本文内容预览:
1. 项目背景介绍
1.1 涉及的表结构
1.2 明确查询诉求
2. 索引问题确认和调优
2.1 问题发现
2.2 问题验证
2.3 索引优化
3. 总结
Part1项目背景介绍
看过上一篇文章的同学应该还记得在叙述索引原理和实际案例的时候,我们列举了一个阿里分布式事务中主事务表的例子。
巧了,前段时间因为业务需求,我们开发了一个长事务一致性引擎用来应对广告体系中的计费时数据上下游一致性问题,其中也涉及了一个类似这样的表。
然而,最近迭代进行代码走查时发现,索引用的有问题。
0.1涉及的表结构
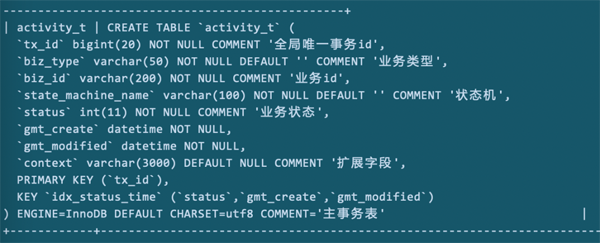
如上图所示,数据库的字段和索引结构是这个样子。
- tx_id全局唯一递增字段为主键。
- status字段标识该条记录的当前状态,用来区分未执行成功的记录
- 创建时间和更新字段,用来辅助异步恢复时按时间衰减序列捞取执行。
各字段具体的起作用方式,有兴趣可以浏览之前写的《分布式事务从入门到放弃(二)--详述DT引擎一致性原理及设计》一文。
0.2明确查询诉求
该表的作用是捞取那些没有进行到终态的记录,进行异常恢复。
- 为了避开系统正在处理中的记录,因此,将时间限定在1分钟之前。
- 为了尽量高效,将时间范围限定在前10分钟,更久的失败记录交给更低频的定时任务处理。
- 为了实现异步处理失败后的时间衰减,所以使用modify,同时也是为了避免新产生的数据因为老数据处理有问题而导致积压。

诉求其实也比较简单:定时捞取·前1分钟·到·前10分钟·,且,状态属于某些状态的记录,即:
- select * from activity_t
- where
- status in (1,2)
- and gmt_modified>='2021-01-01 xx:xx:10'
- and gmt_modified<'2021-01-01 xx:xx:01'
- order by gmt_create;
Part2索引问题确认和调优
0.3问题发现
- -- 唯一索引和联合索引
- PRIMARY KEY (`tx_id`),
- KEY `idx_status_time` (`status`,`gmt_create`,`gmt_modified`)
当前表的索引有两种:唯一索引tx_id,联合索引status_ctime_mtime。
我们当然希望的是有此索引的存在让之前的查询语句效率变高,乍一看,好像查询条件,排序条件都被联合索引包含了,那实际上,上述的查询语句,配合当前索引,能达到想要的效果吗?
根据我们上一篇文章的索引知识,可以给出结论,这个索引会有用,但不会全起作用。因为在联合索引下,处于后面位置的索引字段起作用的前提,是前置位的字段值相同。
0.4问题验证

Explain工具上场。
key=idx_status_time。key标识的是本次查询实际使用的索引。所以,说明我们的联合索引是起了一定作用的。
key_len=4。key_len标识的使用到的索引字段的长度。对于mysql5.7,status是int型占4个,时间字段是datetime型占5个。而这里len=4,说明只使用了status一个索引字段。
type=range。range说明查询status时已经是一个范围查询。
rows=167。说明为了找到结果,遍历了167。
Extra='Using index condition; Using filesort'。很糟糕的是,排序语句触发了文件排序。
上述结果,可以知道之前的索引设置是不合适的,时间索引没有被使用,而且,在排序的时候,使用了额外文件排序。效率和性能相对而言被影响较大,是需要消除的。
另外理论上,有查询优化器的存在,发现status的区分度不高,可能直接使用了索引里的时间字段,而不使用status。
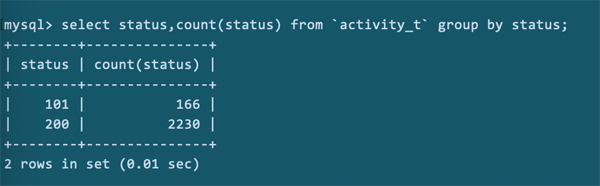
毕竟,这份数据里,只有两个值,且数量级相差也不太多。
那么,按照创建索引的字段需要有足够的区分度这个原则,status字段还有必要放在索引里么?
带着问题我们来一起实际看下。
0.5索引优化
那么,我们应该怎么去调整索引以达到高效查询呢。
调整索引字段顺序
首先,考虑调整的是gmt_modified和gmt_create的顺序。
因为,联合索引下,中间有漏掉索引字段时,后续字段将不起作用。
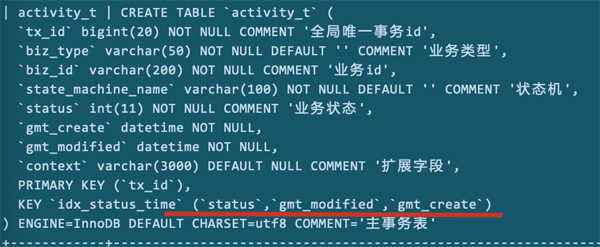
调整两个时间顺序后,再看索引使用情况:

我们看到了变化:
key_len=9。说明使用了gmt_modified索引字段。
rows=2。这个变化说明我们的调整是有效的,查询到数据只进行了2个遍历。相比之前的167要高效很多。
但是,filesort还存在。
status有必要建在索引里么
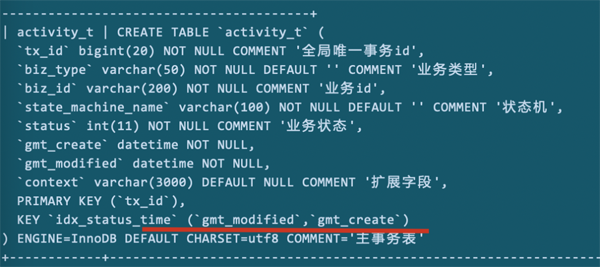
我们把status从索引里删除掉,再来看下explain的结果:

没有了status的索引参与,想要在where条件里过滤,要比之前更加耗性能。所以,status是必要的。
filesort怎么优化掉
排序字段没有使用索引,我们能给其单独创建一个索引么?
答案是不能。
因为sql查询只会使用一个索引,在查询条件使用了索引的情况下,排序就不会再使用索引了。可以实际看下:
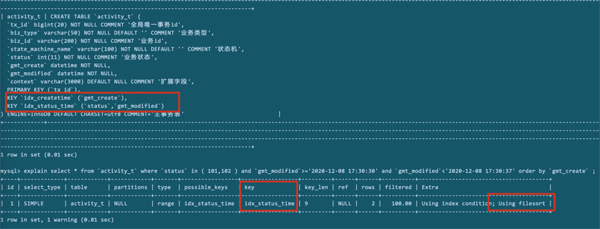
所以,单独给排序字段创建索引是没有用的。怎么办呢?
考虑修改sql,让排序字段使用到索引。
首先我们需要知道,mysql在执行order by的时候,会先查看参与排序的字段在执行计划里是否使用了索引:如果使用了索引,则说明结果是排好序的,否则,进行排序操作。
修改sql如下:
- select * from activity_t
- where
- status in (1,2)
- and gmt_modified>='2021-01-01 xx:xx:10'
- and gmt_modified<'2021-01-01 xx:xx:01'
- order by status,gmt_modified,gmt_create;
将查询条件字段也加到排序字段中,

可以看到,此时的Extra中已经没有filesort了。
当然,排序这个点,可以再考虑下是否真的需要,如果每次处理的异常数据很少,其实,不进行排序也可以。那样就又可以省一些索引空间了。
Part3总结
本文从一条sql查询和数据索引的构建的走查,发现了索引失效问题,并按索引知识一步步排查验证,直到我们认为OK。
希望通过上述的排查验证过程,结合上一篇的索引原理,可以让大家对索引的认识更进一步。