












本文转载自微信公众号「存储灾备」,作者毕磊。转载本文请联系存储灾备公众号。
一、IOPS的理解
IOPS(Input/Output Operations Per Second)故名思意就是数据存储系统每秒能完成的I/O读写次数,即单位时间内系统能处理的I/O请求数量,是一个用于计算机数据存储性能测试的量测指标。这个存储系统可以是单块硬盘或者单台设备也可以是包含多台设备的一套存储网络系统,比如SAN或者分布式多节点系统等。
二、影响存储系统IOPS性能有哪些因素?
其实我一直想写一篇关于如何准确评估IOPS性能的文章,但是仔细一想我觉得要把存储系统的IOPS评估的非常准确,真的属实不容易,为什么呢?因为IOPS性能和许多因素相关,比如以下几个,我觉得都是比较值得一提的,每一个都会对IOPS性能产生影响(这里是针对单台或一套存储设备或存储网络):
1、系统的硬盘数量和类型
(1)硬盘数量即一套存储系统能同时管理和运行的硬盘数量是多少块,一般情况下,硬盘数量越多,整体IOPS性能会越好,可以简单的理解为堆叠;
(2)硬盘的类型,具体包括硬盘的接口类型,机械硬盘还是SSD硬盘等。机械硬盘的转速、容量(存储密度)、磁头寻道时间、旋转延迟,数据传输时间这些都和系统的IOPS性能相关联的。而固态硬盘SSD是一种电子装置,避免了传统HDD磁盘在寻道和旋转上的时间花费,存储单元寻址开销大大降低,因此IOPS可明显提高。
2、网络和接口速度
对一套存储系统来说,应用服务器和存储设备之间的网络带宽和网络接口速度以及多节点情况下各存储节点之间所使用的网络的速度也都是影响IOPS性能的重要因素。
3、应用的随机读写或者顺序读写I/O比例
根据实际的应用情况可将IOPS细分为如下几种情形:
(1)读写混合以及随机I/O负载情况下的IOPS,这个与实际I/O情况最为相符,大多数应用是要关注此指标;
(2)100%随机读负载情况下的IOPS(Random Read IOPS);
(3)100%随机写负载情况下的IOPS(Random Write IOPS);
(4)100%顺序读负载情况下的IOPS(Sequential Read IOPS);
(5)100%顺序写负载情况下的IOPS(Sequential Write IOPS)。
以上每种不同的情况下的IOPS差别是很大的,比如一般顺序的读写肯定比随机读写的IOPS值要高的,顺序的寻址时间比随机的快,示意图:
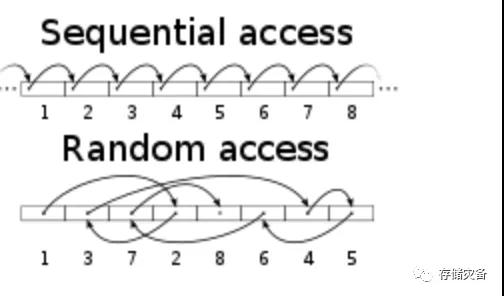
此外传统的机械硬盘读取和写入时间差不多,而大部分闪存SSD的写入速度比读要慢很多,原因是无法写入一个之前写过的区域,会强制引导垃圾数据回收功能,但总体SSD性能肯定要好于HDD。
4、Cache命中率
Cache命中率对实际IOPS有决定性的影响,Cache命中率取决于数据的分布,Cache SIZE的大小和数据访问的规则以及Cache的算法,我们这里把这些内部原理都省略掉,只强调:对于一个存储系统来说,读Cache的命中率越高,一般就表示它可以支持更多的IOPS。那么什么叫命中率呢?终端用户访问加速缓存时,如果缓存驻了要被访问的数据时就叫做命中,如果没有的话需要回到原设备提取,就是没有命中。命中率=命中数/(命中数+没有命中数), 缓存命中率也是判断加速效果好坏的重要因素之一。
5、RAID或文件系统模式
这里包含传统的RAID以及分布式文件系统等,对于顺序读写而且写性能要求高,有冗余要求的应用,选择RAID1或RAID10。顺序写要求高的数据, 应单独在一个RAID组中,避免来回寻址,典型的有Oracle的 redo log, Exchange 的 Transaction log等日志型的数据。对于有额外备份措施的数据, 没有冗余的要求, 读写性能要求高的用RAID0,比如实时数据采集。对于读要求高于写要求,随机写要求不高,容量上有考虑的,选择RAID5。对于分布式软件定义存储系统,小文件类和随机读写频繁的选择副本机制,其他的可选择纠删码模式。
6、队列深度
主要指的是端口队列中等待服务的I/O请求数量。如果I/O请求的数量超过了最大队列深度,则该事务将在一段时间无法重新尝试。使用SAS和SATA,排队的I/O请求有一定的局限,但NVMe在大大增加队列深度方面是一个重要的进步,NVMe可以提供海量的队列深度。其实加大硬盘队列深度就是让硬盘不断工作,减少硬盘的空闲时间。
7、应用线程数
线程数和IOPS的关系不言而喻,一个应用同时工作的线程越多那么自然需要更多的I/O并发,所以自然就需要更高的IOPS来支撑,反之亦然。
三、如何综合评估IOPS性能?
1、利用测试工具
对于测试工具来讲,一个请求从主机下发到存储,存储完成后返回到主机,这才算是这个I/O的一个完整周期。存储设备制造商提出的IOPS性能不保证就是实际应用下的性能,因为实际的情况多种多样。但IOPS可以通过测试程序来模拟一些不同的业务情形,建立测试模型,然后按照测试模型来实际运行,以便找到最佳的存储配置。
2、根据经验和行业参考值来估算
每种类型的硬盘都有在特定环境下的IOPS参考值或者叫理论值,个人认为如今的硬盘接口以及网络的带宽已经不是瓶颈,因为技术的发展让这些指标已经很快了。如果预估IOPS,最主要是读写比例和RAID模式的写惩罚,要有一个固定参考值,才能估算出较为接近的数值。
硬盘的IOPS参考值以及总的可用IOPS的计算公式,比如:
单硬盘IOPS = 1000ms / ((磁盘旋转延迟时间(ms) + 磁头寻道时间(ms))
系统总的IOPS=硬盘数量 × 单磁盘IOPS
系统总的可用IOPS=(系统总的IOPS×写百分比÷RAID写惩罚)+(系统总的IOPS×读百分比)
RAID5写惩罚为4,RAID6写惩罚为6,RAID10写惩罚为2,RAID1写惩罚为2,RAID0写惩罚为1,分布式多节点的以此类推。
我个人觉得如果不是那种每秒钟都有几十次以上的在线交易系统,绝大部分的业务系统的IOPS需求都是比较容易满足的。如果能估算出应用总的IOPS的需求,那么就可以计算出需要多少块硬盘了。
四、顺便提一下吞吐量
吞吐量指的是单位时间内存储系统可以成功传输的数据数量。如果前面估算出了系统的IOPS了,吞吐量也就迎刃而解了。吞吐量估算公式为:
每秒I/O吞吐量= IOPS × 平均 I/O SIZE
从公式可以看出:I/O SIZE越大以及IOPS越高,那么每秒I/O 的吞吐量就越高。对于一个存储系统来讲,这两个指标均有其最大值,而且这两个指标也是相辅相成的。
五、数据块的大小和存储性能
对于数据块很小并且随机读写频繁的应用,IOPS是关键衡量指标,比如OLTP(Online Transaction Processing)在线交易处理。而对于大数据块并且是顺序读写的应用,如VOD(Video On Demand)视频类需求,这种应用则更加关注吞吐量指标(Throughput),这时候IOPS指标就不是那么的重要了。
这里可以举例子:
比如:读取10000个1KB文件,用时10秒,虽然Throught(吞吐量)=1MB/s,但是IOPS=1000 ,对于追求IOPS的应用就有意义;
再比如:读取1个10MB文件,用时0.2秒,IOPS只等于5,但是Throught(吞吐量)=50MB/s,对于追求吞吐量的应用就有意义。
所以并不是每个应用都要追求高的IOPS的,也就是不是每套存储系统的性能都是以IOPS作为唯一的衡量指标,要根据应用的数据块大小以及应用的特性来综合判断哪个指标是最需要关注的!












