












一周前,我们介绍了《面对大规模 K8s 集群,如何先于用户发现问题》。
本篇文章,我们将继续为大家介绍 ASI SRE(ASI,Alibaba Serverless infrastructure,阿里巴巴针对云原生应用设计的统一基础设施) 是如何探索在 Kubernetes 体系下,建设 ASI 自身基础设施在大规模集群场景下的变更灰度能力的。
我们面临着什么
ASI 诞生于阿里巴巴集团全面上云之际,承载着集团大量基础设施全面云原生化的同时,自身的架构、形态也在不断地演进。
ASI 整体上主要采用 Kube-on-Kube 的架构,底层维护了一个核心的 Kubernetes 元集群,并在该集群部署各个租户集群的 master 管控组件:apiserver、controller-manager、scheduler,以及 etcd。而在每个业务集群中,则部署着各类 controller、webhook 等 addon 组件,共同支撑 ASI 的各项能力。而在数据面组件层面,部分 ASI 组件以 DaemonSet 的形式部署在节点上,也有另一部分采用 RPM 包的部署形式。
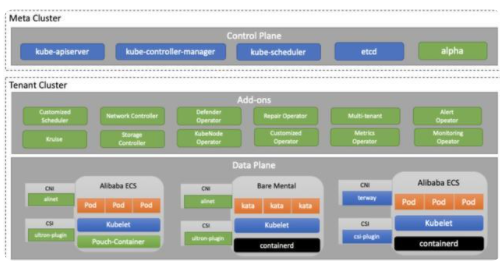
同时,ASI 承载了集团、售卖区场景下数百个集群,几十万的节点。即便在 ASI 建设初期,其管辖的节点也达到了数万的级别。在 ASI 自身架构快速发展的过程中,组件及线上变更相当频繁,早期时单日 ASI 的组件变更可以达到数百次。而 ASI 的核心基础组件诸如 CNI 插件、CSI 插件、etcd、Pouch 等,无论任意之一的错误变更都可能会引起整个集群级别的故障,造成上层业务不可挽回的损失。

简而言之,集群规模大、组件数量多,变更频繁以及业务形态复杂是在 ASI,或其他 Kubernetes 基础设施层建设灰度能力和变更系统的几大严峻挑战。当时在阿里巴巴内部,ASI/Sigma 已有数套现有的变更系统,但都存在一定的局限性。
天基:具备通用的节点发布的能力,但不包括集群、节点集等 ASI 的元数据信息。UCP:早期 sigma 2.0 的发布平台,年久失修。sigma-deploy:sigma 3.x 的发布平台,以镜像 patch 的形式更新 deployment/daemonset。asi-deploy:早期 ASI 的发布平台,管理了 ASI 自身的组件,仅支持镜像 patch,只针对 Aone 的 CI/CD 流水线做适配,以及支持在多个不同环境间灰度,但灰度粒度较粗。
由此,我们希望借鉴前面几代 sigma/ASI 的发布平台历史,从变更时入手,以系统能力为主,再辅以流程规范,逐步构建 ASI 体系下的灰度体系,建设 Kubernetes 技术栈下的运维变更平台,保障数以千计的大规模集群的稳定性。
预设和思路
ASI 自身架构和形态的发展会极大地影响其自身的灰度体系建设方式,因此在 ASI 发展的早期,我们对 ASI 未来的形态做了如下大胆的预设:
以 ACK 为底座:ACK(阿里云容器服务)提供了云的各种能力,ASI 将基于复用这些云的能力,同时将阿里巴巴集团内积累的先进经验反哺云。集群规模大:为提高集群资源利用率,ASI 将会以大集群的方式存在,单个集群提供公共资源池来承载多个二方租户。集群数量多:ASI 不仅按 Region 维度进行集群划分,还会按照业务方等维度划分独立的集群。Addon 数量多:Kubernetes 体系是一个开放架构,会衍生出非常多 operator,而这些 operator 会和 ASI 核心组件一起共同对外提供各种能力。变更场景复杂:ASI 的组件变更场景将不止镜像发布形式,Kubernetes 声明式的对象生命周期管理注定了变更场景的复杂性。
基于以上几个假设,我们能够总结在 ASI 建设初期,亟待解决的几个问题:
如何在单个大规模集群中建设变更的灰度能力?如何在多个集群间建立规模化的变更灰度能力?在组件数量、种类众多的情况下,如何保证进行组件管理并保证组件每次的发布不会影响线上环境?

我们转换一下视角,脱离集群的维度,尝试从组件的角度来解决变更的复杂性。对于每个组件,它的生命周期可以大体划分为需求和设计阶段,研发阶段和发布阶段。对于每个阶段我们都希望进行规范化,并解决 Kubernetes 本身的特点,将固定的规范落到系统中,以系统能力去保证灰度过程。
结合 ASI 的形态和变更场景的特殊性,我们从以下几点思路出发去系统化建设 ASI 的灰度体系:
需求和设计阶段方案 TechReview组件上线变更会审组件研发阶段标准化组件研发流程组件发布变更阶段提供组件工作台能力进行组件的规模化管理建设 ASI 元数据,细化灰度单元建设 ASI 单集群、跨集群的灰度能力
灰度体系建设
1. 研发流程标准化
ASI 核心组件的研发流程可以总结为以下几个流程:
针对 ASI 自身的核心组件,我们与质量技术团队的同学共同建设了 ASI 组件的 e2e 测试流程。除了组件自身的单元测试、集成测试外,我们单独搭建了单独的 e2e 集群,用作常态化进行的 ASI 整体的功能性验证和 e2e 测试。
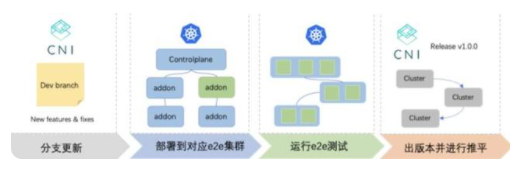
从单个组件视角入手,每个组件的新功能经过研发后,进行 Code Review 通过并合入 develop 分支,则立即触发进行 e2e 流程,通过 chorus(云原生测试平台) 系统构建镜像后,由 ASIOps(ASI 运维管控平台) 部署到对应的 e2e 集群,执行标准的 Kubernetes Conformance 套件测试任务,验证 Kubernetes 范围内的功能是否正常。仅当所有测试 case 通过,该组件的版本才可标记为可推平版本,否则后续的发布将会受到管控限制。
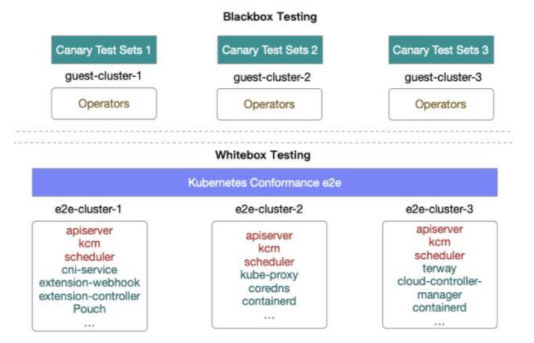
然而正如上文提到,Kubernetes 开放的架构意味着它不仅仅包含管控、调度等核心组件,集群的功能还很大程度依赖于上层的 operator 来共同实现。因此 Kubernetes 范围内的白盒测试并不能覆盖所有的 ASI 的适用场景。底层组件功能的改变很有大程度会影响到上层 operator 的使用,因此我们在白盒 Conformance 的基础上增加了黑盒测试用例,它包含对各类 operator 自身的功能验证,例如从上层 paas 发起的扩缩容,校验发布链路的 quota 验证等能力,常态化运行在集群中。
2. 组件规模化管理
针对 ASI 组件多、集群多的特点,我们在原有 asi-deploy 功能之上进行拓展,以组件为切入点,增强组件在多集群间的管理能力,从镜像管理演进成了YAML 管理。
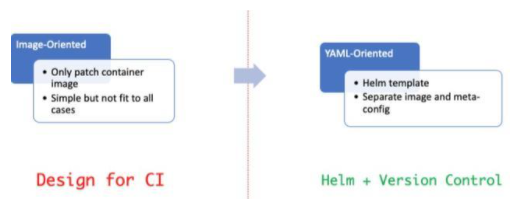
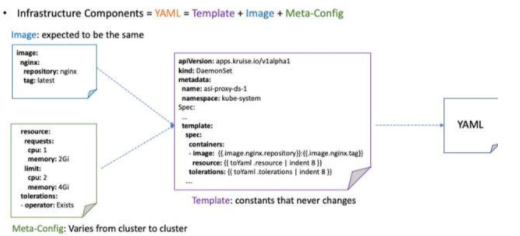
基于 Helm Template 的能力,我们将一个组件的 YAML 抽离成模板、镜像和配置三部分,分别表示以下几部分信息:
模板:YAML 中在所有环境固定不变的信息,例如 apiVersion,kind 等;镜像:YAML 中与组件镜像相关的信息,期望在单一环境或者所有集群中保持一致的信息;配置:YAML 中与单环境、单集群绑定的信息,允许存在多样化的内容,不同集群中的配置可能不同;
因此,一个完整的 YAML 则由模板、镜像和配置共同渲染而成。而 ASIOps 则再会对镜像信息和配置信息这部分 YAML 分别进行集群维度和时间维度(多版本)进行管理,计算组件当前版本信息在众多集群众多分布状况以及组件在单集群中版本的一致性状况。
针对镜像版本,我们从系统上促使其版本统一,以保证不会因版本过低而导致线上问题;而针对配置版本,我们则从管理上简化它的复杂性,防止配置错误发入集群。
有了组件的基础原型后,我们希望发布不仅仅是“替换 workload 里的 image 字段”这样简单的一件事。我们当前维护了整个 YAML 信息,包含了除了镜像之外的其他配置内容,需要支持除了镜像变动外的变更内容。因此我们尝试以尽可能接近 kubectl apply 的方式去进行 YAML 下发。
我们会记录三部分的 YAML Specification 信息:
Cluster Spec:当前集群中指定资源的状况;Target Spec:现在要发布进集群的 YAML 信息;DB Spec:上一次部署成功的 YAML 信息,与 kubectl apply 保存在 annotation 中的 last-applied-configuration 功能相同。
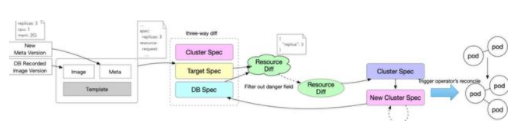
对于一个由镜像、配置和模板共同构建的 YAML,我们会采集上述三种 Spec 信息,并进行一次 diff,从而获得到资源 diff patch,再进行一次 filter out,筛去不允许变更的危险的字段,最后将整体的 patch 以 strategic merge patch 或者 merge patch 的形式发送给 APIServer,触发使得 workload 重新进入 reconcile 过程,以改变集群中该 workload 的实际状况。
除此之外,由于 ASI 组件之间具有较强的相关性,存在许多场景需要同时一次性发布多个组件。例如当我们初始化一个集群,或者对集群做一次整体的 release 时。因此我们在单个组件部署的基础上增加了 Addon Release 的概念,以组件的集合来表明整个 ASI 的 release 版本,并且根据每个组件的依赖关系自动生成部署流,保证整体发布的过程中不会出现循环依赖。
3. 单集群灰度能力建设
在云原生的环境下,我们以终态的形式去描述应用的部署形态,而 Kubernetes 提供了维护各类 Workload 终态的能力,Operator 对比 workload 当前状态与终态的差距并进行状态协调。这个协调的过程,换言之 workload 发布或者回滚的过程,可以由 Operator 定义的发布策略来处理这个“面向终态场景内的面向过程的流程”。
相比 Kubernetes 上层的应用负载,底层的基础设施组件在发布的过程中更关心组件自身的灰度发布策略和灰度暂停能力,_即不论任何类型的组件,都需要能在发布过程中具备及时停止发布的能力,以提供更多的时间进行功能检测、决策以及回滚_。具体而言,这些能力可以归纳为如下几类:
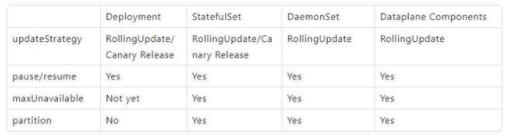
updateStrategy:流式升级/滚动升级pause/resume:暂停/恢复能力maxUnavailable:不可用副本数到达一定时能够快速停止升级partition:升级暂停能力,单次仅升级固定数量副本数,保留一定数量的老版本副本
ASI 中针对 Kubernetes 原生 workload 能力、节点能力都进行了增强。依托于集群中 Kruise 和 KubeNode 这类 operator 的能力以及上层管控平台 ASIOps 的共同协作,我们对 Kubernetes 基础设施组件实现了上述灰度能力的支持。对于 Deployment / StatefulSet / DaemonSet / Dataplane 类型的组件,在单集群中发布时支持的能力如下:
后文将简要介绍我们针对不同 Workload 类型的组件进行灰度的实现,详细的实现细节可以关注我们开源的项目 OpenKruise 以及后续准备开源的 KubeNode。
1)Operator Platform
大多数 Kubernetes 的 operator 以 Deployment 或者 StatefulSet 的方式部署,在 Operator 发布的过程中,一旦镜像字段变动,所有 Operator 副本均会被升级。这个过程一旦新版本存在问题,则会造成不可挽回的问题。
针对此类 operator,我们将 controller-runtime 从 operator 中剥离出来,构建一个中心化的组件 operator-manager(OpenKruise 开源实现中为 controller-mesh)。同时每个 operator pod 中会增加一个 operator-runtime 的 sidecar 容器,通过 gRPC 接口为组件的主容器提供 operator 的核心能力。
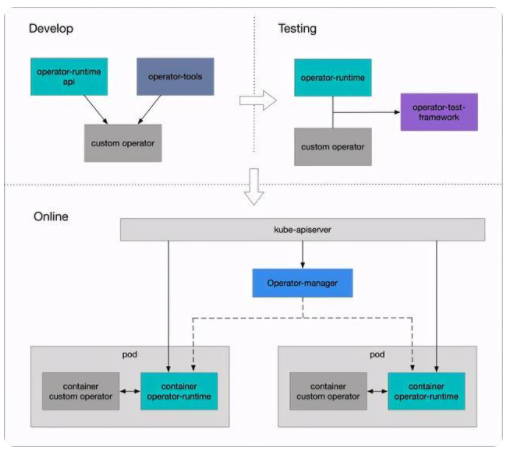
operator 向 APIServer 建立 Watch 连接后,监听到事件并被转化为待 operator 协调处理的任务流(即 operator 的流量),operator-manager 负责中心化管控所有 operator 的流量,并根据规则进行流量分片,分发到不同的 operator-runtime,runtime 中的 workerqueue 再触发实际 operator 的协调任务。
在灰度过程中,operator-manager 支持按照 namespace 级别,哈希分片方式,将 operator 的流量分摊给新旧版本的两个副本,从而可以从两个副本处理的负载 workload 来验证这次灰度发布是否存在问题。
2)Advanced DaemonSet
社区原生的 DaemonSet 支持了 RollingUpdate,但是其滚动升级的能力上仅支持 maxUnavailable 一种,这对于单集群数千上万节点的 ASI 而言是无法接受的,一旦更新镜像后所有 DaemonSet Pod 将会被升级,并且无法暂停,仅能通过 maxUnavailable 策略进行保护。一旦 DaemonSet 发布了一个 Bug 版本,并且进程能够正常启动,那么 maxUnavailable 也无法生效。
此外社区提供 onDelete 方式,可以在手动删除 Pod 创建新 Pod,由发布平台中心端控制发布顺序和灰度,这种模式无法做到单集群中的自闭环,所有的压力都上升到发布平台上。让上层发布平台来进行Pod驱逐,风险比较大。最好的方式就是 Workload 能自闭环提供组件更新的能力。因此我们在 Kruise 中加强了 DaemonSet 的能力使其支持上述几种重要的灰度能力。
如下是一个基本的 Kruise Advanced DaemonSet 的例子:
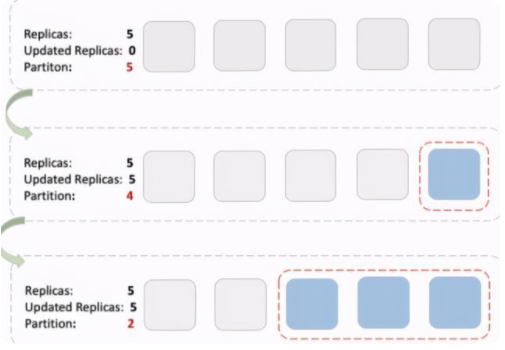
apiVersion: apps.kruise.io/v1alpha1kind: DaemonSetspec: # ... updateStrategy: type: RollingUpdate rollingUpdate: maxUnavailable: 5 partition: 100 paused: false
其中 partition 意为保留老版本镜像的 Pod 副本数,滚升级过程中一旦指定副本数 Pod 升级完成,将不再对新的 Pod 进行镜像升级。我们在上层 ASIOps 中控制 partition 的数值来滚动升级 DaemonSet,并配合其他 UpdateStrategy 参数来保证灰度进度,同时在新创建的 Pod 上进行一些定向验证。
3)MachineComponentSet
MachineComponentSet 是 KubeNode 体系内的 Workload,ASI 中在 Kubernetes 之外的节点组件(无法用 Kubernetes 自身的 Workload 发布的组件),例如 Pouch,Containerd,Kubelet 等均是通过该 Workload 进行发布。
节点组件以 Kubernetes 内部的自定义资源 MachineComponent 进行表示,包含一个指定版本的节点组件(例如 pouch-1.0.0.81)的安装脚本,安装环境变量等信息;而 MachineComponentSet 则是节点组件与节点集合的映射,表明该批机器需要安装该版本的节点组件。而中心端的 Machine-Operator 则会去协调这个映射关系,以终态的形式,比对节点上的组件版本以及目标版本的差异,并尝试去安装指定版本的节点组件。
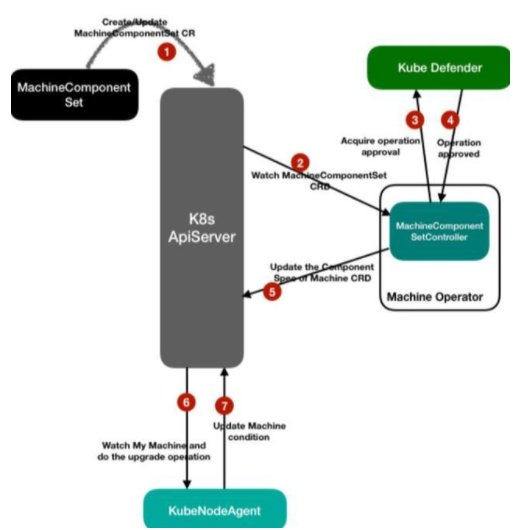
在灰度发布这一部分,MachineComponentSet 的设计与 Advanced DaemonSet 类似,提供了包括 partition,maxUnavailable 的 RollingUpdate 特性,例如以下是一个 MachineComponentSet 的示例:
apiVersion: kubenode.alibabacloud.com/v1kind: MachineComponentSetmetadata: labels: alibabacloud.com/akubelet-component-version: 1.18.6.238-20201116190105-cluster-202011241059-d380368.conf component: akubelet name: akubelet-machine-component-setspec: componentName: akubelet selector: {} updateStrategy: maxUnavailable: 20% partition: 55 pause: false
同样上层 ASIOps 在控制灰度升级节点组件时,与集群侧的 Machine-Operator 进行交互,修改指定 MachineComponentSet 的 partition 等字段进行滚动升级。
相比于传统的节点组件发布模式,KubeNode 体系将节点组件的生命周期也闭环至 Kubernetes 集群内,并将灰度发布的控制下沉到集群侧,减少中心侧对节点元数据管理的压力。
4. 跨集群灰度能力建设
阿里巴巴内部针对云产品、基础产品制定了变更红线 3.0,对管控面组件、数据面组件的变更操作的分批灰度、控制间隔、可观测、可暂停、可回滚进行了要求。但变更对象以 region 的单元进行灰度不满足 ASI 的复杂场景,因此我们尝试去细化 ASI 上管控面、数据面的变更所属的变更单元的类型。
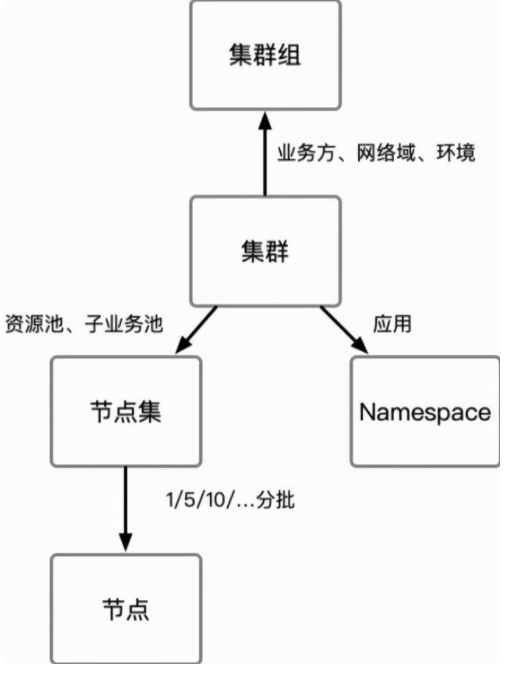
我们围绕集群这一基础单元向上,向下分别进行抽象,得到以下几个基本单元:
集群组:具有共同业务方(ASI 承接的二方用户)、网络域(售卖区/OXS/集团)、环境(e2e/测试/预发/金丝雀/小流量/生产)信息,因此在监控、告警、巡检、发布等方面的配置具有共同性。集群:ASI 集群概念,对应一个 Kubernetes 集群预案。节点集:一组具有共同特征的节点集合,包括资源池、子业务池等信息。Namespace:单个集群中的单个 Namespace,通常 ASI 中一个上层业务对应一个 Namespace。节点:单台宿主机节点,对应一个 Kubernetes Node。
针对每种发布模式(管控组件、节点组件),我们以最小爆炸半径为原则,将他们所对应的灰度单元编排串联在一起,以使得灰度流程能够固化到系统中,组件开发在发布中必须遵守流程,逐个单元进行部署。编排过程中,我们主要考虑以下几个因素:
业务属性环境(测试、预发、小流量、生产)网络域(集团 V、售卖区、OXS)集群规模(Pod/Node 数)用户属性(承载用户的 GC 等级)单元/中心组件特性
同时我们对每个单元进行权重打分,并对单元间的依赖关系进行编排。例如以下是一条 ASI 监控组件的发布流水线,由于该监控组件在所有 ASI 场景都会使用同一套方案,它将推平至所有 ASI 集群。并且在推平过程中,它首先会经过泛电商交易集群的验证,再进行集团 VPC 内二方的发布,最后进行售卖区集群的发布。而在每个集群中,该组件则会按照上一节中我们讨论的单集群内的灰度方式进行 1/5/10 批次的分批,逐批进行发布。
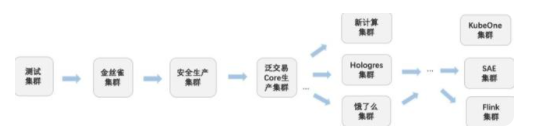
进行了灰度单元编排之后,我们则可以获得到一次组件推平流水线的基础骨架。而对于骨架上的每个灰度单元,我们尝试去丰富它的前置检查和后置校验,从而能够在每次发布后确认灰度的成功性,并进行有效的变更阻断。同时对于单个批次我们设置一定的静默期去使得后置校验能够有足够的时间运行完,并且提供给组件开发足够的时间进行验证。目前单批次前置后置校验内容包括:
全局风险规则(封网、熔断等)发布时间窗口(ASI 试行周末禁止发布的规则)KubeProbe 集群黑盒探测金丝雀任务(由诺曼底发起的 ASI 全链路的扩缩容任务)核心监控指标大盘组件日志(组件 panic 告警等)主动诊断任务(主动查询对应的监控信息是否在发布过程中有大幅变化)
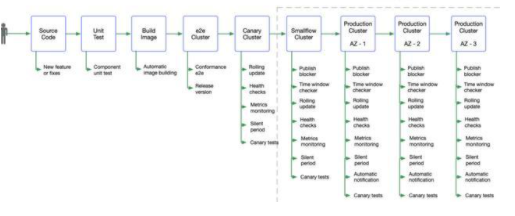
将整个多集群发布的流程串联在一起,我们可以得到一个组件从研发,测试至上线发布,整个流程经历的事件如下图:
在流水线编排的实现方面,我们对社区已有的 tekton 和 argo 进行了选型调研,但考虑到我们在发布流程中较多的逻辑不适合单独放在容器中执行,同时我们在发布过程中的需求不仅仅是 CI/CD,以及在设计初期这两个项目在社区中并不稳定。因而我们参考了 tekton 的基础设计(task / taskrun / pipeline / pipelinerun)进行了实现,并且保持着和社区共同的设计方向,在未来会调整与社区更接近,更云原生的方式。
成果
经过近一年半的建设,ASIOps 目前承载了近百个管控集群,近千个业务集群(包括 ASI 集群、Virtual Cluster 多租虚拟集群,Sigma 2.0 虚拟集群等),400 多个组件(包括 ASI 核心组件、二方组件等)。同时 ASIOps 上包含了近 30 余条推平流水线,适用于 ASI 自身以及 ASI 承载的业务方的不同发布场景。
同时每天有近 400 次的组件变更(包括镜像变更和配置变更),通过流水线推平的此时达 7900+。同时为了提高发布效率,我们在前后置检查完善的条件下开启了单集群内自动灰度的能力,目前该能力被大多数 ASI 数据面的组件所使用。
如下是一个组件通过 ASIOps 进行版本推平的示例:
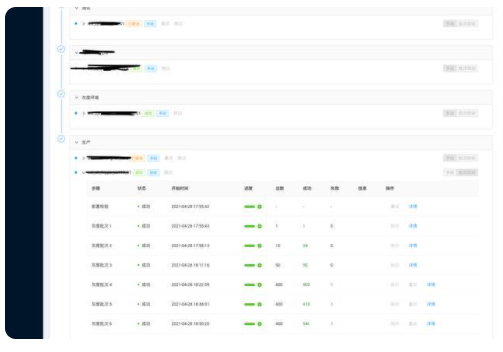
同时我们在 ASIOps 上的分批灰度以及后置检查变更阻断,也帮助我们拦住了一定由于组件变更引起的故障。例如 Pouch 组件在进行灰度时,由于版本不兼容导致了集群不可用,通过发布后触发的后置巡检发现了这一现象,并阻断了灰度进程。
ASIOps 上的组件大多数都是 ASI/Kubernetes 底层的基础设施组件,近一年半以来没有因为由组件变更所引起的故障。我们努力将指定的规范通过系统能力固化下来,以减少和杜绝违反变更红线的变更,从而将故障的发生逐步右移,从变更引发的低级故障逐步转变至代码 Bug 自身引起的复杂故障。
展望
随着 ASI 的覆盖的场景逐步扩大,ASIOps 作为其中的管控平台需要迎接更复杂的场景,规模更大的集群数、组件数的挑战。
首先我们亟待解决稳定性和效率这一权衡问题,当 ASIOps 纳管的集群数量到达一定量级后,进行一次组件推平的耗时将相当大。我们希望在建设了足够的前后置校验能力后,提供变更全托管的能力,由平台自动进行发布范围内的组件推平,并执行有效的变更阻断,在 Kubernetes 基础设施这一层真正做到 CI/CD 自动化。
同时目前我们需要手动对灰度单元进行编排,确定灰度顺序,在未来我们希望建设完全整个 ASI 的元数据,并自动对每次发布范围内的所有单元进行过滤、打分和编排。
最后,目前 ASIOps 暂时只做到针对组件相关的变更进行灰度的能力,而 ASI 范围内的变更远不止组件这一点。灰度体系应该是一个通用的范畴,灰度流水线需要被赋能到注入资源运维、预案执行的其他的场景中。此外,整个管控平台的灰度能力没有与阿里巴巴有任何紧耦合,完全基于 Kruise / KubeNode 等 Workload 进行打造,未来我们会探索开源整套能力输出到社区中。























