













本文转载自微信公众号「bigsai」,作者bigsai。转载本文请联系bigsai公众号。
什么是字典树
字典树,是一种空间换时间的数据结构,又称Trie树、前缀树,是一种树形结构(字典树是一种数据结构),典型用于统计、排序、和保存大量字符串。所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
可能大部分情况你很难直观或者有接触的体验,可能对前缀这个玩意没啥概念,可能做题遇到前缀问题也是暴力匹配蒙混过关,如果字符串比较少使用哈希表等结构可能也能蒙混过关,但如果字符串比较长、相同前缀较多那么使用字典树可以大大减少内存的使用和效率。一个字典树的应用场景:在搜索框输入部分单词下面会有一些神关联的搜索内容,你有时候都很神奇是怎么做到的,这其实就是字典树的一个思想。

图片真假可自行验证
对于字典树,有三个重要性质:
1:根节点不包含字符,除了根节点每个节点都只包含一个字符。root节点不含字符这样做的目的是为了能够包括所有字符串。
2:从根节点到某一个节点,路过字符串起来就是该节点对应的字符串。
3:每个节点的子节点字符不同,也就是找到对应单词、字符是唯一的。
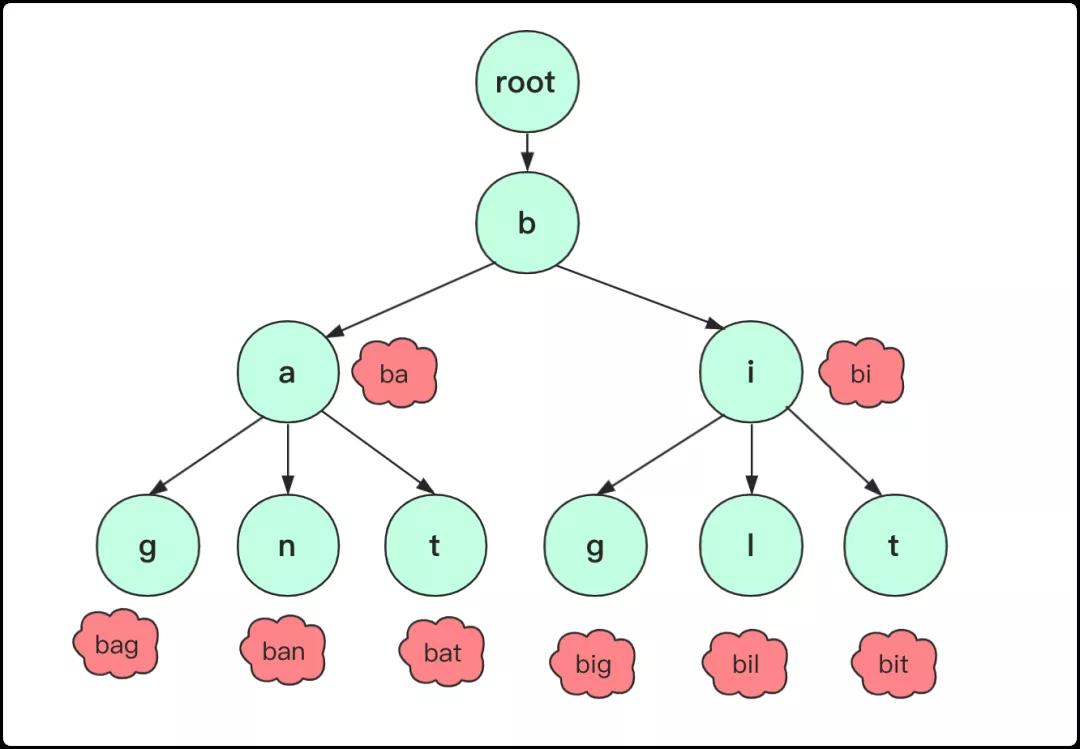
一个字典树
设计实现字典树
上面已经介绍了什么是字典树,那么我们开始设计一个字典树吧!
对于字典树,可能不同的场景或者需求设计上有一些细致的区别,但整体来说一般的字典树有插入、查询(指定字符串)、查询(前缀)。
我们首先来分析一下简单情况吧,就是字符串中全部是26个小写字母,刚好力扣208实现Trie树可以作为一个实现的模板。
实现 Trie 类:
- Trie() 初始化前缀树对象。
- void insert(String word) 向前缀树中插入字符串 word 。
- boolean search(String word) 如果字符串 word 在前缀树中,返回 true(即,在检索之前已经插入);否则,返回 false 。
- boolean startsWith(String prefix) 如果之前已经插入的字符串 word 的前缀之一为 prefix ,返回 true ;否则,返回 false 。
怎么设计这个字典树呢?
对于一个字典树Trie类,肯定是要有一个根节点root的,而这个节点类型TrieNode也有很多设计方式,在这里我们为了简单放一个26个大小的TrieNode类型数组,分别对应'a'-'z'的字符,同时用一个boolean类型变量isEnd表示是否为字符串末尾结束(如果为true说明)。
- class TrieNode {
- TrieNode son[];
- boolean isEnd;//结束标志
- public TrieNode()//初始化
- {
- son=new TrieNode[26];
- }
- }
用数组的话如果字符比较多的话可能会消耗一些内存空间,但是这里26个连续字符还好的,如果向一个字典树中添加big,bit,bz 那么它其实是这样的:
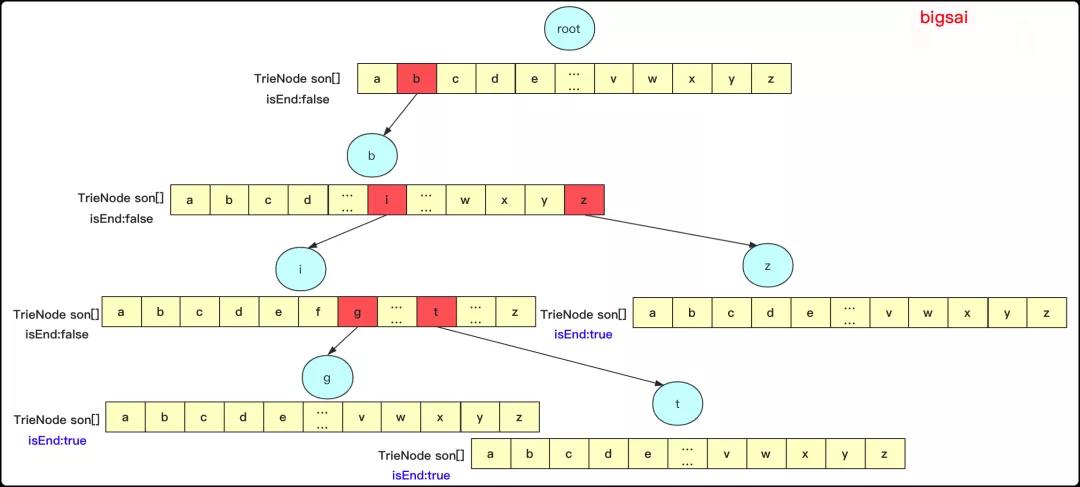
那么再分析一下具体操作:
插入操作:遍历字符串,同时从字典树root节点开始遍历,找到每个字符对应的位置首先判断是否为空,如果为空需要创建一个新的Trie。比如插入big的枚举第一个b时候创建TrieNode,后面也是同理。不过重要的是要在停止的那个TrieNode将isEnd设为true表明这个节点是构成字符串的末尾节点。
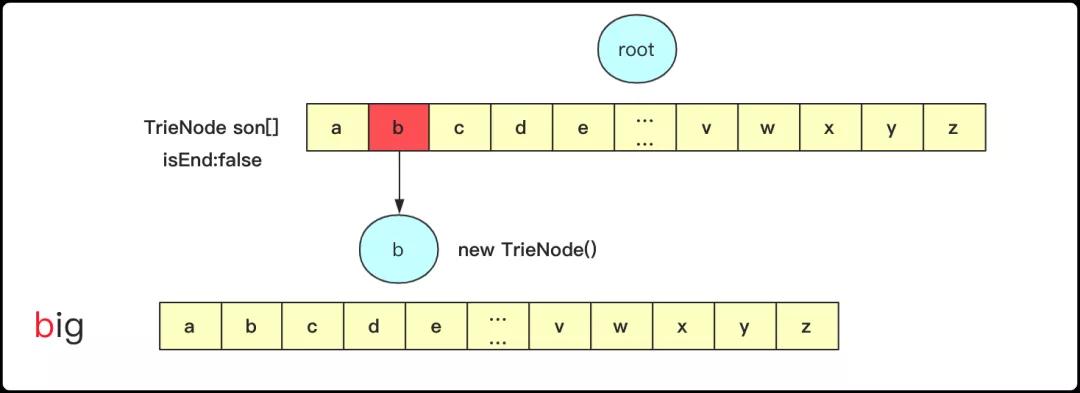
这部分对应的关键代码为:
- TrieNode root;
- /** 初始化 */
- public Trie() {
- root=new TrieNode();
- }
- /** Inserts a word into the trie. */
- public void insert(String word) {
- TrieNode node=root;//临时节点用来枚举
- for(int i=0;i<word.length();i++)//枚举字符串
- {
- int index=word.charAt(i)-'a';//找到26个对应位置
- if(node.son[index]==null)//如果为空需要创建
- {
- node.son[index]=new TrieNode();
- }
- node=node.son[index];
- }
- node.isEnd=true;//最后一个节点
- }
查询操作:查询是建立在字典树已经建好的情况下,这个过程和查询有些类似但不需要创建TrieNode,如果枚举的过程一旦发现该TrieNode未被初始化(即为空)则返回false,如果顺利到最后看看该节点的isEnd是否为true(是否已插入已改字符结尾的字符串),如果为true则返回true。
这里用一个例子可能更好懂。插入big串,如果查找ba会因为第二次a对应TrieNode为null为为空。如果查找bi也会返回失败,因为之前插入的big只在g字符对应TrieNode标识isEnd=true,但i字符下面的isEnd为false,即不存在bi字符串。
该部分对应的核心代码为:
- public boolean search(String word) {
- TrieNode node=root;
- for(int i=0;i<word.length();i++)
- {
- int index=word.charAt(i)-'a';
- if(node.son[index]==null)//为null直接返回false
- {
- return false;
- }
- node=node.son[index];
- }
- return node.isEnd==true;
- }
前缀查找:和查询很相似但是有点区别,查找失败的话返回false,但是如果能进行到最后一步那么返回true。上面例子插入big查找bi同样返回true,因为存在以它为前缀的字符串。
该对应对应的核心代码为:
- public boolean startsWith(String prefix) {
- TrieNode node=root;
- for(int i=0;i<prefix.length();i++)
- {
- int index=prefix.charAt(i)-'a';
- if(node.son[index]==null)
- {
- return false;
- }
- node=node.son[index];
- }
- //能执行到最后即返回true
- return true;
- }
上面代码合在一起就是完整的字典树了,最基础的版本。完整版为:
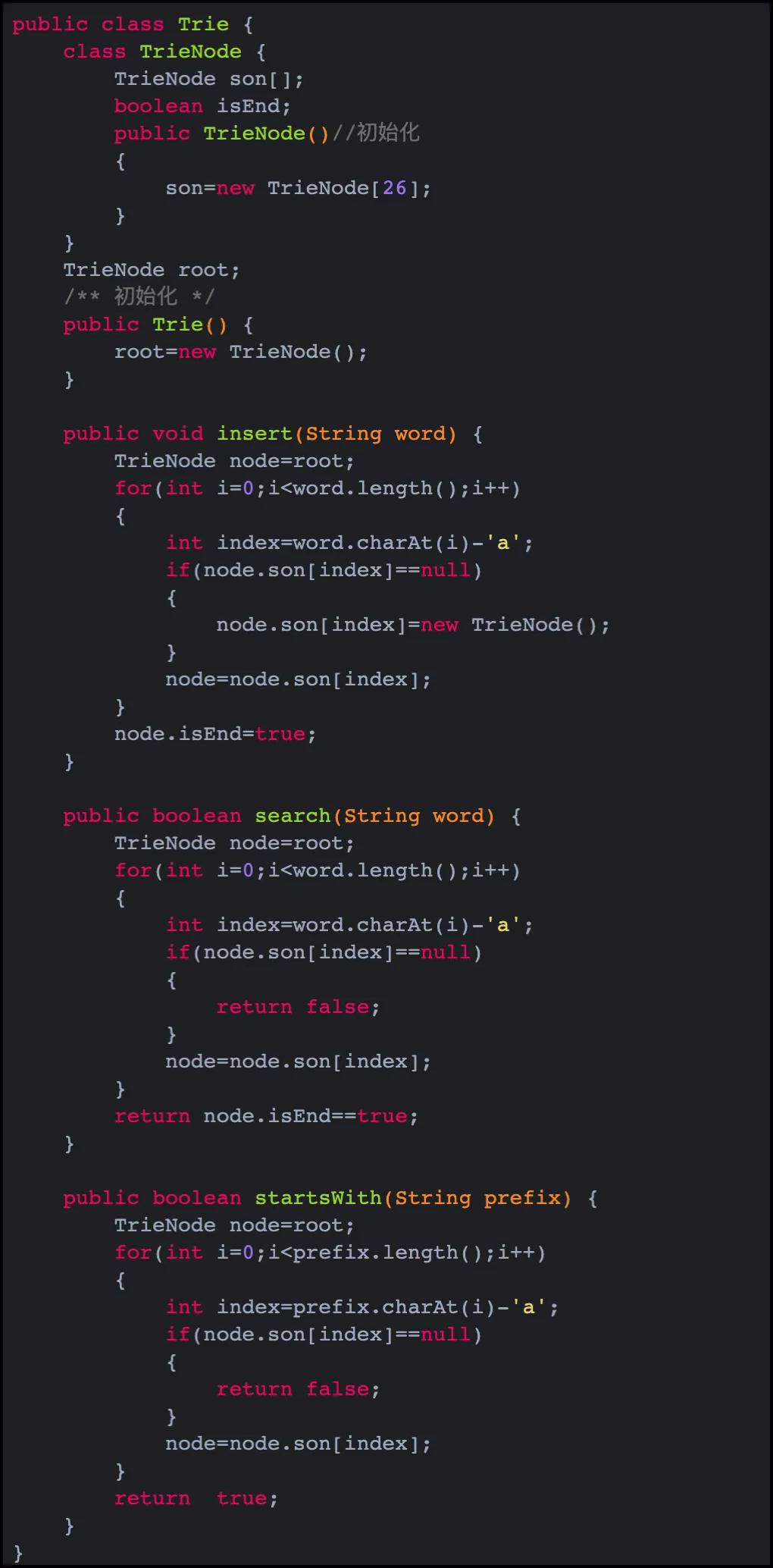
代码
字典树小思考
字典树基础班很容易,但很可能会出现一些延伸。
对于上面是26个字符的,我们很容易用ASCII找到对应索引,如果字符可能性比较多,用数组可能浪费的空间比较大,那我们也可以用HashMap或者List来存储元素啊,用List的话就需要顺序枚举,用HashMap就可以直接查询,这里就讲解一个使用HashMap()实现的字典树。
使用HashMap替代数组(不过使用哈希就不自带排序功能了),其实逻辑是一样的,只需要判断时候用HashMap判断是否存在对应的key即可,HashMap的类型为:
Map
使用HashMap实现的字典树完整代码为:
- import java.util.HashMap;
- import java.util.Map;
- public class Trie{
- class TrieNode{
- Map<Character,TrieNode> sonMap;
- boolean idEnd;
- public TrieNode()
- {
- sonMap=new HashMap<>();
- }
- }
- TrieNode root;
- public Trie()
- {
- root=new TrieNode();
- }
- public void insert(String word) {
- TrieNode node=root;
- for(int i=0;i<word.length();i++)
- {
- char ch=word.charAt(i);
- if(!node.sonMap.containsKey(ch))//不存在插入
- {
- node.sonMap.put(ch,new TrieNode());
- }
- node=node.sonMap.get(ch);
- }
- node.idEnd=true;
- }
- public boolean search(String word) {
- TrieNode node=root;
- for(int i=0;i<word.length();i++)
- {
- char ch=word.charAt(i);
- if(!node.sonMap.containsKey(ch))
- {
- return false;
- }
- node=node.sonMap.get(ch);
- }
- return node.idEnd==true;//必须标记为true证明有该字符串
- }
- public boolean startsWith(String prefix) {
- TrieNode node=root;
- for(int i=0;i<prefix.length();i++)
- {
- char ch=prefix.charAt(i);
- if(!node.sonMap.containsKey(ch))
- {
- return false;
- }
- node=node.sonMap.get(ch);
- }
- return true;//执行到最后一步即可
- }
- }
前面讲了,字典树用于大量字符的统计、排序、储存,其实排序就是和采用数组的方式可以进行排序,因为字符的ASCII有序,在读取时候可以按照这个规则读取,这个思想就和基数排序有点像了。
而统计的话可能会面临数量上统计,可能是出现过次数或者前缀单词数量统计,如果每次都枚举可能有点浪费时间,但你可以TrieNode中添加一个变量,每次插入的时候可以统计次数。如果字符串有重复那可以直接添加,如果字符串要去重那可以确定插入成功再给路径上前缀单词总数分别自增。这个的话就要具体问题具体分析了。
此外,字典树还有一个在ACM中用于解决求异或最值的问题,我们称之为:01字典树,大家感兴趣也可以自行了解(后面可能会介绍)。
总结
通过本文,想必你对字典树有了一个较好的认识,本篇的话目的还是在于让读者能够认识和学会基础的字典树,对其它变形优化能有个初步的认识。
字典树可以最大限度地减少无谓的字符串比较,用于词频统计和大量字符串排序。自带排序功能,使用中序遍历序列即可得到排序序列。但是如果字符很多相同前缀很少的话那字典树就没啥效率优势的(因为要一个一个访问节点)。
字典树的真实应用有很多,例如字符串检索、文本预测、自动完成,see also,拼写检查、词频统计、排序、字符串最长公共前缀、字符串搜索的前缀匹配、作为其他数据结构和算法的辅助结构等等,这里就不再介绍啦。














