神经网络实际上就是在学习一种表示,在CV领域,良好的视觉和视觉语言(vision and vision-language)表征对于解决计算机视觉问题(图像检索、图像分类、视频理解)至关重要,并且可以帮助人们解决日常生活中的难题。
例如,一个好的视觉语言匹配模型可以帮助用户通过文本描述或图像输入找到最相关的图像,还可以帮助像 Google Lens 这样的设备找到更细粒度的图像信息。
为了学习这样的表示,当前最先进的视觉和视觉语言模型严重依赖于需要专家知识和广泛标签的训练数据集。
对于视觉相关的应用场景来说,视觉表示主要是在具有显式类标签的大规模数据集上学习的,如 ImageNet、 OpenImages 和 JFT-300M等。
对于视觉语言的应用来说,常用的预训练数据集,如Conceptual Captions和Visual Genome Dense Captions,都需要大量的数据收集和清理工作,这限制了数据集的大小,从而阻碍了训练模型的规模。
相比之下,自然语言处理的模型在 GLUE 和 SuperGLUE 基准测试中,他们达到sota性能是通过对原始文本进行大规模的预训练而不使用人工标签。
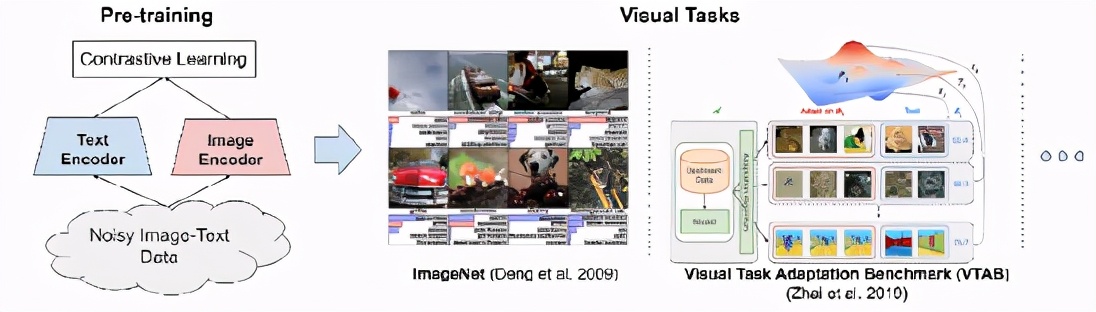
在 ICML 2021会议上,Google Research发表了Scaling up visual and vision-language representation learning with noisy text supervision一文,建议利用公开的图像替代文本数据(如果图像未能在用户屏幕上显示,则在网页上显示替代图像的书面文本)来弥补这一差距,以训练更大、最先进的视觉和视觉-语言模型。

为了达到这个目的,我们利用了一个超过10亿个图像和文本对的噪声数据集,在概念标题数据集中没有昂贵的过滤或后处理步骤就获得了这个数据集。实验结果表明,我们的语料库规模可以弥补噪声数据的不足,从而实现了 SotA 表示,并且在转换到 ImageNet 和 VTAB 等分类任务时表现出了很好的性能。对齐的视觉和语言表示还在 Flickr30K 和 MS-COCO 基准上设置新的 SotA 结果,即使与更复杂的交叉关注模型相比也是如此,并支持零镜头图像分类和复杂文本和文本 + 图像查询的交叉模式搜索。
图文数据集中的 alt-text 通常是关于图像的描述,但数据集可能包括噪音,例如一些描述文本可能部分或全部与其配对图像无关。

例如第二张图中就包括部分与图像无关的描述,如日期、缩略图等等。
Google的研究工作主要遵循构建Conceptual Captions数据集的方法来获得原始的英语描述文本数据,即图像和alt-text的pairs。
虽然Conceptual Captions数据集被大量的过滤和后处理清理过了,但是论文中的工作通过放宽数据清洗的措施来扩大数据集,这种方法来扩展视觉和视觉语言表征学习。
最后获得了一个更大但噪音也更大的数据集,共包含 18亿个 图像-文本对。
ALIGN: A Large-scale ImaGe and Noisy-Text Embedding
为了便于建立更大的模型,模型框架采用了一个简单的双编码器结构用来学习图像和文本对的视觉和语言表示的align表示。
图像和文本编码器是通过对比学习来训练,即归一化的softmax。
这种对比损失将匹配的图像-文本对的embedding尽可能贴近,同时将那些不匹配的图像-文本对(在同一batch中)尽可能分开。
大规模数据集使我们能够训练拥有更多参数的模型,甚至可以从零开始训练和EffecientNet-L2和BERT-large那么大的模型。学到的视觉表征可以用于下游的视觉和视觉语言任务。
所得到的表示可以用于纯视觉或视觉语言任务上的迁移学习,无需任何微调,ALIGN 就能够跨模态搜索图像到文本、文本到图像,甚至联合搜索图像 + 文本的query。

上述例子就展示了ALIGN的这种能力。
Evaluating Retrieval and Representation
评估检索和表示学习的时候, ALIGN 模型与 BERT-Large 和 EfficientNet-L2共同作为文本和图像编码器,能够在多个图像文本检索任务(Flickr30K 和 MS-COCO) ZeroShot任务和微调中都取得了sota性能。
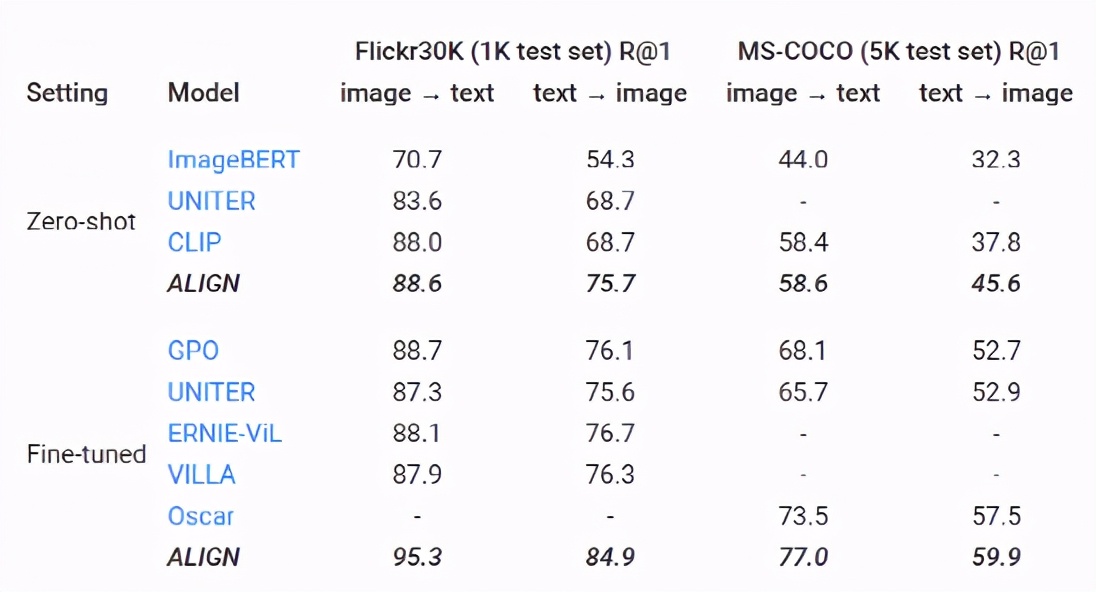
ALIGN 也是一个强大的图像表示模型。在固定住特征以后,ALIGN 略优于 CLIP,并在 ImageNet 上获得85.5% 的 SotA 结果。通过微调,ALIGN 比大多数通用模型(如 BiT 和 ViT)获得了更高的准确性,只比 Meta Pseudo Labels 差,但后者需要 ImageNet 训练和大规模未标记数据之间进行更深入的交互。

在Zero-Shot图像分类上,图像分类问题将每个类别视为独立的 id,人们必须通过每个类别至少拍摄几张标记数据来训练分类层次。但类名实际上也是自然语言短语,因此可以很自然而然地扩展 ALIGN 图像分类的图文检索能力,而不需要任何训练数据。
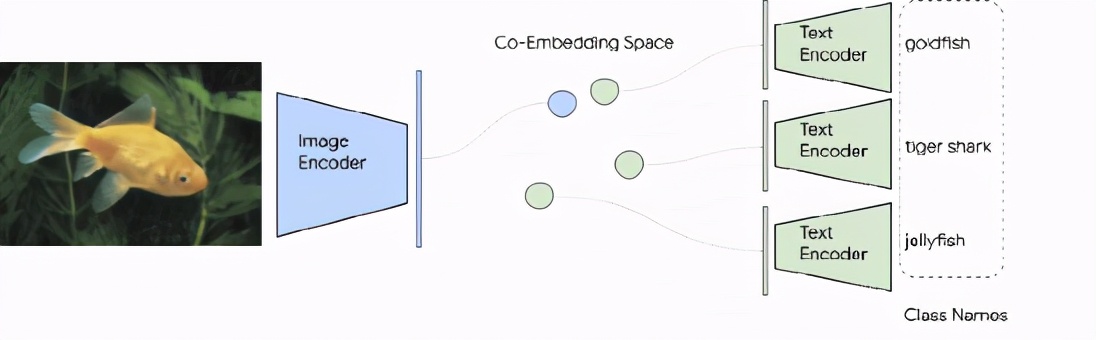
在 ImageNet 验证数据集上,ALIGN 实现了76.4% 的 top-1 Zero-shot 准确率,并且在不同的 ImageNet 变体中表现出很强的鲁棒性,这与同时期的工作 CLIP 很像,都使用了文本提示来训练。

为了能够说明图像检索的实际效果,论文中还构建了一个简单的图像检索系统,该系统使用 ALIGN 训练的embedding,并展示了一亿6000万张图像池中少数文本查询的top1个文本到图像的检索结果。
ALIGN 可以检索给出场景详细描述的精确图像,或者细粒度或实例级的概念,如地标和艺术品。
这些示例表明,ALIGN 模型可以使图像和文本具有相似的语义,并且 ALIGN 可以概括为新的复杂概念。

多模态(图像 + 文本)图像搜索查询单词向量的一个令人惊讶的特性是,单词类比通常可以用向量算法解决。一个常见的例子,“ king-man + woman = queen”。图像和文本嵌入之间的这种线性关系也出现在 ALIGN 中。
具体来说,给定一个查询图像和一个文本字符串,将它们的 ALIGN embedding相加到一起,并使用余弦距离检索相关图像。

这些例子不仅说明了 ALIGN 嵌入跨视觉域和语言域的组合性,而且表明了使用多模态查询进行搜索的可行性。例如,人们现在可以寻找“澳大利亚”或“马达加斯加”大熊猫的等价物,或者把一双黑鞋变成看起来一模一样的米色鞋子。此外,还可以通过在嵌入空间中执行减法来删除场景中的对象/属性。
在社会影响方面,虽然这项工作从方法论的角度来看,以简单的数据收集方法显示了令人满意的结果,但在实践中负责任地使用该模型之前,还需要对数据和由此产生的模型进行进一步分析。例如,应当考虑是否有可能利用备选案文中的有害文本数据来加强这种危害。关于公平性,可能需要努力平衡数据,以防止从网络数据加强定型观念。应该对敏感的宗教或文化物品进行额外的测试和训练,以了解并减轻可能贴错标签的数据带来的影响。
还应该进一步分析,以确保人类的人口分布和相关的文化物品,如衣服、食物和艺术品,不会造成曲解的模型性能。如果这些模型将在生产环境中使用,则需要进行分析和平衡。
综上所述,Google Research提出了一种利用大规模图文数据进行视觉和视觉语言表征学习的简单方法,模型 ALIGN 能够进行跨模态检索,并且明显优于 SotA 模型。在纯视觉的下游任务中,ALIGN 也可以与使用大规模标记数据进行训练的 SotA 模型相比,或者优于 SotA 模型。
本文的一二作者分别是Chao Jia和Yinfei Yang两位华人,而他们分别的研究方向分别为CV和NLP,可见 神经网络让NLP和CV的界限也更加模糊了,万物皆可embedding。