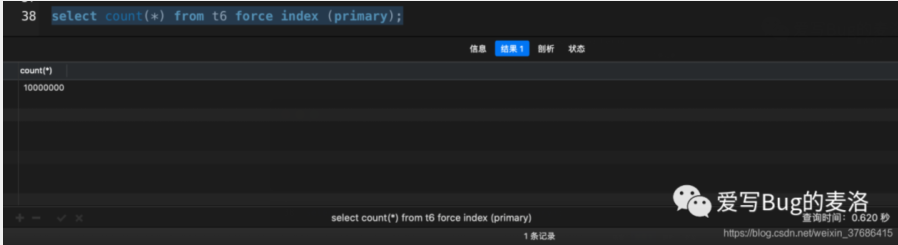
从上面的实验我们可以得出,count(*)和count(1)是最快的,其次是count(id),最慢的是count使用了强制主键的情况。
下面我们继续测试一下它们各自的执行计划:
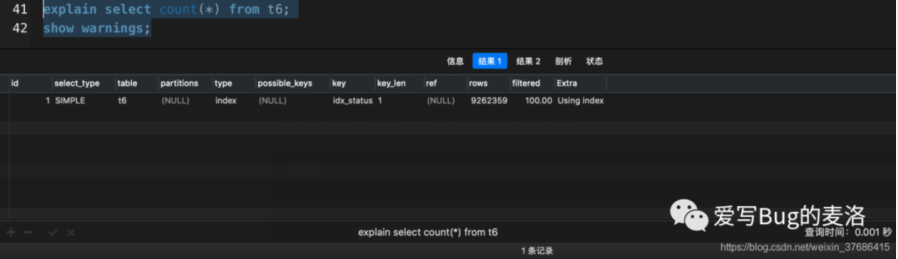
- explain select count(*) from t6;
- show warnings;
- explain select count(1) from t6;
- show warnings;
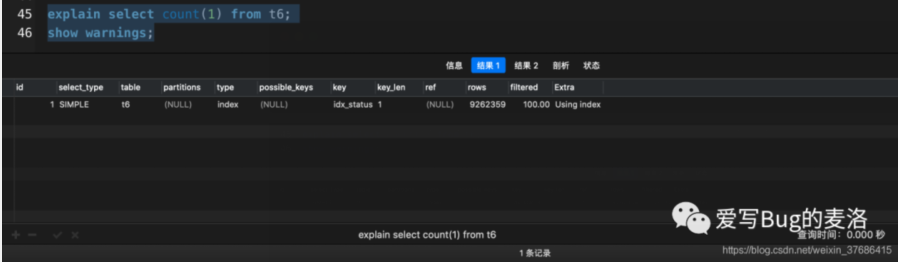
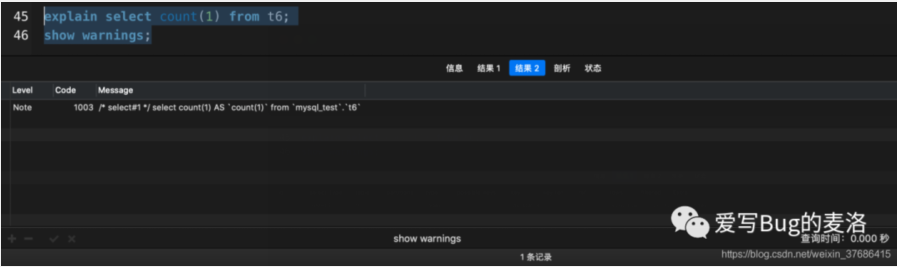
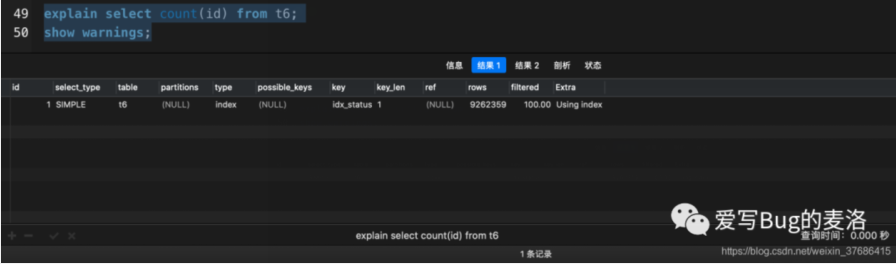
- explain select count(id) from t6;
- show warnings;
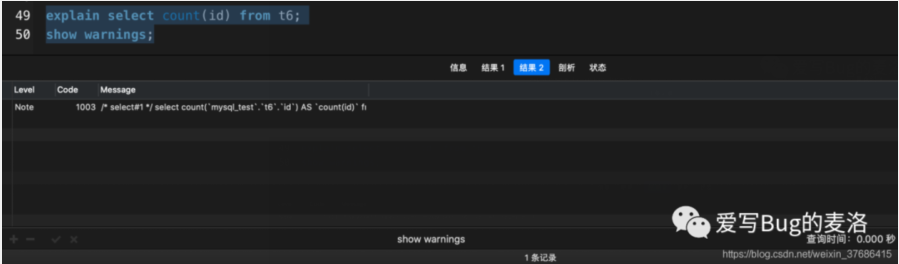
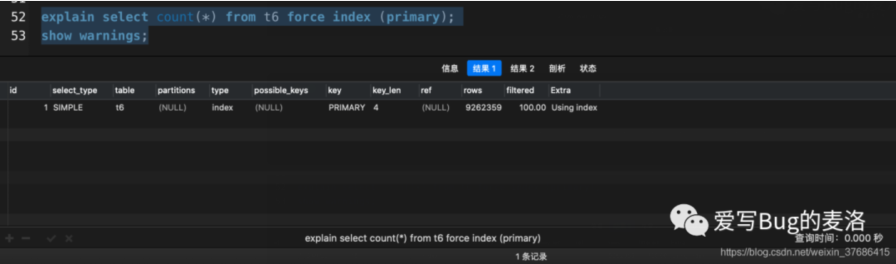
- explain select count(*) from t6 force index (primary);
- show warnings;
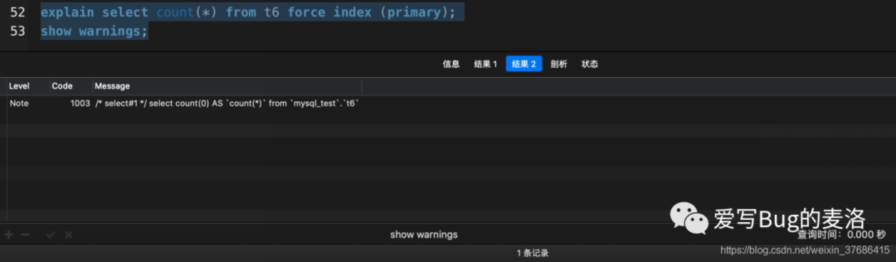
从上面的实验可以得出这三点:
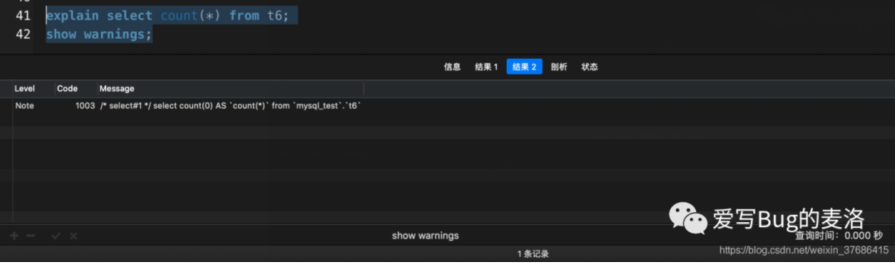
- count(*)被MySQL查询优化器改写成了count(0),并选择了idx_status索引
- count(1)和count(id)都选择了idx_statux索引
- 加了force index(primary)之后,走了强制索引
这个idx_status就是相当于是二级辅助索引树,目的就是为了说明:InnoDB在处理count(*)的时候,有辅助索引树的情况下,会优先选择辅助索引树来统计总行数。
为了验证count(*)会优先选择辅助索引树这个结论,我们继续来看看下面的实验:
- # 删除idx_status索引,继续执行count(*)
- alter table t6 drop index idx_status;
- explain select count(*) from t6;
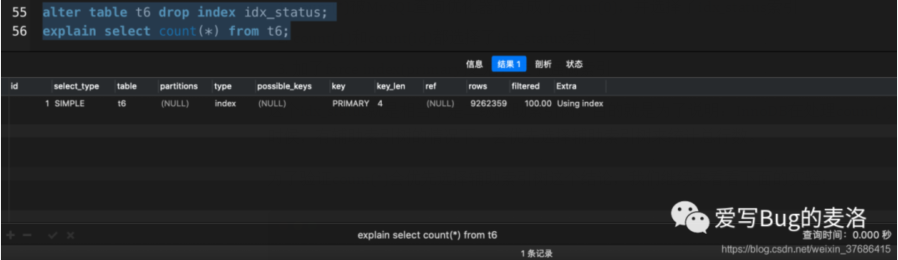
从以上实验可以得出,删除了idx_status这个辅助索引树,count(*)就会选择走主键索引。所以结论:count(*)会优先选择辅助索引,假如没有辅助索引的存在,就会走主键索引。
为什么count(*)会优先选择辅助索引?
在MySQL5.7.18之前,InnoDB通过扫描聚集索引来处理count(*)语句。
从MySQL5.7.18开始,InnoDB通过遍历最小的可用二级索引来处理count(*)语句。如果不存在二级索引,则扫描聚集索引。
新版本为何会使用二级索引来处理count(*)呢?
因为InnoDB二级索引树的叶子节点上存放的是主键,而主键索引树的叶子节点存放的是整行数据,所以二级索引树比主键索引树小。因此查询优化器基于成本考虑,优先选择的是二级索引。所以索引count(*)快于count(主键)。
总结
这篇文章的结论就是count(*)=count(1)>count(id)。
为什么count(id)走了主键索引还会更慢呢?因为count(id)需要取出主键,然后判断不为空,再累加,代价更高。
count(*)是会总计出所有NOT NULL和NULL的字段,而count(id)是不会统计NULL字段的,所以我们在建表的尽量使用NOT NULL并且给它一个默认是空即可。
最后,在以后总计数据库表的总行数的时候,可以大胆的使用count(*)或者count(1)。
参考资料
- 《高性能MySQL》(第三版)第六章优化COUNT()查询
- 《MySQL实战45讲》林晓斌