动机
为什么是7方面的问题?虽说7面只比6面多了一面,又比8面少了1面;然而并非刻意为之。存储领域内的很多知识,可以归结于7个方面: 复制、存储引擎、事务、分析、多核、计算和编译。
分布式存储
什么是分布式存储呢?如果一个存储系统,不管是对象、块、文件、kv、log、olap、oltp,只要对所管理的数据做了Partitioning&Replication,不管姿势对不对,其实都可以归纳于分布式存储。分布式存储就是:Partitioning以多机scale,Replication以灾备容错。
1. 复制
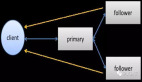
复制是解决可用性,可扩展性和高性能的关键。为了灾备,数据需要冗余存储;为了高可用,服务需要hot standby。缺乏灾备的系统难以在生产环境使用。元数据和数据的维护均离不开复制,复制可转移而不可消除。复制引出了多副本一致性问题,而一致性保证需要考虑各种软件和硬件故障,以及误操作。共识算法和复制日志是解决复制问题的核心,具体涉及:
- 故障检查,租约协议;
- 选主算法,primary uniqueness invariant,网络隔离,脑裂,双主,拜占庭故障,failfast/failstop,failover;
- 日志复制,RSM;
- membership change,或者config change,主机上下线管理,扩缩容;
- 数据复制,data rebalancing,data recovery;
- 副本放置逻辑和副本路由逻辑;
- primary和backup之间如何fence?
- 外部一致性,线性一致性;
- pipeline,fanout,primary-backup,quorum-based,gossip;
- 分布式日志,active-standby架构,active-active架构;
- ……
2. 存储引擎
此处的引擎是指本地的持久化存储引擎,持久化存储引擎要考虑CPU和memory系统和持久化设备之间的速度和带宽差异,可以总结为1-3-5。
1-3-5
1是指fsync的调用,以及和fsync地位等同的函数的调用。调用次数,调用频率,在多少数据上施加调用等。设备的带宽和利用率是否合理,fsync的调用怎么均摊到更多io次数和吞吐之上呢?
3是指读/写/空间的放大。怎么tradeoff,牺牲一个保住其他两个呢?
5是指WAL的5个LSN,分别为prepare point,commit point,apply point,checkpoint,prune point。
- 处于prepare point和commit point之间的数据需要group commit;
- 处于apply point和commit point点之间的提交数据需要apply到内存的数据结构之上以后对读可见;
- 内存数据结构需要以一定的调度策略存档于持久化设备, checkpoint就是存档点;
- recover from crash需要从最近的checkpoint点恢复到commit point;
- 而一段checkpoint完成,则截止该checkpoint的日志可以截断,因此存在一个不大于checkpoint的点,是为prune point,截止改点的日志和老的on-disk镜像可以安全删除。
- 因此这5个点始终保持一条约束:它们之间存在全序关系。
数据结构和算法
内存和磁盘数据的管理,需要用到丰富的数据结构和算法。此外解压缩和编解码算法用于降低数据的size,也很有意思。
3. 事务
事务是指ACID,很多存储系统,其实可以用事务做baseline进行分析,看这个系统在原子性,一致性,隔离性和持久化四个方面的设计究竟走多远。其实事务反应了正确性和并发性的折中。作为事务的使用方,理论上(实践上未必),并发访问存储系统时,不需要担心结果不正确的问题。假如这种担忧存在,一定是事务处理上,牺牲了某些正确性,偏向了并发性,将错误处理和选择权交给了使用方处理,使用方需要额外花费心智在客户代码中插入fence代码和做容错处理。
存储引擎部分,其实已经或多或少地涉及到了事务处理的提交协议,提交协议主要解决事务的A和D。事务处理的核心是并发控制(concurrency control)协议。并发控制主要解决这样的问题:
- 两个并发事务冲突(读写,写读,写写),应该怎么处理呢?加锁等待还是检测到冲突主动夭折呢?
- 已经提交的事务对数据库的影响,怎么对当前outstanding事务的读操作可见呢?
这两个问题本质是隔离性和一致性,冲突事务加以同步,前置的提交事务对后置outstanding事务可见。
理想的正确性是这样子的:所有的事务,不管是否存在冲突,都一个一个串行执行,时间上没有任何重叠。理想的并发性是这样子的:所有事务都没有冲突,可以以最佳的并行度同时执行。但现实是冲突始终存在,解决冲突,意味着在并行执行的某个环节插入了同步点,需要判断和仲裁是否有冲突。
冲突等待,是lock-based CC协议;冲突夭折重试,是timestamp ordering CC协议。前者就是所谓的悲观事务,后者则为乐观事务。事务处理在Jim Gray的书中和知名教材里其实已经讲得很清楚了。这里只提一下乐观事务的冲突检查的直观性的简单的理解:两个事务存在两种定序方法,一种是由TSO分配的时间戳确定的顺序,一种是由数据依赖(WAW,RAW,WAR)确定顺序。如果这两种顺序破坏事务之间的偏序关系,那么这两个事务必然冲突,可以选择让一个事务夭折并且重试。
定序是一个比较关键的问题,比如乐观事务的begin和commit的时间戳分配,悲观事务的基于时间戳的死锁预防也会用到时间戳的分配。
存储系统自身做了partitioning之后,单个partition的事务处理可下沉于本地存储引擎,然而如果一个操作涉及对多个partition的修改,则需要考虑跨partition的事务处理能力。其实分布式事务并没有一个清晰的定义,但蕴含了“跨(across)”的意思,不管是提交协议还是CC协议,都依赖于分布式存储系统的实现或者单机事务的实现。虽然有很多文献中反复用到2PC和3PC,但有时候是指提交协议,有时候是指CC协议,有时候是指提交协议和CC协议的混合体。
事务给存储系统的行为做出了明确的定义和保证,从事务的角度可推测系统的实现,比如加锁的粒度,多版本的管理,全局同步点,怎么处理write-too-late问题。
4. 分析
分析处理涵盖的东西太多了。从一个角度看,是怎么实现SQL语言;从另一个角度看,是怎么实现一个分布式系统由SQL驱动起来工作。一条文本的SQL语句,历经分词,语法分析,访问catalog和语意分析,关系代数的等价变化,形成逻辑的查询计划,然后根据数据的分布,算子自身特点和计算资源状况,生成物理执行计划。
一条SQL可以对应多个逻辑执行计划,一个逻辑执行计划,对应多个物理执行计划。比如join的顺序,join的算子的实现。谓词过滤时谓词的顺序,谓词是否下沉。一个关系代数的算子,有多种的不同实现算法,而多个关系算子,不同的计算顺序也会有不同的执行效率。根据先验知识,使用启发式的策略;或者利用数据分布的统计信息,采用某种cost估算模型;又或者根据已有执行经验,自适应地调整到最优或者次优的执行计划。
在计算层,通过三大优化策略parallelism,pipelining和batch加速处理。比如数据经过parititioning形成多个partition,放置于多机上,采用MPP的方式,做多机的并行处理。计算的过程可以看成是把关系作为输入,流经执行树的叶子节点,汇聚于根节点,每个节点的对应算子的具体算法实现所输入数据进行处理后输出。从计算模型的角度看,有这么几种情况:
- tuple-at-a-time:采用了迭代器的模式,当前迭代器执行get_next时,调用child算子对应迭代器的get_next获取计算所需的输入tuple,然后执行一段计算代码,产生一个输出tuple,发射parent算子。
- full materialization:每个算子接收到全部的输入数据,计算出输出结果,交给下一个算子计算。这种方式类似于批处理。
- vectorized execution:数据在内存中按列存储,以数组表示。选择数组的大小,让其可以在L1 data cache中装得下,然后执行树的每个算子执行tight for-loop按数组处理数据。这样即避免了full materialization过多的资源索取,又能避免tuple-at-a-time的处理单个tuple的overhead,同时对cache更加友好,减少spurious invalidation,提升speculative cache missing的产生。同时简单tight for-loop,编译器能更好点编译成高效执行指令,同时也能更好地填充CPU的指令流水,充分利用CPU的multiple issue的功能加速简单指令的处理。
在存储层,数据采用列式存储,可获得很好的编码效率,降低读放大和空间放大,访问持久化存储的带宽被高效利用,CPU和Memory的带宽增速相对于持久化存储带宽增速表现出了显著的差异,使用CPU的计算交换磁盘带宽,提升了数据的处理能力。
列存,向量化执行引擎,MPP是现代分析性数据库的关键技术。
5. 多核
从编程实现的角度看,多核scale,CC协议,共识算法是计算机中比较有挑战,并且是纯自然的问题。即便技术上不深入接触数据库,也对这三个问题相当地痴迷,被数据库技术的吸引加入这个领域,或多或少和这三个问题相关。
为什么多核如此重要呢?
假设摩尔定律,没有功率墙的限制,世界会怎样呢?显然我们不需要修改老代码,只要增加单核晶体管数量,老代码自然而然会提升。我们撞到了功率墙后,发现需要增加核数以提升计算速度。现在问题来了,我们的代码已经写成了多线程执行,那么随着核数增长,修改worker线程池的大小,老代码的计算能力会随着核数增加而持续增加吗?显然不是这样,因为多核上的scale受到阿姆达尔定律的制约,当代码中串行执行的部分占比1%时,256核机器只能最多加速到72倍,如果是10%,只能最多加速到10倍。显然修改线程池的大小,并不是一个好方法,减少代码中contention才是关键。
这种情况下,speedup想要随着核数而scale,发现很多算法,数据结构,CC协议和分析处理的算子实现,需要case-by-case重构以减少contention,重构方式是采用lockfree算法。但是这还不是事实的全部,当面对多核scale时,其实我们面对的是一个新的分布式系统,这个新的分布式系统是以interconnect为网络,以核为计算资源,并且还需要考虑屏蔽内存体系的延迟。如果说原来的分布式系统中,我们倾向于每个机器各干各的,数据做到均衡,计算资源就可以充分利用。对于多核编程同样有这个问题,怎么将原来的任务均匀地拆成多个子任务,然后多个子任务可以齐头并进,几乎同时冲线结束。显然数据拆分不均衡,跨核通信等因素都会造成快核等慢核的问题。同时,多核处理时,倾向于协作完成一个共同的任务,而非各干各的,这种情况下,将任务均匀拆分成子任务的的调度代码,共享的数据结构的访问代码,多核彼此之间等待本身就是同步点,即contention,总之,contention怎么降低呢?
现实中,lockfree算法,怎么描述和验证正确性呢?我们对比其他两个问题的思路,或许有解法。比如共识算法中,采用invariant描述算法;而CC协议中,采用反例(anormaly)攻击算法。或许这两种方法相互结合,能够帮助我们研究lockfree算法。
多核scale的挑战性很大,但这可以让具有优势的传统数据库和数据库的新进入者,处于赛道的同一起跑线,比拼谁的代码case-by-case优化做得好。
也有不少团队,在思考异构计算加速数据处理,这同样充满机会。但是,依靠程序员的心智构造精巧而高质量的代码,费时费力。或许的确应该通过编译器的后端技术一劳永逸解决这类问题,现在做不到,不代表未来也做不到。到时候,有人看着前人写得如此复杂的代码,就好比我们现在看到泥板书和带孔的卡片。
6. 计算
计算主要讲执行引擎, 执行引擎是一个很大的scope,目前roadmap已经建立,但是缺乏baseline,待两者都ready之后,会补充。
7. 编译
编译对数据库的渗透是全方位的:比如计算引擎在向量化之外可采用编译技术优化性能。数据库中很多case-by-case的性能优化,需要深入研究体系结构,异构计算加速处理也需要使用编译技术。流批DSL脚本使用现有的SQL执行引擎做计算,UDF扩充等。目前动机已经明了,但roadmap和baseline尚未建立,两者ready之后,也会补充进来。