一、背景介绍
根据MarketsandMarkets市场调研显示,预计数据湖市场规模在2024年将从2019年的79亿美金增长到201亿美金。随着数据湖的规模增长,基于交互式查询引擎Presto的数据湖分析负载也随着增加。在共享的Presto集群里,大查询之间非常容易相互影响,在此背景下对查询进行算力隔离也就迫在眉睫。本文主要介绍数据湖分析引擎Presto如何解决多租户算力隔离的技术。
二、数据湖分析 Presto 算力隔离遇到的挑战
1、数据湖分析 Presto 方案架构
Presto是一个定位大数据分析领域的分布式SQL查询引擎,适合GB到PB级别的数据的交互式分析查询。与Hive、Spark等其他查询引擎不同,它是一个全内存计算的MPP引擎,能快速获取查询结果,因此它特别适合进行adhoc查询、数据探索、BI报表、轻量ETL等多种业务场景。下图以阿里云数据湖分析(简称DLA)的Presto架构为例说明。
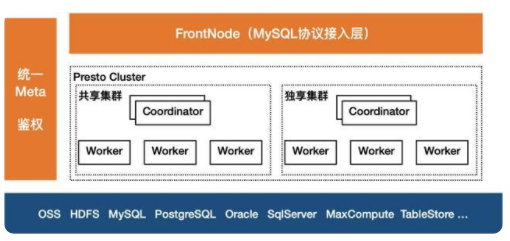
FrontNode:整个架构的接入层FrontNode,它通过MySQL协议提供服务,只要兼容MySQL协议的客户端、BI工具可以直接连接并提交查询,它接收到SQL后,会对SQL做解析,转换为Presto风格的SQL,并调度到相应的Presto集群。Presto引擎:中间的Presto计算引擎,适合交互查询,用户可以根据业务特点,如果是频繁类型的查询,适合选择独享集群;若是偶发类型的查询,适合Serverless类型的共享集群。元数据:左侧是统一元数据,相对Presto原生的元数据,它能统一管理所有Connector的元数据,并支持多租户的权限控制;并提供了MySQL风格的GRANT/REVOKE机制,便于租户内的子账户权限管理。存储层:底层是存储层,Presto并不自带存储,但它支持许多的数据源,并支持不同数据源之间的关联查询。
2、数据湖分析 Presto 算力隔离遇到的挑战
社区原生的Presto在多租户隔离场景考虑的比较少,主要通过ResourceGroup机制限制每个资源组的资源(包括CPU和内存)上限,它最大的问题是只能限制新的查询,即一个Group的资源用超后,其新提交的查询会被排队,直到其使用的资源降到上限之下;对于正在执行的查询如果超过资源组的资源上限,ResourceGroup不会做限制。因此在一个共享的Presto集群中,一个大查询还是可以把整个集群的资源消耗完,从而影响其他用户的查询。在DLA实际生产过程中,上千用户共享的集群,此问题尤为突出。
与Spark、Hive等其他查询引擎可以简单设置执行资源并发限制资源不同,Presto首先需要预先启动所有Stage,并且所有查询在Worker执行时共享线程和内存,因此无法通过简单地设置执行的并发控制其资源的使用。
业界采用比较多的解决方案是:基于Presto On Yarn实现资源隔离。为每个资源组启动一个独立的Presto On Yarn集群,并通过Yarn的资源管理机制实现Presto集群之间的隔离。其优点是资源隔离比较好;但需要预先为每个租户启动一个专属的集群,即使没有查询在执行也需要维护该集群,在数据湖分析Serverless服务场景,租户较多,且他们的查询很多都是间歇性的,其资源消耗也不稳定,无法预估。因此如果为每个用户都启动一个专属集群,会导致严重的资源浪费。
三、基于实时惩罚机制实现DLA Presto的算力隔离技术解析
1、社区Presto的Query执行与调度原理
下面以一个聚合类型的查询为例简要介绍社区Presto的Query(查询)执行原理。
Select id, sum(money) from employ where id>10000 group by id;
注:*左右滑动阅览
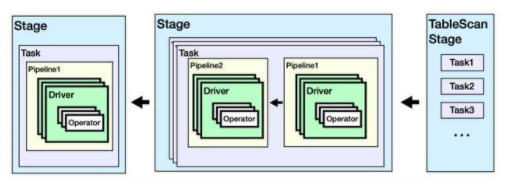
一个查询会被解析为包含多个Stage的物理执行计划,每个Stage包含若干Task,Task会被Coordinator调度到Worker上执行。在Worker上,每个Task会包含多个Driver,每个Driver对应一个Split(数据切片);每个Driver会包含若干操作算子Operator。
它在Presto上的调度逻辑如下图所示,在主节点Coordinator和从节点Worker都有相应的调度逻辑。
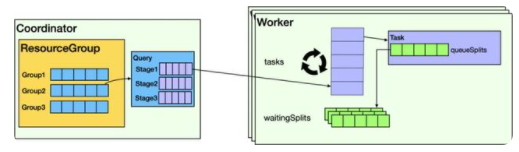
在Coordinator上,主要负责多租户Group之间和Group内的Query调度。若Group使用的资源未达到上限,则Query会被解析并调度。Query解析后,以Task为单位,一次性把所有Stage的Task分配给Worker。
Worker会根据数据切片Split生成Driver,并放到调度队列。Worker执行Split以时间片为单位,一次最多只执行1秒,未完成则继续放入排队队列。
2、基于实时惩罚机制的核心思想
数据切片Split的执行基于CPU时间片可以做进一步的限制:实时统计每个Group消耗的CPU时间,当Group累计每秒消耗的CPU时间超过其配置的资源上限,则开始惩罚该Group,即不再执行其Split,直到其累计CPU消耗小于资源上限。
举例的描述:GroupA的配置可使用的CPU核数上限为N,Coordinator每秒为GroupA生成N秒的CPU时间片,当GroupA的查询执行时,实时统计GroupA的CPU消耗,其每秒的CPU消耗为cpus,累计消耗为Csum,每秒都需要让Csum加上cpus,然后做如下的判断逻辑:
如果 Csum <= N:下一秒不需要惩罚;并重置Csum = 0。如果 Csum >= 2N,需要惩罚1秒,下一秒GroupA的所有Split都不会被调度执行;并设置Csum = Csum - N。如果 N < Csum < 2N,下一秒不会被惩罚,但Csum-N的值会进入下一秒的判断逻辑,下一秒被惩罚的概率会加大;并设置Csum = Csum - N。
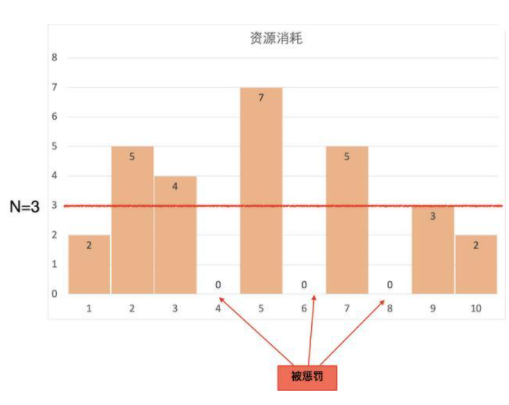
上图以N=3为例举例说明:
第一秒 cpus=2,Csum=2;下一秒不惩罚。第二秒 cpus=5,Csum=5;下一秒不惩罚。第三秒 cpus=4,Csum=6;下一秒惩罚。第四秒 cpus=0,Csum=3;下一秒不惩罚第五秒 cpus=7,Csum=7;下一秒惩罚。第六秒 cpus=0,Csum=4;下一秒不惩罚。第七秒 cpus=5,Csum=6;下一秒惩罚。第八秒 cpus=0,Csum=3;下一秒不惩罚。第九秒 cpus=3,Csum=3;下一秒不惩罚。
3、基于实时惩罚机制实现DLA Presto的算力隔离的实现原理
鉴于DLA的Presto已经实现了Coordinator的高可用,一个集群中包含至少两个Coordinator,因此ResourceManager模块首先需要实时收集所有Coordinator上所有Group的资源消耗信息,并在ResourceManager中汇总,然后计算并判断每个Group是否需要被惩罚,最终把每个Group是否需要被惩罚的信息同步给所有Worker。如下图所示:
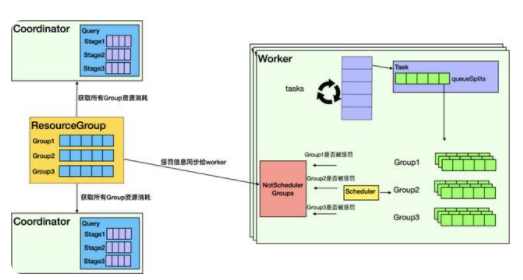
与社区Presto的Worker把所有Split放到一个waitingSplit队列不同,DLA Presto首先在Worker上引入Group概念,每个Group都会维护一个自己的队列。Worker在调度选择Split时,首先会考虑Group是否被惩罚,如果被惩罚,则不会调度该Group的Split;只有未被惩罚的Group的Split会被选中执行。之后Worker会统计所有查询的资源消耗并汇总到Coordinator,并进入到下一个判断周期。最终达到控制Group算力的能力。
四、DLA Presto算力隔离上线效果
接下来以TPCH做测试,验证租户算力隔离效果。测试场景:
四台Worker,每台配置是4C8G;选用TPCH第20条SQL进行实验,因为它包含5个JOIN个,需要使用大量CPU;实验场景:四个租户资源上限相同都为8,其中A、B、C各提交一条SQL,D同时提交5条SQL。
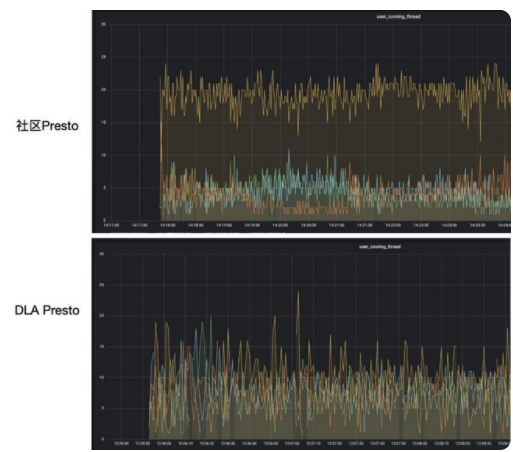
可以看到社区Presto版本由于租户D提交查询多,相应的Split会更多,因此他能分配更多的资源,这对其他用户是不公平的。而在DLA版本中,由于预先为租户D和其他用户配置了相同的资源上限,因此租户D使用的资源和其他用户也是差不多的。
下图是8条查询的耗时对比:
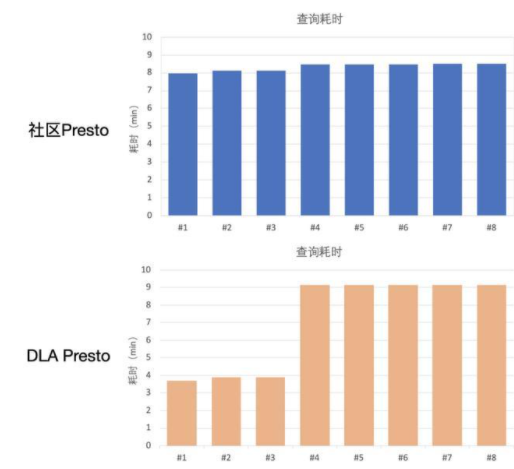
可以看到在开源Presto版本里面,所有8条查询耗时几乎一样;而在DLA的版本里面租户A、B、C的查询耗时较短,而租户D由于使用过多资源被惩罚,因此它的5条查询耗时较长。
在DLA的实际生产过程中,为每个用户设置指定的资源上限,并进行比较精准的控制,杜绝了一条或多条查询占用大量的资源,影响其他用户的查询。也不再出现少量查询就把Presto集群搞垮的情况。保证了用户查询时间的稳定性。另一方面,对于那些查询量很大的用户,DLA还提供了独享集群模式,能让查询以更优的性能完成。
五、总结
随着越来越多的企业开始做数据湖分析,数据量的持续增加,数据分析需求也会越来越多,在一个共享的数据湖分析引擎,如何防止多租户之间的查询相互影响是一个很通用的问题,本文以阿里云DLA Presto为例,介绍了一种基于实时惩罚机制实现算力隔离的原理,能有效使共享Presto集群解决多租户之间查询相互影响的问题。