大数据、人工智能( Artificial Intelligence )像当年的石油、电力一样, 正以前所未有的广度和深度影响所有的行业, 现在及未来公司的核心壁垒是数据, 核心竞争力来自基于大数据的人工智能的竞争。所以不论是计算机专业的程序员,还是非计算机专业准备转行计算机的跨行人员都想学习大数据,从事大数据开发工作。
但是当你站在一个行业门外的时候,你更多的是看到他的价值和前景,这会促使你义无反顾地往里冲。但当你想要跨越这道门槛入门的时候,你开始考虑技术层面的困难,什么困难呢?那就是我对这个行业知之甚少,这个行业是否与我的想象相符?是否和我的发展方向一致?我应该从哪里开始?应该如何快速入门?
大数据这个行业也是一样,好像这个互联网时代,不知道大数据就落伍了一样,但很多一部分人也只限于了解了大数据这个词,并加上自己想象的定义。
那么大数据到底是什么?用来做什么?如何开始大数据的学习呢?今天我们从技术的角度来深入浅出聊一聊。
首先,大数据到底是什么?大数据只是一个统称。广义上,像大数据开发、大数据分析、大数据挖掘等对大数据的操作都可以统称为大数据。狭义上:大数据是指在一定时间范围内无法用常规的软件分析工具进行处理的数据集。所以从定义可以看出来,大数据最原始的本质其实就是数据集,只是数据集的规模、体量很大,大到我们无法接受使用常规软件处理所花费的时间。
大数据用来做什么?我们已经明确了大数据就是数据集,那么数据集用来做什么,当然是通过对数据集进行处理、分析,提取有用的信息用于各种业务之中。所以大数据的作用也是如此,通过提取大数据中有价值的信息,再利用这些信息进行业务赋能,促进智慧城市建设、企业用户画像、人工智能仿生、医疗疾病诊断等政、企、研、医行业的发展,为行业领域带来新的价值空间。
既然大数据有如此多的应用场景、广阔想象空间的发展前景,那么如何开始接触学习大数据呢?
为了大家能够真正明白,也为了能够达到深入浅出的效果,我们在下面说明大数据的各种处理手段时会经常拿常规数据和大数据来对比解释。
首先大数据的数据属性就决定了他的操作空间(处理流程),无外乎数据采集→数据存储→数据计算→数据应用。这些操作的背后几乎涵盖了当前大数据行业的所有产业链。
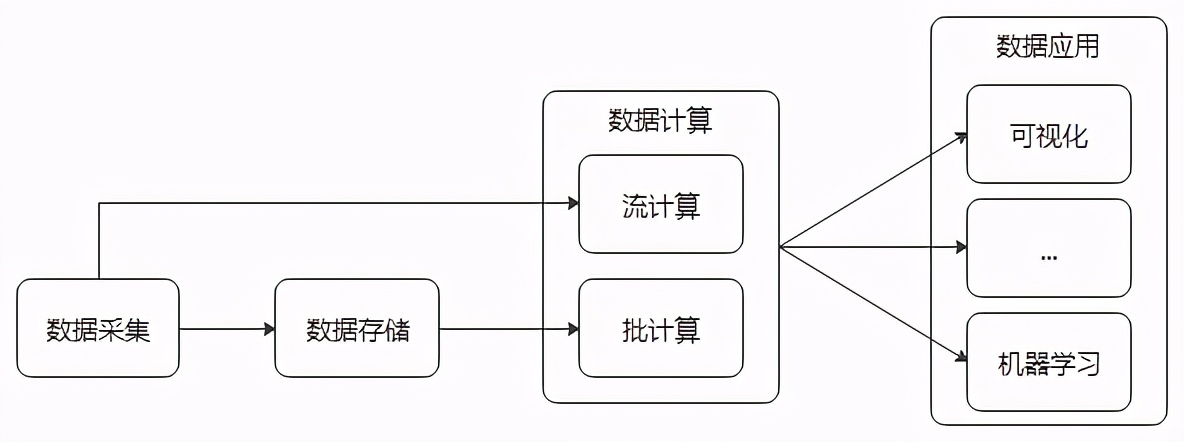
大数据处理流程
大数据采集是大数据整个体系的起始端。我们首先需要获取数据,传统数据的获取方式,比如学生信息的获取,我们可以采用Excel手写输入的方式获取。但是在这个互联网时代,动辄百万条、千万条数据,又有各种各样的数据源,比
如数据库、日志、物联网传感器等等,我们不可能再通过人工或常规Excel的方式去实时获取、汇总数据,这时候就需要针对这种超过普通数据集定义的超大数据集采用专门的采集工具,来提高数据采集效率,使每秒产生的成千上万数据能够及时被采集到指定的存储介质上,不产生数据积压,避免造成数据丢失。使用专门采集工具高效采集数据的过程就被叫做大数据采集。大数据采集,根据采集的数据源不同(数据库、日志、物联网信号...),采集的数据类型不同(结构化数据、半结构化数据、非结构化数据),会用到诸多适应于各自场景的采集工具,比如:Flume、Sqoop、Nifi...
Flume是Cloudera提供的(后来成为Apache开源项目)一个高可用,高可靠的,分布式的海量日志采集、聚合和传输的工具。主要用于采集日志类数据,由于Flume可以通过配置采集端采集模式(spooldir、exec)从而可以做到文件目录内新增文件的增量采集、文件内新增文件内容的增量采集。Flume还可以通过配置自定义拦截器,过滤不需要的字段,并对指定字段加密处理,将源数据进行预处理,实现数据脱敏。
Sqoop是在Hadoop(后面会介绍)生态体系和RDBMS体系之间传送数据的一种工具。最常用的还是通过Sqoop将RDBMS体系(Mysql、Oracle、DB2等)中的结构化数据采集并存储到Hadoop体系(HDFS、Hive、Hbase等)的数据仓库中。
Nifi,由于Nifi可以对来自多种数据源的流数据进行处理,因此广泛被应用于物联网(IoAT)的数据处理。
通过上面的主流工具,我们基本上能解决99%种场景下的数据采集工作,数据采集完之后,就要面临一个不得不考虑的问题:采集的数据存在哪里?
常规数据可以存在硬盘、存在传统单机数据库。但大数据时代呢?由于数据量爆炸式的增长,单块硬盘或单机数据库已经满足不了我们的存储要求了,我们需要更大的存储空间,要能够随着数据的增长而增加空间,使我们的数据全部存下不溢出。这样就有两个方向:一个是堆硬件,提升硬件质量,开发更大存储能力的硬盘或存储介质;一个是堆数量,找更多块硬盘来把数据按块存放在不同的硬盘上。
大数据的存储解决方案就是第二种,选择更加廉价、高效、可扩展的横向扩展方式来满足数据存储。既然选择堆数量的方式来存储大数量级的数据,那就还要解决一个问题,那就是查询问题。数据可以分批放入不同的硬盘中,我获取的时候如何准确快速的找到想要的那一条数据,放在哪个盘、哪个文件的第几行呢?这就需要专业的大数据存储工具来解决这些问题,实现分布式存储情况下每台节点数据量的平衡、数据冗余备份防止数据丢失、数据建立索引实现快速查询等。目前大数据中用到的主流存储系统有哪些呢?比如:HDFS、HBase、Alluxio...
HDFS是Hadoop三大组件之一(另外两个组件分别是:资源管理组件——YARN,并行计算组件——MapReduce),是一个分布式的文件存储系统,在大数据存储系统中具有不可替代的作用。从各种数据源采集的数据一般都是存储在HDFS,HDFS支持数据的增删改查,类似于传统数据库,不过在大数据系统中,我们称之为“数据仓库”。
HBase是一个分布式的NoSql数据库,分布式的特点以及面向列的存储特性,使得HBase在大数据存储领域应用广泛,主要用于存储一些半结构化数据和非结构化数据,并且可以结合phoenix(感兴趣的朋友可以自行百度了解)来实现二级索引。
Alluxio原本叫做Tachyon,是一个基于内存的分布式文件系统。它是架构在底层分布式文件系统(比如:HDFS、Amazon S3等)和上层分布式计算框架之间(比如后面会提到的MR、Spark、Flink等)的一个中间件,主要职责是以文件形式在内存或其它存储介质中提供数据的存取服务,减少数据IO性能消耗,加快计算引擎加载数据的速度。
如果数据采集之后,只是存储在数据仓库之中,那么这些数据没有任何价值,也无法推动、促进我们的业务。所以,数据存储之后,就是要考虑数据计算的问题了。数据如何计算呢?传统的软件分析软件Excel、Mysql等无法承载海量数据的分析,因为设计之初,考虑到的数据上线就远远达不到大数据的入门门槛标准。我们就要寻求一些专业的大数据量的分析计算软件来应对不同特点数据集的数据计算。数据计算从处理效率来分,可以分为:离线批处理、实时处理。如果从处理方式来分,可以分为:数据分析、数据挖掘。
我们先以离线批处理和实时处理两个角度来了解数据计算处理工具。
大数据兴起之初,人们对数据处理的时效性没有现在要求那么高,更加注重时间和成本的平衡,基本只是面向“天”为粒度的离线计算场景,就是在第二天才开始处理前一天的数据。在这种场景下就诞生了MapReduce,Hadoop三大组件中的并行计算组件。MapReduce计算主要是利用磁盘来进行中间结果数据的暂存,这样就造成数据的计算过程,数据不断在内存和磁盘间IO,影响了计算效率,在一些数据量比较大的情况下,一个MR(MapReduce的简称)任务就能跑一天。MR计算不止慢,MR框架使用还有一定的开发入门门槛,所以后来又出现了一个数据计算工具——Hive,Hive对复杂的MR程序开发say no!开发人员只需要懂SQL语言就能够进行数据的增删改查,Hive会将你的SQL语句在计算机实际计算前转换为MR计算任务,虽然速度还是一样的慢,但是降低了程序员的开发门槛。
随着数据应用的不断深入,大数据体系的不断完善,数据的价值越来越随着时效而凸显,所以越来越多的人对数据的时效性提出了更高的要求。在这种情况下,人们开始需求更快速的数据计算工具,这就诞生了后来的Impala、Presto等一系列基于纯内存或以内存为主的计算引擎,大大缩短了数据的处理时间,提高了数据信息提取的效率,使数据产生了更多的商业附加价值。
人们在一些特定场景下,对于数据处理的效率要求是没有上限的。比如,电商系统的实时推荐、双十一天猫的监控大屏等,最深入人心的就是12306车票实时统计。于是,实时流计算的场景就逐渐产生了,这也催生了后来的Spark、Flink这一类实时计算引擎的发光发彩。流计算是指对持续流入的数据立即进行处理,但是谁也不能保证我上游数据一定是匀速写入,这就需要引入一个叫消息中间件的消息缓冲组件,比如:Kafka、RocketMQ、RabbitMQ等,主要作用就是起到一个限流削峰的作用,就好像一个蓄水池,对于某一时间涌入的大量数据进行暂存,然后以一个匀速的速率传递将消息分批传送到实时计算引擎进行数据实时计算。
Spark是一个基于内存的计算引擎。Spark的功能组件可以细分为SparkCore、SparkSql、SparkStreaming、GraphX、MLlib。SparkCore、SparkSql主要是用来做离线数据批处理,SparkStreaming则是用来做实时流计算,GraphX是用来做图计算,MLlib是一个机器学习库。Spark Streaming 支持从多种数据源获取数据,包括 Kafka、Flume、Twitter... ,从数据源获取数据之后,可以使用诸如 map、reduce、join 和 window 等高级函数进行复杂算法的处理,最后再将计算结果存储到文件系统、数据库...中。
Flink认为有界数据集是无界数据流的一种特例,所以说有界数据集也是一种数据流,事件流也是一种数据流。Everything is streams,即Flink可以用来处理任何的数据,可以支持批处理、流处理、AI、MachineLearning等等。
主流数据计算工具了解之后,我们再从数据分析和数据挖掘的角度讲一下数据计算。
数据分析,一般指分析的目标比较明确,比如要从一堆学生信息中筛选出来性别为男的学生数量就是一种数据分析,是明确了x和转换函数f的情况下去获得y值。而数据挖掘则是通过数学建模、在给定x和y的情况下,让机器去发现使两个值等价的若干f函数并利用其他数据集,去不断验证获得最匹配的f,最终利用f去目标数据集进行分析,获取隐藏的数据关联。
总体来说,数据挖掘更加具有开放性,能够用来从海量数据中找到人们没有认识到的隐藏规则。目前比较常用的数据挖掘的机器学习库主要有SparkML、FlinkML(这里就不展开了)。
数据计算之后需要以业务需要的方式展示出来,这样才能使不同的决策部门利用数据进行辅助决策,所以数据展示的方式就很重要,他能影响到数据的直观性和数据的价值体现。而大数据系统中常用的数据展示工具有ECharts、Kibana等...
Echarts是百度开源的一个基于JavaScript的数据可视化图表库,用于提供直观,生动,可交互,可个性化定制的数据可视化图表。
Kibana是ELK三件套中的展示组件(其他两个组件为:日志收集组件——Logstash,分布式搜索引擎——Elasticsearch),提供有好的Web界面展示界面,能够让你对 Elasticsearch 数据进行可视化。
以上介绍了大数据的整体处理流程和对应流程使用的工具组件。其实除了以上数据处理直接相关的组件,大数据系统的稳定高效运转还离不开一些辅助性或工具性组件,比如ZooKeeper、Oozie、Hue等...
ZooKeeper简称ZK,是一个分布式系统的可靠协调系统,在大数据体系中应用广泛。HDFS、YARN、HBase、Kafka(未来可能移除ZK支持,使用内置替代方案)...等组件广泛采用ZK实现高可用系统的主服务协调管理。
Oozie和Azkaban类似,都是一个定时任务调度组件,用来管理Hadoop作业。Oozie可以将很多不同的作业(如MR、Java程序、shell脚本、hivesql、sqoop、spark等)按照特定的顺序,或串行或并行的组合成一个工作流,上流任务完成后会自动触发下流任务的执行,达到连贯调度的目的,能够极大的提高开发效率。
Hue是一个可视化的大数据组件集成系统,能够集成Hive、HBase、HDFS、Spark等,实现界面可视化操作,对于数分析工程师来说不用自己实现代码开发,直接在界面进行SQL语句操作或拖拽操作就能利用这些集成组件完成数据处理。
以上就是大数据系统的一个系统性介绍,包括了大数据推进历程、大数据处理流程、大数据技术体系等,了解并掌握以上大数据处理流程,熟练运用各种工具进行数据采集、存储、计算、展示,基本就可以算得上是一个合格的大数据工程师了,如果想更深层次的发展,就需要了解主流大数据组件的特性、各种处理工具的原理和调优、大数据组件接口的二次开发等等。
最后说一句,任何时候都不要忘记从官网获取我们想要知道的关于大数据处理工具的一切特性,养成从官网学习新知识、新技术、新框架的习惯!