前言
在设计模式的系列文章中,我们前面已经写了工厂模式、单列模式、建造者模式,在针对创建型模式中,今天想跟大家分享的是原型模式
其实原型模式在我们的代码中是很常见的,但是又容易被我们所忽视的一种模式,那么什么是原型模式呢?
原型模式其实就是一种克隆对象的方法,在我们的编码时候是很常见的,比如我们常用的的BeanUtils.copyProperties就是一种对象的浅copy,其实现在我们实例化对象操作并不是特别耗费性能,所以在针对一些特殊场景我们还是需要克隆那些已经实例化的对象的:
- 依赖外部资源或硬件密集型操作,比如数据库查询,或者一些存在IO操作的场景
- 获取相同对象在相同状态的拷贝从而不需要重复创建获取状态的操作的情况
看下我们的类图:
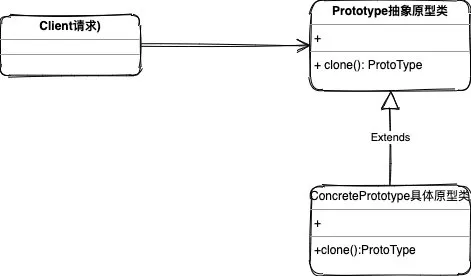
在上面的图中我们可以看出原型模式其实很简单:
- 第一个是抽象原型(prototype)声明clone方法,可以是接口可以是基类,在简单的场景下我们都可以不用基类直接具体类就可以了。
- 第二个就是具体原型类(concreteprototype)实现或者扩展clone方法,当我们在具体的原型类中的对象方法时,就会返回一个基类的抽象原型对象
针对上面理论知识,我们还是实际的举一个例子吧!
举例
假设现在我们有这么一种场景,公司搞一场活动有五万个商品参加此次活动,我们需要从后台能定时同步每个商品的销量,方便我们为后面的活动做商品分析,我们要怎么处理这个销量同步问题?
首先在这里销量和库存都是属于热点数据,但肯定都是相互隔离的因为库存是要求实时性很高的,销量可以允许有短暂延时,只要能保证数据能够最终一致性就行,所以下单的同时我们可以根据一个MQ去更新我们数据库里的商品销量。
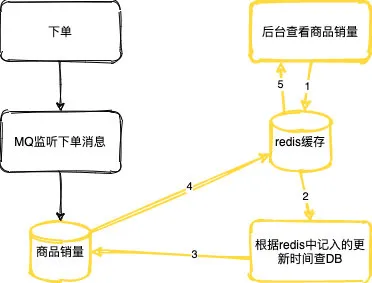
在我们去查看销量的时候我们不能每次都是去查DB所以我们可以通过redis缓存来处理,同时我们在缓存中记录一下我们当前查询的更新时间。
再次查询时通过redis数据里面的更新时间,作为查询条件去查询DB中的更新时间大于我们当前redis中的记录时间,这样就减少了SQL的扫表的行数(更新的数据与全量数据相比,更新的数据量还是占少数的)
基于上面流程我们开始写demo了
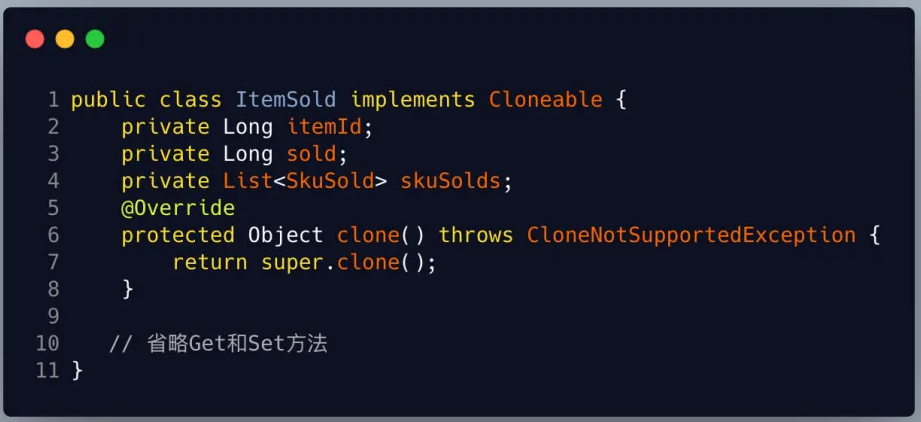
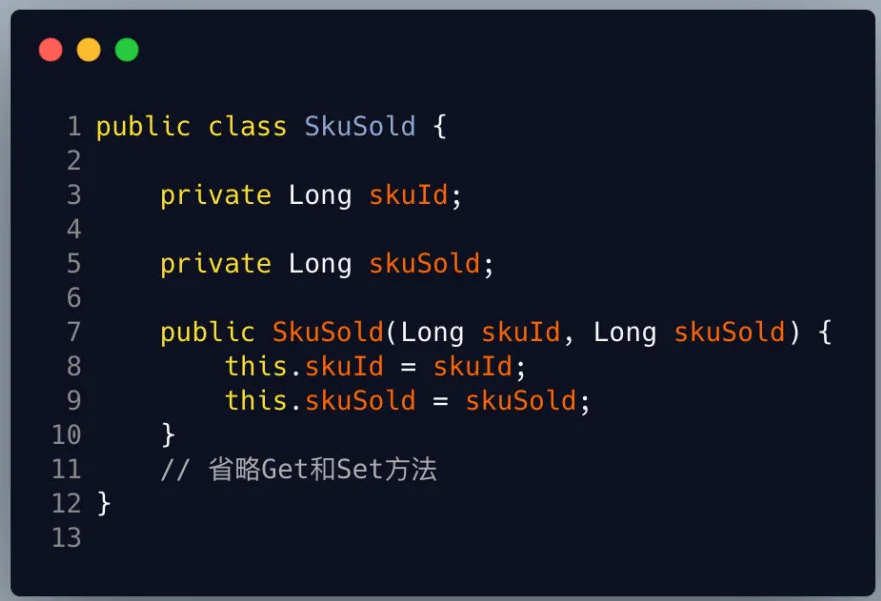
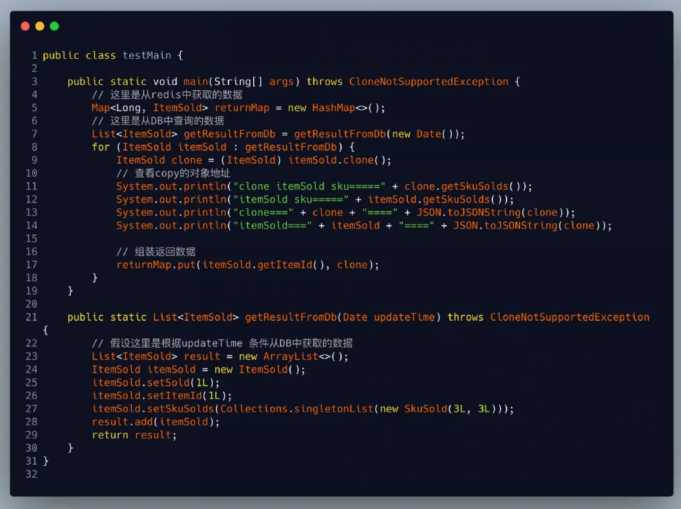

在这里demo中我们先是创建了一个ItemSold类,以及一个SkuSold类同时ItemSold重写Cloneable里面的clone方法。然后在最后的测试类mian方法中我调用了clone方法,copy一个新的商品销量类。
细心的同学在看结果的时候不知道有没有发现一个问题?在for循环里面,我分别打印出来的ItemSold 以及 SkuSold对象他们的内存地址。
复制出来的SkuSold的内存地址居然和原型地址一样,ItemSold的复制就和原型地址不一样了,针对这个问题这里我们就要聊聊原型模式的两种实现浅拷贝和深拷贝了。
- 这里说明一下我们在for循环里面是做数据convert,一般来说我们不会引用底层模型来做返回结果模型,需要做一层转化,来达到防腐的效果。为了体现深浅拷贝,所以写的比较简单,具体还是需要自己根据实际情况来做。
浅拷贝和深拷贝
- 浅拷贝:当拷贝对象只包含简单的数据类型比如int、float 或者不可变的对象(字符串)时,就直接将这些字段复制到新的对象中。而引用的对象并没有复制而是将引用对象的地址复制一份给克隆对象
- 深拷贝:不管拷贝对象里面简单数据类型还是引用对象类型都是会完全的复制一份到新的对象中
举个例子这就好比两兄弟大家买衣服可以一人一套,然后房子大家住在一套房子里(浅拷贝),当两个人成家立业了,房子分开了一人一套互不影响(深拷贝)
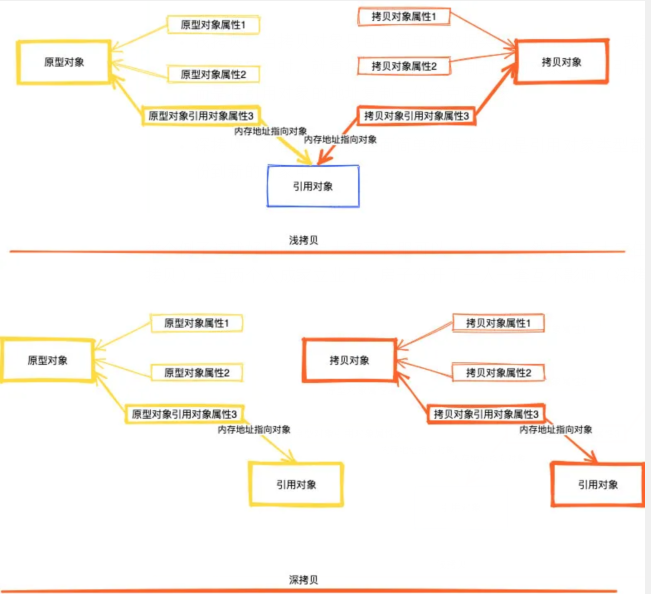
看完这张图,大家也就明白了,上面的demo是一个浅拷贝,那么我们要怎么做才能实现深拷贝呢?
首先我们先来看下 Java的提供的Cloneable 接口
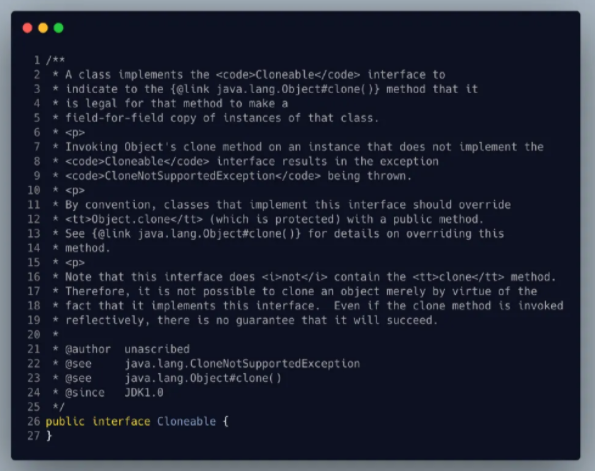
看接口上面的解释大致可以理解为:
- 一个类实现了Cloneable接口,来实现这个类的clone方法从而可以合法地对该类实例进行按字段复制,假设这个类没有实现Cloneable接口的实例上调用Object的clone()方法,则会导致抛出CloneNotSupporteddException异常。
那么我们这里怎么实现深拷贝呢?
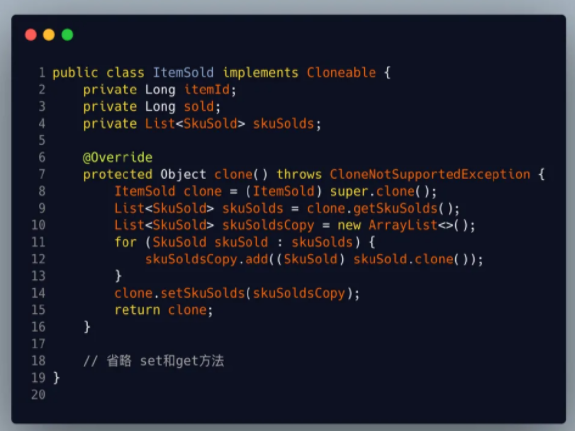
第一种:在重写ItemSold里面的clone方法时,再针对SkuSold也进行一次拷贝 (因为我们这里时List对象,只能是先拿到浅拷贝,再通过浅拷贝的List对象进行遍历再调用引用对象的clone方法来实现深拷贝)
这里如果引用对象存在多级情况下我们可能就要考虑用递归了实现,但是代码看上去就会复杂很多了。
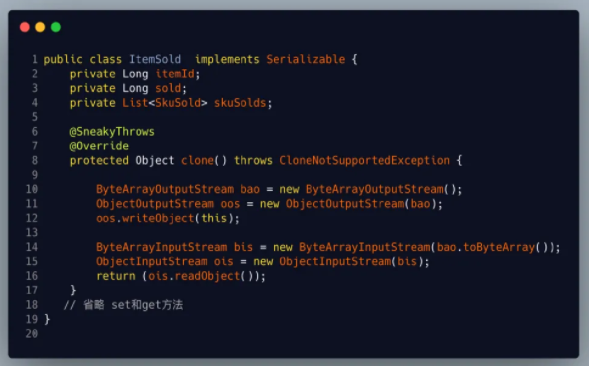
第二种:通过序列化把对象写入流中再从流中取出来
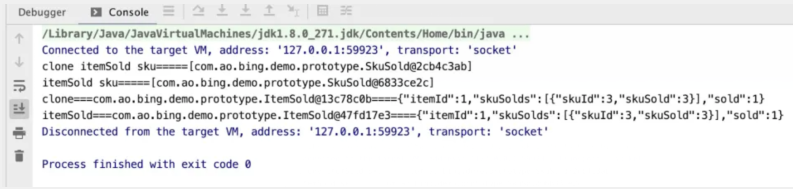
针对上面的两种写法其实都是可以实现的,但是不管用哪种方式,深拷贝都比浅拷贝花时间和空间,所以还是酌情考虑。其实在现在已经有很多针对浅拷贝和深拷贝的工具类
- 深拷贝(deep copy):SerializationUtils
- 浅拷贝(shallow copy):BeanUtils
思考
针对上面的业务场景我们也可以通过其他的方式统计商品销量,可以再通过一个MQ去增加销量的同时再去更新redis缓存,但是需要我们注意的是在针对一些核心业务数据和非核心业务数据尽量不要共用一个消费者组,防止影响核心数据的消费速率。同时我们在做设计的时候多想想这么做有什么优点,又有什么缺点,开发成本问题等。
其实在其他的地方我们可以用到原型模式,比如我们在发松活动的PUSH通知,针对平台百万、千万、甚至上亿的用户发送通知的时候通知的内容基本都是一样的只是推送用户不一样或者有些特别字段值的小改动,那我们这里就可以用原型模式来做,同时开启多线程来做push,需要注意的是这里的线程安全问题,所以在每个线程内部去做copy对象。
总结
原型模式使用起来简单,但是在我们每次在clone基类或者有引用对象的时候需要我们去修改原型对象的clone方法,这不符合我们开闭原则。
在一般情况下是不建议用这种模式的除非创建的对象成本特别大,或者在一些特殊场景使用,最后针对一些不常用的模式我不会详细跟大家分享,但是我会在后面做个分享总结,后面开始为大家分享行为型模式。
我是敖丙,你知道的越多,你不知道的越多,我们下期见!