本文转载自微信公众号「yes的练级攻略」,作者是Yes呀。转载本文请联系yes的练级攻略公众号。
你好,我是 yes。
先来个,开局一张图。
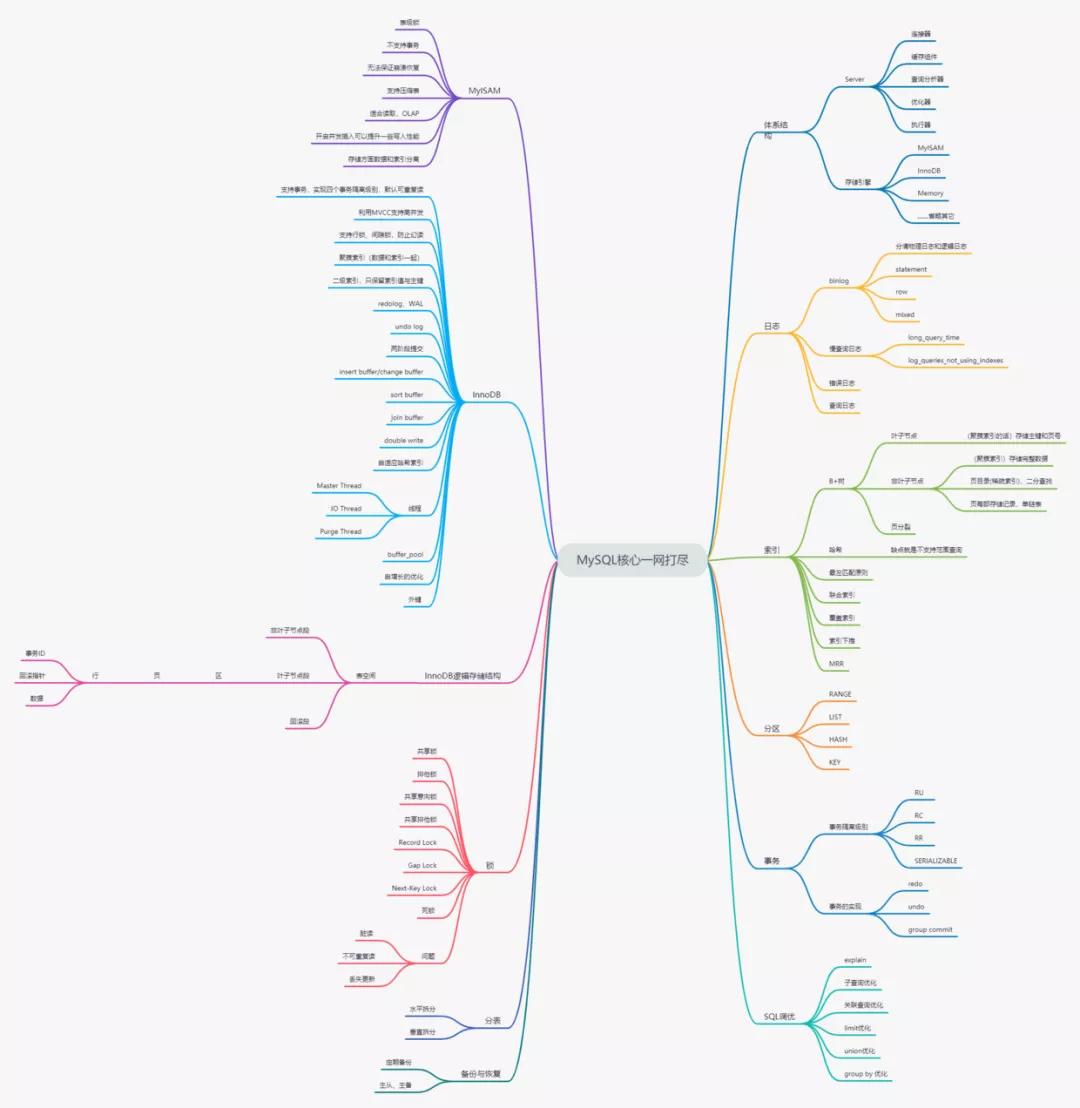
这图算是第一版本,本来还想填充地更详细些,但是看着感觉好冗余,暂时就先这样吧,主要是用来标注一些关键点,便于复习。
其实对咱们后端开发而言,对 MySQL 接触有很多,但是又接触不多。接触很多指的是我们经常写 SQL 一直在用它,接触不多指的是我们也仅仅只是写 SQL,一些配置相关的包括第一手掌控那都是 DBA 在搞。
这系列文章我就筛选出和我们开发息息相关的 MySQL 知识点。我打算先做一个总览,只 BFS,也就是说不会很扣细节,先成面。
等之后的文章再慢慢 DFS,各个击破。当然面试题也会同步更新,后面都会有滴。
MySQL 体系结构
这个非常重要,理解了之后后面的一些知识点才能懂,比如索引下推。
MySQL 体系结构可以分为两大块来看,分别是:Server 和存储引擎。
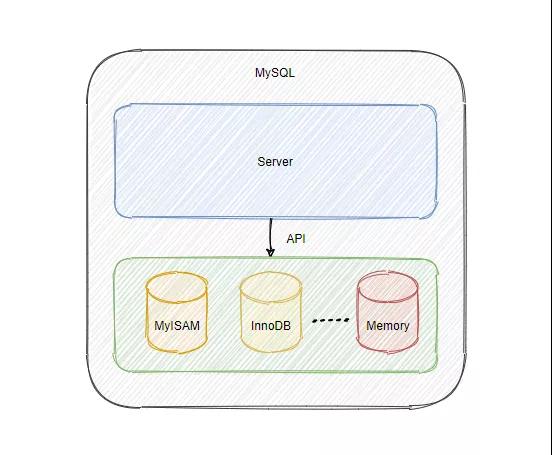
当客户端与 MySQL 建立连接之后,一条 SQL 语句经过 TCP 从客户端传输到 Server ,Server 会先将语句进行词法分析与语法分析,这个工作是分析器做的。
如果语法有问题,那这个错误相信大家都不陌生:You have an error in your SQL syntax; check the manual......
确认语法没问题之后,会再经由优化器来决策这条语句是否需要重写,如何选择驱动表,如何选择合适的索引等操作,目的就是让语句更高效的执行。
我们平日里用的 explain 其实就是让 MySQL 告诉我们它的优化决定策略是怎样的。
至此,MySQL 已经知道该做什么和怎么做了,此时就是执行器干活时候了,它会调用存储引擎的接口来执行语句。
第一个关键点来了。
例如我现在要执行一条select * from yes where name='yes的练级攻略';这条语句,name 这一列没有索引。
此时流程如下:
- Server 调用存储引擎的返回这个表的第一行这个接口,此时 Server 拿到第一行数据。
- Server 通过 where 条件判断 name 是否等于yes的练级攻略,如果是则放到结果集中,不是则跳过。
- Server 继续调用存储引擎的接口来下一行!,然后再通过 where 条件来判断。
- 如此循环往复,直到最后一行记录。
- 不会等结果全部收集完毕了才返回给客户端,等集满net_buffer大小的结果就会发送,也就是边查边发。
从以上流程可以得知,where 的条件如果用不上索引,那是在 Server 层做过滤的,如果你平日 exlplain 时候从 extra 里看到 using where,那就是在 Server 层利用 where 做了过滤的意思。
然后就是存储引擎的接口。MySQL 的存储引擎是插件式的,一个数据库里面的不同表可以用不同的存储引擎,而 Server 都是同一个,所以需要规定好统一的接口,这样 Server 才好调用不同的存储引擎。
像上面提到的返回这个表的第一行就是一个标准的接口,如果 name 这一列有索引的话,那就是走返回符合这个条件的第一行。从这里我们也可以得知走索引更好,因为这样能利用索引快速过滤得到正确的数据,不走索引就是一条一条拉到 Server 层走 where 过滤。
还有就是上面提到的 MySQL 是边查边发的,其实稍微想想就知道,如果 MySQL 要等结果集全了之后再发送数据给客户端,这样的设计不仅慢,而且如此多的查询需要缓存完整的结果集, MySQL 的内存早就挤爆了。
至此,我相信你脑海里应该可以浮现一条 SQL 的执行路径了,你已经有点感觉了。
我再来丰富一下上面的图,把优化器之类的加上去。
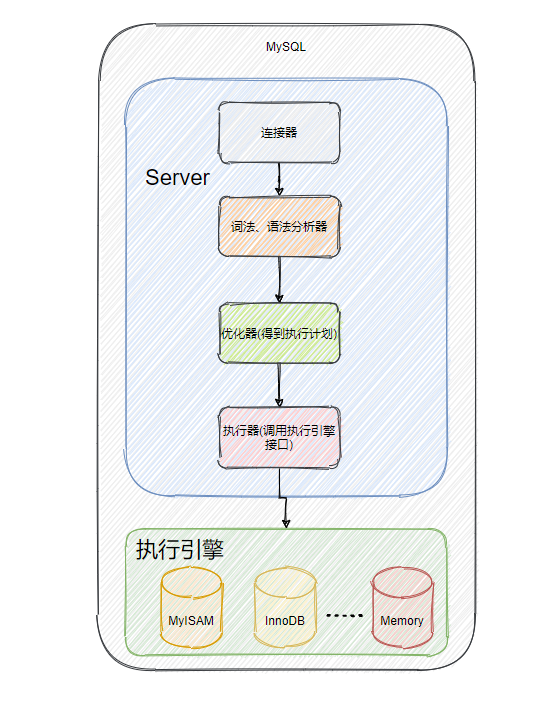
对了,你可能在别的地方会看到还有个缓存组件,用于查询缓存,具体做法就是将一个查询语句作为 key ,将上一次请求的结果作为 value,存储在缓存组件中,当同样的语句来查询的时候即可立马返回结果,不需要经历词法、语法分析等以下的步骤。
这个东西在 MySQL 8.0 之后就被砍了,并且只要表有数据改动缓存就失效了,在我们常见的 OLTP 场景下是个鸡肋,索性就不画了,清爽比较重要。
接下来,咱们看下两大存储引擎。
InnoDB 与 MyISAM
对于我们而言,最重要的是 InnoDB 这个存储引擎,而 MyISAM 作为 5.5.8 版本之前的默认引擎,那也得关注一波,毕竟人家也当了这么久的老大哥,这点面子还是要给的。
我们先来看下MyISAM
MyISAM 是基于 ISAM 引擎而来的,支持全文检索、数据压缩、空间函数,不支持事务和行级锁,只有表级别锁,它适用于 OLAP 场景,也就是分析类的,基本上都是读取,不会有什么写入动作的场景。
它的数据和索引是分离存储的,也就是不在一个文件上,并且数据库只会缓存索引文件,数据文件的缓存直接交给操作系统搞定。这有点奇怪,一般而言这种重要数据都会自行缓存管理,不过这好像也没出啥问题?(不知道是否有做什么其他处理)
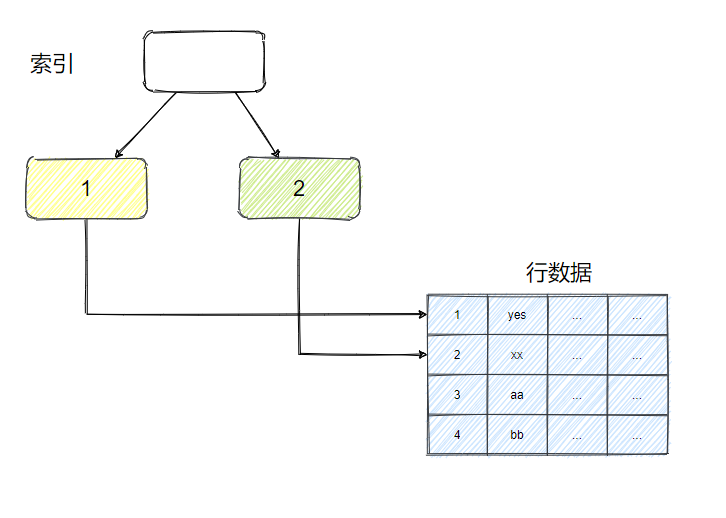
MyISAM 的索引也是 B+ 树,只是不像 InnoDB 那种叶子节点会存储完整的数据,MyISAM 的数据是独立于索引单独存储的,所以主键和非主键索引差别不大。
还有一个情况就是 MyISAM 不支持崩溃后的安全恢复,而 InnoDB 有个 redolog 可以支持安全恢复。
再有一点就是 MyISAM 写入性能差。
因为锁的粒度太粗了,不支持行锁,只有表锁,所以写入的时候会对整张表加锁。不过有个并发插入的开关,开启之后当数据中间没有空洞的时候,也就是插入的新数据是从末尾插入时,读取数据是不会阻塞的。
InnoDB
InnoDB 支持事务,实现了四种标准的隔离级别,利用 MVCC 来支持高并发,默认事务隔离级别为可重复读,支持行锁,利用行锁+间隙锁提供可重复读级别下防止幻读的能力,支持崩溃后的数据安全恢复。
对了,还有支持外键,不过一般互联网项目都不会用外键的,性能太差,利用业务代码来实现约束即可。
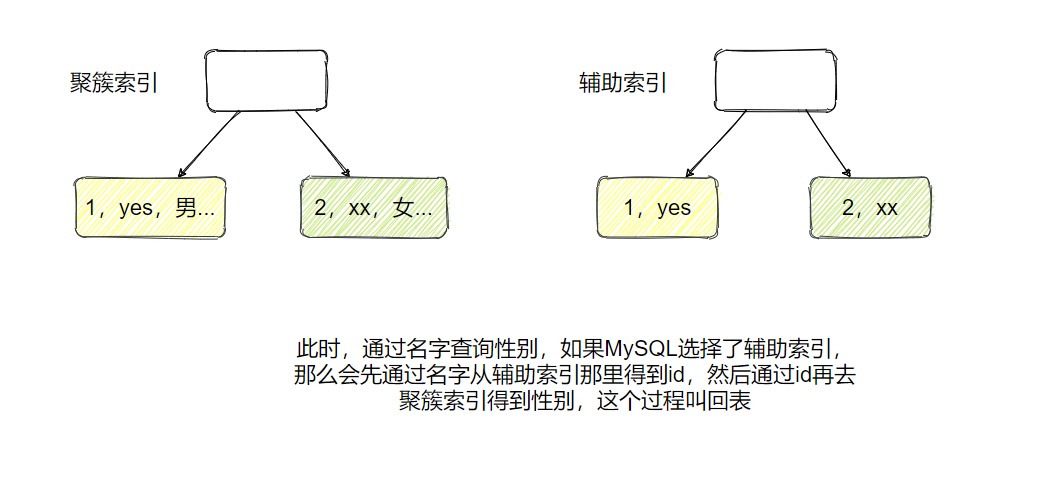
InnoDB 的主键索引称为聚簇索引,也就是数据和索引是放在一起的,这与 MyISAM 有所不同,并且它的辅助索引(非主键索引)只存储索引值与主键,因此当辅助索引不能覆盖查询的列时,需要通过找到的主键再去聚簇索引查询数据,这个过程称之为回表。
它之所以能取代 MyISAM 成为默认引擎就是因为事务的支持,崩溃后的数据安全恢复,比较出名的就是 MVCC 、Next-key Lock、redolog、WAL、undolog。
还有 changebuffer、double write、read ahead、自适应哈希索引等,这些之后的文章都会细细的盘一盘。
再提一下幻读吧,幻读指的是后面的查询结果比前面查询的结果多了,比如查询 id 大于100的人,在同一个事务里的两次查询,第一次查出 50 条,第二次查出 51 条,这就叫幻读。
而标准的 SQL 隔离级别定义里面,可重复读是预防不了幻读的,只是 InnoDB 利用 Next-key Lock 在可重复读里面实现了防止幻读的出现。
所以有些人可能会觉得奇怪,在网上看到一个表格里面说可重复读是预防不了幻读呀,怎么 InnoDB 的可重复读又可以防止幻读。
这是因为标准是标准,如何实现还是看具体的数据库。
日志
MySQL 的日志其实有很多,我们所关心的就是二进制日志(binlog)、重做日志(redolog)、undolog(回滚日志)。
还有慢查询日志、错误日志、查询日志。
这里还需要区分,什么叫逻辑日志,什么叫物理日志。
逻辑日志说白了可以认为记录的就是一条 SQL,属于逻辑上的记录。
物理日志说白了可以认为就是内存里面的某个地址的值是xxx,这样粗略的理解先,之后再盘。
对了,binlog 是属于 Server 的,redolog 和 undolog 是属于 InnoDB 的,这个要搞清楚。
索引
其实我之前写的两个故事已经把索引讲了,可以点蓝字查看。
索引这个知识点基本上等于面试必问,这里的重点就是 B+树是如何存储数据的,主键索引和非主键索引有什么区别。
这里先说下,主键索引和非主键索引,在 InnoDB 里又称聚蔟索引和辅助索引(二级索引)。
如果是主键索引:
- 非叶子节点存储主键和页号
- 叶子节点存储完整的数据
- 叶子节点之间有双向链表链接,便于范围查询
- 叶子节点内部有页目录,内部记录是单链表链接,通过页目录二分再遍历链表即可得到对应记录。
- B+ 树只能帮助快速定位到的是页,而不是记录。
- 页大小默认16k,是按照主键大小排序的,所以无序的记录插入因为排序会插入到页中间,又因为容量有限会导致页分裂存储,性能比较差,所以主键要求有序。
如果是非主键索引:
- 和主键索引的差别就在于叶子节点存储索引列和主键,没有完整的数据。
所以说不要有事没事就 select * ,因为如果本来只要查询索引列的话,直接利用辅助索引可以直接返回,然后你偏偏要select * ,那就不得不通过 id 再去主键索引查找,浪费。
然后就是 B 树、B+树、Hash 索引之类的。
Hash 等值查询优势,范围查询不行。
B+ 树相比 B 树来说,叶子节点用双向链表相连,范围查询好。
再者就是最左匹配原则、联合索引、覆盖索引、索引下推了。
最左匹配无非就是 like 需要xx%,不能%xx,稍微思考一下也不难理解,如果要查姓陈的,我通过前缀肯定能把姓陈的都过滤出来,其他的姓氏排除了。如果不给姓氏,想要找名字带陈的,我就得把所有人的名字都扫描一遍才能知道。
然后就是多列索引的时候,必须给最左侧索引作为查询条件,才能利用上索引。
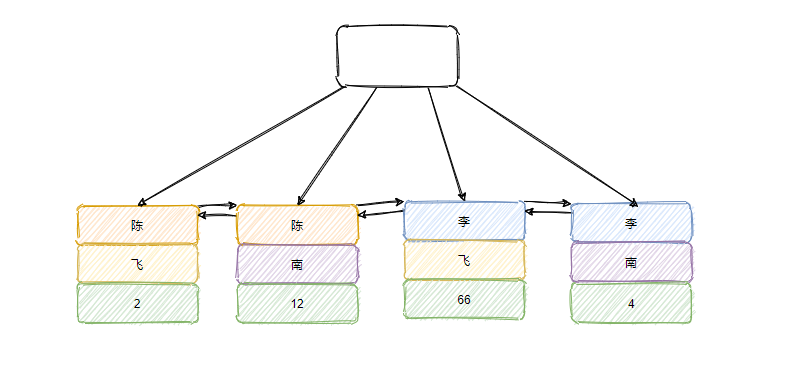
例如上面这样的一个多列索引(姓,名),如果你的查询条件有姓氏,那就能用上索引,如果没有姓,只有名字,则用不上。
再说联合索引,拿上面的例子来说,如果你分别建立了姓和名两个索引,但是经常两个条件放在一起查询,那么就应该将两个索引合二为一,变成上面所说的多列索引,也就是联合索引。
当然上面的例子不恰当,姓名往往放一个字段就行,我就是举个例子。
之所以把索引联合了是因为索引的维护需要开销,举个简单的例子,如果你插入一条数据,那么不仅要插入主键索引,你所有的辅助索引都需要插入,那索引多了,开销自然就大了,删除更新也是一样。
覆盖索引,指的是利用辅助索引可以直接返回数据,虽说上文已经提了,我还是再说一遍。
比如select 名 from yes where 姓 = 陈,这就是利用上面的索引直接返回,因为索引的列覆盖了需要查询的结果,如果你来个 select age,那就需要去主键索引查询了,因为辅助索引没有 age 这一列的数据。
索引下推,还是拿上面的索引作为例子,此时要执行select * from yes where 姓 = 陈 and 名 like %南%如果没有索引下推,那么查询的情况就是只能利用姓这个条件,会把 ID 为 2 和 12 的数据都返回,然后都需要回表,再利用 Server 的 where 来做过滤。
而如果用上了索引下推,那么会把名 like %南%这个过滤条件也下推给索引,在取出结果之前先通过 where 过滤了,然后再得到数据,这样直接就排除了 ID 为 2 的数据,只需要回表 ID 为 12 的数据。
其实我以前就认为查询本就是按索引下推的方式来查的,想不到这是 5.6 版本之后才出的一个优化。
后来理解了 MySQL 的体系结构之后觉得也正常,毕竟存储引擎就是个没有感情的数据读写工具人,就像饮水机(存储引擎)只会出冷水或者热水,适合温度的水还需要你(Server)自己调。只不过现在科技在进步,所以搞出了可以直接出合适温度的饮用水的饮水机。
对了,索引下推只能在辅助索引上用,这应该不难理解吧。
最后
暂时第一篇就写这么多了,知识点还是很密集的。
这篇大致就写了思维导图的右上角的小部分,而且还没有很深入,我是打算把思维导图上的东西先粗略地过一遍,然后再逐一击破。
不过其实也不是很粗略,我觉得大体的重点还是讲明白了的吧?如果有建议或者错误欢迎骚扰。