本文转载自微信公众号「二马读书」,作者二马读书。转载本文请联系二马读书公众号。
本文详细描述了千人千面的具体业务逻辑、技术方案和推荐算法,以及需要注意的问题。
互联网行业的快速发展,给我们带来了极大的便利。回顾整个互联网行业的发展历程,从PC时代到移动互联网时代,从移动互联网时代到IOT(物联网)时代,现在又即将从IOT时代迈入AI(人工智能)时代。这些飞速发展的背后,其实是对数据利用的巨大变革。
当下,移动互联网技术和智能手机的发展,使得采集用户数据的能力变得空前强大,无时无刻,无所不在。拥有这些数据后,全行业的个性化推荐能力变得更加容易实现,不论是淘宝京东,还是今日头条,无疑是这个时代的最大受益者。
不同于个人电脑,手机这类私人专属物品是与其他人很难共用的。从而手机的型号,以及在手机上的浏览、交易等行为数据,就具有了极高的分析价值。
从电商平台的角度来讲,个性化推荐的本质是根据不同的人群,将最有可能成交的商品优先推荐给相应的消费者,最大限度的提高购买转化率,促进用户购买下单。
当然,对于淘宝这类电商平台来说,个性化推荐也能充分利用有限的广告位资源,将流量的价值最大化。随着用户个人数据的不断丰富,推荐能力也在逐步升级,从基础的千人一面逐渐演化到千人千面。下面描述千人千面的具体业务逻辑、技术方案和推荐算法,以及需要注意的问题。
电商千人千面业务逻辑
我们了解到千人千面的本质是根据不同的人群,将最有可能成交的商品优先推荐给相应的消费者,最大限度上促进用户购买下单。那么具体的商品展现逻辑是怎样的呢?
千人千面,主要应用于首页、购物车、商品详情页、搜索列表等位置。

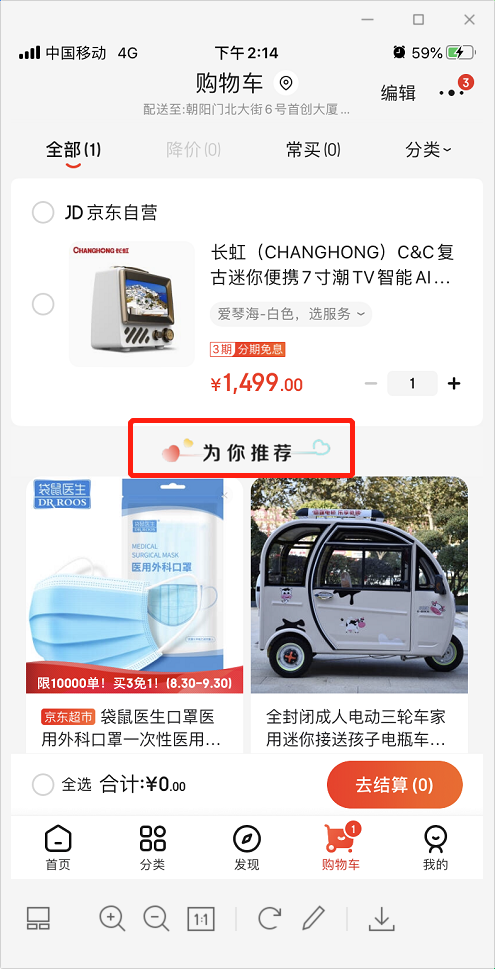

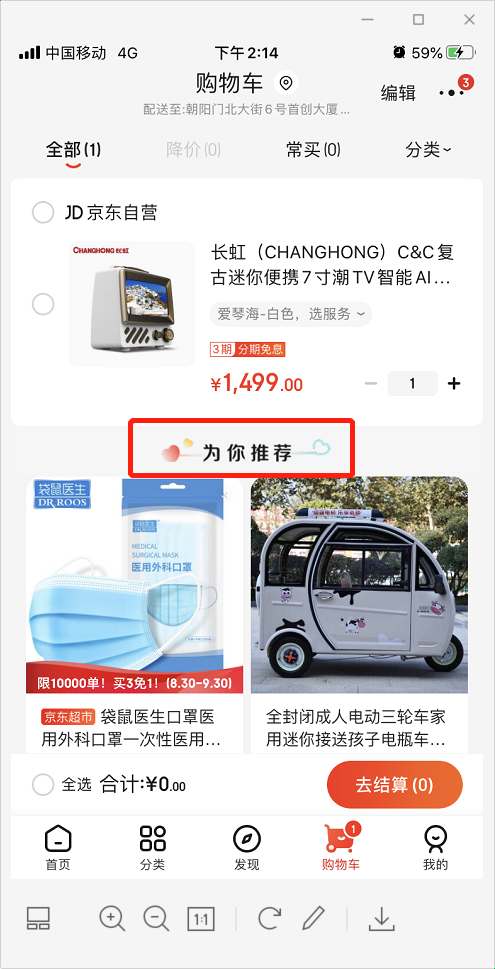
上面三个截图分别是首页、购物车和商品详情页,红框部分的“为你推荐”即是根据用户数据对用户进行的个性化商品推荐,不同用户展现的商品都不一样,也就是所谓的“千人千面”。
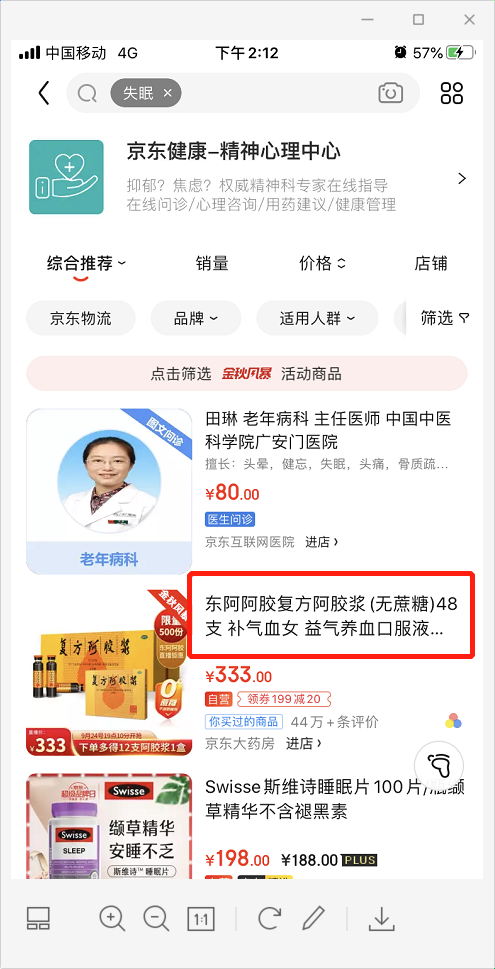
上面这张截图是搜索列表。其实搜索跟推荐也是分不开的,为了提高转化率,搜索结果往往要依赖于用户行为数据。我在搜索栏搜索“失眠”后,列表中显示了阿胶浆,很眼熟。对了,几天前我在APP里浏览过阿胶浆,刚好阿胶浆其中一个功效就是助眠,所以搜索列表就显示了这款商品。如果换一个用户搜索,很可能会搜不到阿胶浆,至少大概率不会显示在列表顶部。
如上图所示,千人千面买家的购买和浏览行为决定着产品的展示顺序,第一到第三层,很容易理解,也是大家常规对千人千面的基本认识,那么,第四层级是什么意思呢?类似的标签?
其实每个消费者只要有在淘宝网上购买或是浏览过,平台就会给用户打上标签,比如年龄、客单价、喜好、关注点等。根据用户标签的不同,每个用户访问APP时展示的商品就会有所差别。假设两个男生从来没有买过女性产品,第一次给女性买东西,搜索同一个关键词比如“连衣裙 女”,他们看到的商品列表也不一样,平台会根据你以往的一些购买行为打上标签,比如用户有“年轻、高客单价、爱名牌”等标签,那么展示给这个用户的就会是年轻款、高客单价的连衣裙相关商品。也就是说:根据用户的标签特征,将最有可能成交的商品优先推荐给相应的消费者,最大限度的提高购买转化率,促进用户购买下单。这就是千人千面的主要目的。
上面我们提到的用户标签,我们也经常称之为“用户特征”。我们一般会维护一个用户特征数据库,这是千人千面的基础。在搜索和推荐时往往需要这些用户特征数据。
推荐系统架构
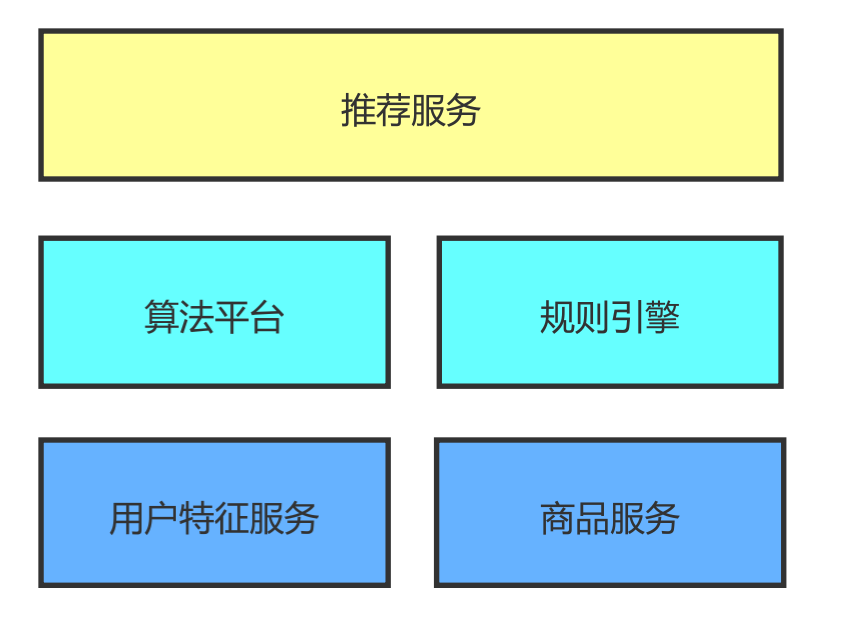
上面是一个简单的推荐系统的架构图。推荐服务依赖于算法和规则,对于简单的规则直接走规则引擎,对于较复杂的逻辑可以走算法,比如需要做机器学习或深度学习模型训练的场景。不管是规则引擎还是模型训练,都需要数据的支撑,用户特征服务和商品服务会给他们提供最基础的用户特征数据和商品数据。
数据存储,快速存取
数据存储主要是指用户特征数据的存储,这个量比较大。至于商品数据一般不会太大,淘宝这种体量的平台也不过三五千万的商品数量。我们的用户量大概有两亿多,月活跃用户5000万。为了保证系统的高性能,我们将数据存放在Redis集群中,在Redis中做分片存储。以userID做为Key,这个用户的特征数据作为Value。以userID做为Redis分片的路由Key。为了减少Redis存储空间,我们选用了protobuf作为数据存储格式。Protobuf是Google开源的,protobuf的序列化和反序列化性能很高,而且占用的空间比一般的格式要减少一半以上。
推荐算法
常见的个性推荐算法主要包括:基于内容的推荐、基于协同过滤的推荐、基于知识的推荐等。在实际应用中,很多电商平台往往以多种推荐方式融合的方式,实现个性化推荐。
基于内容的推荐(CB,Content-Based Recommendation)
基于内容相关性为用户推荐商品,利用内容本身的特征进行推荐。从类目、品牌、商品属性、商品标题、商品标签等多个维度计算内容相似度,将相似度最高的商品推荐给相关用户。内容的推荐是非常基础的推荐方法,计算的是内容本身的相关程度。
比如某个用户在淘宝上浏览过男士衬衫,在淘宝的发现好货就会给你推荐各种各样的男士衬衣、男士T恤、男士西装等,如果这个用户继续访问男士七分袖衬衣,系统获取到这个产品属性,会继续给你推荐七分袖的亚麻衬衣、七分袖麻料衬衣、五分袖衬衣、男士七分袖T恤等等。这就相当于在商场身边有个贴身的导购,你每试穿一次衣服又为你推荐一系列相关的衣服。
CB的基本实现原理
(1)提取商品特征
这个可以根据商品的一些数据,比如类目、属性、品牌、标题、标签、商品组合、评分等因子进行提取。
(2)计算用户喜欢的特征
根据用户以前的喜欢的和不喜欢商品的特征进行计算,得出用户喜欢的特征。用户的特征由相关关键字组成,可以通过TF-IDF模型计算用户行为的关键字,从而得出用户的特征。
(3)相关商品推荐给用户
根据用户喜欢的特征,去商品库进行选择,找出相关性最大的多个商品进行推荐。现在我们提取出了商品的特征,又通过计算得出了用户喜欢的特征,那么可以通过余弦相似度计算出商品间的相似度,做为个性化推荐的依据。简单介绍一下余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度。如图所示,夹角越小,两个向量越相似;夹角越大,两个向量越不同。

(4)最后根据用户反馈的结果更新用户喜欢的特征
用户的喜好是不断变化的,今天可能我关注衬衣,明天我又想看手机,所以系统需要根据用户的变化不断更新用户的特征。
CB算法的优点:
- 实现起来比较简单,不需要复杂的算法和计算,可以很快实现用户和商品的相关性
- 计算简单快速
- 结果可解释,很容易找到可解释的相关特征
CB算法的缺点:
- 无法挖掘用户的潜在兴趣
- 分析特征有限,很难充分提取商品相关性
无法为新用户产生推荐,在用户行为较少时推荐不准确
2. 基于协同过滤的推荐
通过基于内容的推荐算法只能基本满足用户的推荐需求,但是却做不到真正的千人千面。所以我们需要通过算法模型自动发掘用户行为数据,从用户的行为中推测出用户的兴趣,从而给用户推荐满足他们需求的物品。
基于用户行为分析的算法是个性化推荐系统的重要算法,这种算法一般被称为“协同过滤算法”。协同过滤算法是指通过用户行为分析,不断获取用户互动信息,在用户的推荐列表中不断过滤掉不感兴趣或者不匹配的商品,不断提升推荐效果。
简单来说,这种算法不单单只是根据自己的喜好,而且还引入了“邻居”的喜好来进行推荐。这样的推荐更加充分,而且可以深入挖掘用户潜在的兴趣。
上面说过协同过滤是基于用户行为分析,所以需要引入下面的参数进行计算:
- 用户标识
- 商品/物品标识
- 用户行为的种类(包括浏览,点赞,收藏,加入购物车,下单等)
- 用户行为的上下文(包括时间、地点等)
- 用户行为的权重(包括浏览时长,购买频次等)
- 用户行为的内容(比如评价分值,评论的文本内容等)
协同过滤主要包括两种:基于用户的协同过滤,User-based CF;和基于商品的协同过滤,Item-based CF。下面我们别对这两者进行说明。
(1)基于用户的协同过滤User-based CF
系统通过分析某用户和其他用户的特征值,找出相近的特征用户,然后根据特征用户喜好的商品,从中找到一些商品推荐给该用户。
以阅读为例,比如用户A一直看架构方面的书籍,这样系统可以找到和他有类似兴趣的用户,然后把这些用户喜欢看的书(同时这些书用户A没有看过的)推荐给用户A。简言之就是计算出两个用户的相似度,然后给A推荐用户B喜欢的东西。
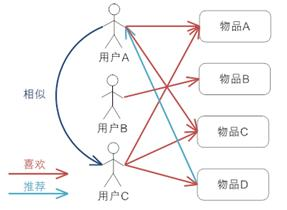
User-based CF基本实现原理
1)找到和目标用户兴趣相似的用户
先给用户行为定义分值,比如给浏览、收藏、加入购物车、购买、评分等行为定义分值,然后给各个行为打分,通过余弦相似度计算用户相似度。
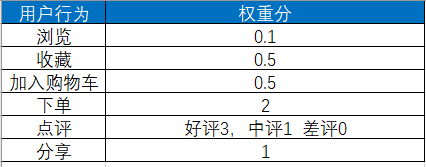
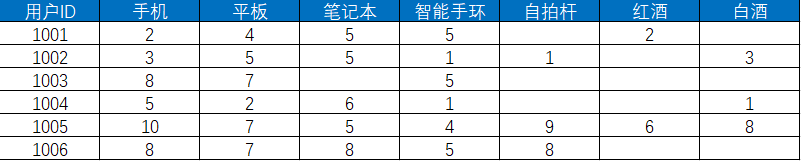
例如,我们有1001,1002,1003,1004,1005,1006这六个用户,用户对商品的行为包括浏览、收藏、下单等。我们需要对用户行为赋予不同的权重分值,比如浏览为0.1分,收藏为0.5分,整体的行为分值表如下:
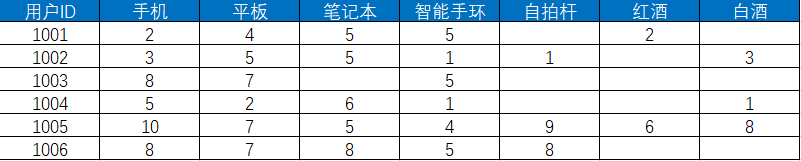
然后我们对这些用户在不同商品上的行为进行统计,得出下表。下表展示了用户对各个商品的偏好程度的分值,分值越高代表用户对商品的感兴趣程度越大。
我们可以根据余弦相似度计算用户的相似度。具体公式如下:
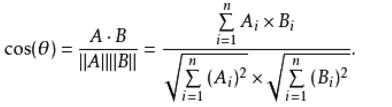
我们现在要计算 1001 和 1002 两个用户的相似程度,并将数据带入公式中:
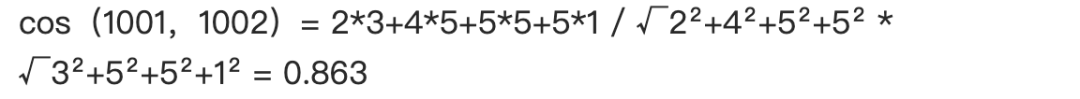
通过计算我们得出 1001 和 1002 用户余弦相似值约等于 0.863。相似值的范围是从 -1 到 1,1 表示用户之间完全相似,0 表示用户之间是独立的,-1 表示两个用户之间相似度正好相反,在 -1 到 1 之间的值表示其相似和相异。而我们刚刚得出的值是 0.863,表示用户之间的相似度非常高。同理我们可以计算出 1001 用户和其他用户的相似值。
2)将集合中用户喜欢的且目标用户没有听说过的商品推荐给目标用户
计算出用户相似度后,在相似度高的用户集合中选择相关商品,将目标用户没有浏览过的商品推荐给目标用户。
还是上面那个栗子,我们需要给用户 1001 推荐没有浏览过的商品,我们计算出和 1001 相似值较高的用户集合,假设我们设定一个阈值 0.85,并把相似值在 0.85 以上的用户喜好的商品推荐给目标用户,同时也涉及到推荐排序的问题。
我们根据以下公式进行推荐计算:
(其中S(u,k)指和用户 u 兴趣最接近的 k 个用户集合,N(i)指对物品 i 有过行为的用户集合,数学符号∩是取交集,W指用户U和用户V的相似度,R表示用户V对物品的兴趣)
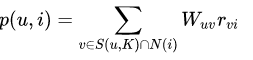
我们需要先计算出与 1001 相似的用户,通过计算得出 1002、1003、1004、1005、1006 用户的相似值分别是0.863,0.875,0.779,0.812,0.916。我们取相似值在0.85以上的用户,包括1002,1003,1006。所以可以给用户1001推荐自拍杆和白酒两种商品,1001 推荐列表不包括这两种商品。我们可以通过上面的公式来计算用户对这两种商品的感兴趣程度然后再进行排序。
- 自拍杆=0.863*1+0.916*8=8.191
- 白 酒 =0.863*3=2.589
这样我们可以将自拍杆和白酒排序,推荐给用户 1001 时,会将自拍杆排在白酒的前面。
(2)基于商品的协同过滤Item-based CF
这种算法是亚马逊最先提出来的,系统通过分析用户标签数据和行为数据,判断出用户喜好商品的类型,然后挑选一些类似的商品推荐给这些喜欢共同类型商品的用户。
比如,该算法会因为你购买过“佛珠手串”而给你推荐“茶具”和“檀香”。该算法是目前在电商领域使用较多的算法。很多朋友会觉得item CF算法和基于内容的推荐算法很类似,实际上 CF 算法并不基于商品的属性和类目来计算相似度,他主要通过分析用户行为来记录内容之间的相关性。所以算法不会计算 佛珠手串和茶具,檀香的相似度,而是喜欢佛珠手串的用户也喜欢茶具和檀香,系统就判断手串和茶具、檀香之间有相关性。
Item-based CF基本实现原理
1)计算内容之间的相似度
计算商品间的相似度同样会用到余弦相似度。两个商品产生相似关系,是因为他们共同被很多用户喜欢,商品相似度越高,说明这两个商品都被很多用户所喜欢。
这里同样用到了余弦相似度,但是公式略有不同,其中,|N(i)| 是喜欢商品i的用户集合,|N(j)|是喜欢商品j的用户集合,|N(i)∩N(j)| 是同时喜欢商品i和商品j的用户交集。
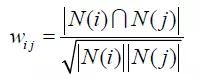
举例说明,首先我们假定有3个用户,分别为A、B、C,用户A购买了A,C两个商品,用户B购买了A,B,C三个商品,用户C只买了商品A。
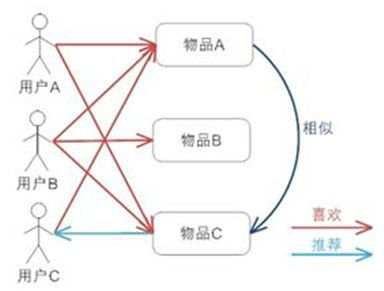
- 商品A:用户A 用户B 用户C
- 商品B:用户B
- 商品C:用户A 用户B
根据上面公式进行计算,我们先进行商品A、商品B、商品C之间的相似度计算

从以上的结果可以看出,商品A和商品C相似度最高,所以在需要推荐的场景下,系统会优先把商品C推荐给用户C。
2)根据用户的偏好,给用户生成推荐列表。
计算完商品相似度,我们需要把商品推荐给用户。如果用户近期有多个行为记录,我们先计算每条行为记录的相似值,然后可以得出多个推荐列表,我们需要将这些列表做相似值的去重和排序,需要注意的是如果重复记录在单个推荐列表相似值不高,但是多条推荐列表都有涉及到,这时我们需要提升其权重。然后根据相似值进行排序展示。
3. 其他推荐算法
除此之外,还有一些其他的推荐算法。比如基于知识的推荐,以及基于人口统计学的推荐。由于篇幅原因,在这里不详细介绍了。
全文完,感谢阅读。
作者简介:曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监,15年电商互联网经历。