本文转载自微信公众号「人人都是极客」,作者布道师Peter。转载本文请联系人人都是极客公众号。
调度的发展历史
| 字段 | 版本 |
|---|---|
| O(n) 调度器 | linux0.11 - 2.4 |
| O(1) 调度器 | linux2.6 |
| CFS调度器 | linux2.6至今 |
- O(n) 调度器是在内核2.4以及更早期版本采用的算法,其调度算法非常简单和直接,就绪队列是个全局列表,从就绪队列中查找下一个最佳任务,由于每次在寻找下一个任务时需要遍历系统中所有的任务(全局列表),因此被称为 O(n) 调度器(时间复杂度)。
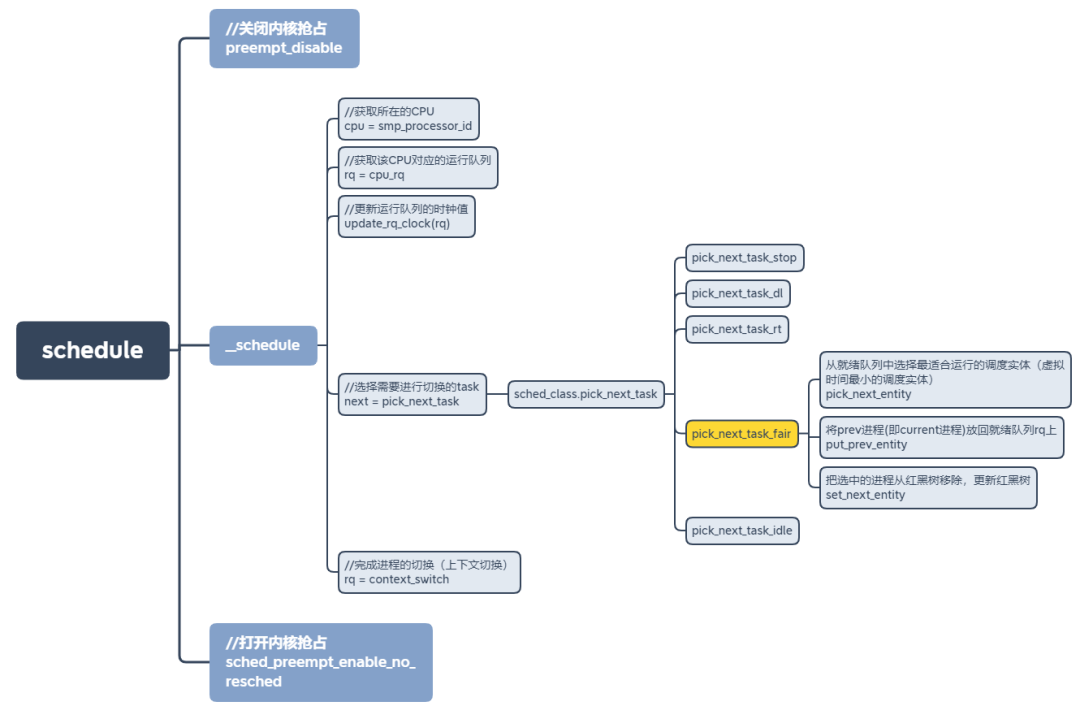
- 内核2.6采用了O(1) 调度器,让每个CPU维护一个自己的就绪队列,从而减少了锁的竞争。就绪队列由两个优先级数组组成,分别是active优先级数组和expired优先级数组。每个优先级数组包含140个优先级队列,也就是每个优先级对应一个队列,其中前100个对应实时进程,后40个对应普通进程。如下图所示:
这样设计的好处,调度器选择下一个被调度任务就变得高效和简单多了,只需要在active优先级数组中选择优先级高,并且队列中有可运行的任务即可。这里使用位图来定义该队列中是否有可运行的任务,如果有,则位图中相应的位就会被置1。这样选择下一个被调用任务的时间就变成了查询位图的操作。
- 但上面的算法有个问题,一个高优先级多线程的应用会比低优先级单线程的应用获得更多的资源,这就会导致一个调度周期内,低优先级的应用可能一直无法响应,直到高优先级应用结束。CFS调度器就是站在一视同仁的角度解决了这个问题,保证在一个调度周期内每个任务都有执行的机会,执行时间的长短,取决于任务的权重。下面详细看下CFS调度器是如何动态调整任务的运行时间,达到公平调度的。
实际运行时间
CFS是Completely Fair Scheduler简称,即完全公平调度器。CFS调度器和以往的调度器不同之处在于没有时间片的概念,而是公平分配cpu使用的时间。例如:2个相同优先级的进程在一个cpu上运行,那么每个进程都将会分配50%的cpu运行时间。这就是要实现的公平。
但现实中,必然是有的进程优先级高,有的进程优先级低。CFS调度器引入权重的概念,用权重代表进程的优先级,各个进程按照权重的比例分配cpu的时间。比如:2个进程A和B。A的权重是1024,B的权重是2048。那么A获得cpu的时间比例是1024/(1024+2048) = 33.3%。B进程获得的cpu时间比例是2048/(1024+2048)=66.7%。
在引入权重之后,分配给进程的时间计算公式如下:
实际运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
CFS调度器用nice值表示优先级,取值范围是[-20, 19],nice和权重是一一对应的关系。数值越小代表优先级越大,同时也意味着权重值越大,nice值和权重之间的转换关系:
- const int sched_prio_to_weight[40] = {
- /* -20 */ 88761, 71755, 56483, 46273, 36291,
- /* -15 */ 29154, 23254, 18705, 14949, 11916,
- /* -10 */ 9548, 7620, 6100, 4904, 3906,
- /* -5 */ 3121, 2501, 1991, 1586, 1277,
- /* 0 */ 1024, 820, 655, 526, 423,
- /* 5 */ 335, 272, 215, 172, 137,
- /* 10 */ 110, 87, 70, 56, 45,
- /* 15 */ 36, 29, 23, 18, 15,
- };
数组值计算公式是:weight = 1024 / 1.25nice。
公式中的1.25取值依据是:进程每降低一个nice值,将多获得10% cpu的时间。公式中以1024权重为基准值计算得来,1024权重对应nice值为0,其权重被称为NICE_0_LOAD。默认情况下,大部分进程的权重基本都是NICE_0_LOAD。
虚拟运行时间
根据上面的理解,这里看个例子。假如一个CPU的调度周期是6ms,进程A和B的权重分别是1024和820(nice值分别是0和1),那么进程A获得的运行时间是6x1024/(1024+820)=3.3ms,进程B获得的执行时间是6x820/(1024+820)=2.7ms。进程A的cpu使用比例是3.3/6x100%=55%,进程B的cpu使用比例是2.7/6x100%=45%。(符合上面说的“进程每降低一个nice值,将多获得10% CPU的时间”)
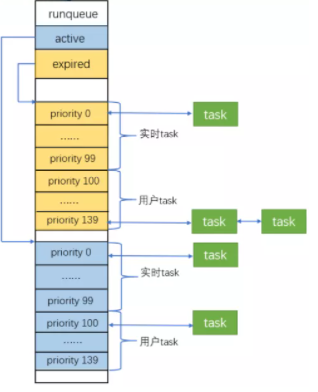
很明显,2个进程的实际执行时间是不相等的,但是CFS想保证每个进程运行时间相等。因此CFS引入了虚拟时间的概念,也就是说上面的2.7ms和3.3ms经过一个公式的转换可以得到一样的值,这个转换后的值称作虚拟时间。这样的话,CFS只需要保证每个进程运行的虚拟时间是相等的即可。虚拟时间vriture_runtime和实际时间(wall time)转换公式如下:
虚拟运行时间 = 实际运行时间 * NICE_0_LOAD / 进程权重 = (调度周期 * 进程权重 / 所有进程权重之和) * NICE_0_LOAD / 进程权重 = 调度周期 * 1024 / 所有进程总权重
从公式可以看出,在一个调度周期里,所有进程的虚拟运行时间是相同的。所以在进程调度时,只需要找到虚拟运行时间最小的进程调度运行即可。
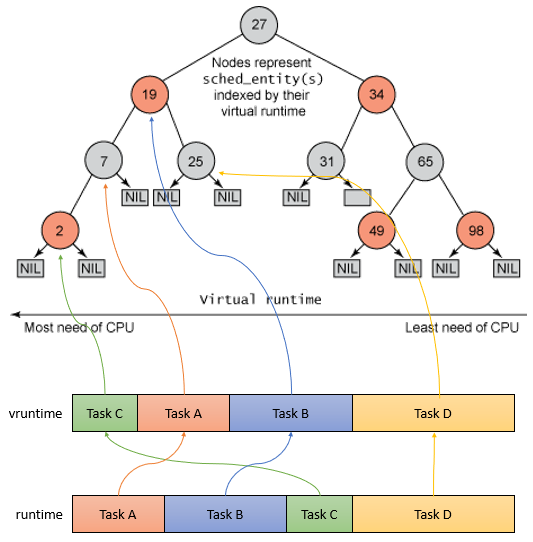
为了能够快速找到虚拟运行时间最小的进程,Linux 内核使用红黑树来保存可运行的进程。CFS跟踪调度实体sched_entity的虚拟运行时间vruntime,将sched_entity通过enqueue_entity()和dequeue_entity()来进行红黑树的出队入队,vruntime少的调度实体sched_entity排列到红黑树的左边。
如上图所示,红黑树的左节点比父节点小,而右节点比父节点大。所以查找最小节点时,只需要获取红黑树的最左节点即可。
相关步骤如下:
- 每个sched_latency周期内,根据各个任务的权重值,可以计算出运行时间runtime;
- 运行时间runtime可以转换成虚拟运行时间vruntime;
- 根据虚拟运行时间的大小,插入到CFS红黑树中,虚拟运行时间少的调度实体放置到左边;
- 在下一次任务调度的时候,选择虚拟运行时间少的调度实体来运行(pick_next_task从就绪队列中选择最适合运行的调度实体,即虚拟时间最小的调度实体);
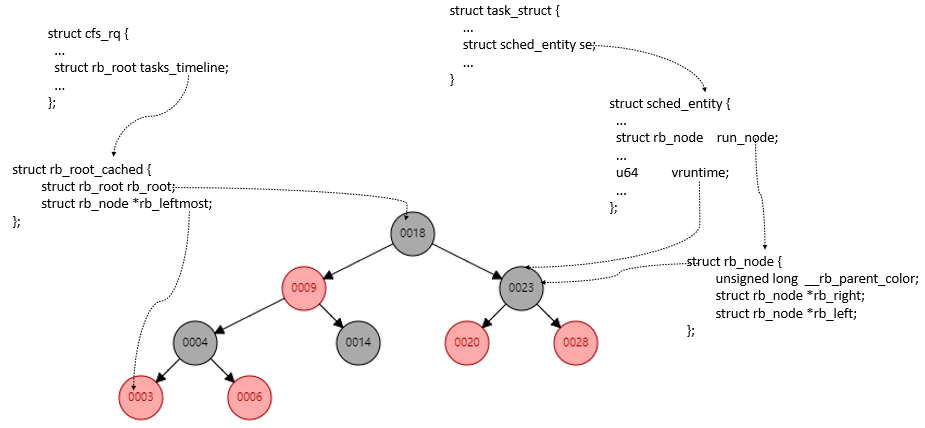
CFS 数据结构
task_struct: 任务描述符,包含很多进程相关的信息,例如,优先级、进程状态以及调度实体等。
- struct task_struct {
- ...
- struct sched_entity se;
- ...
- }
cfs_rq:跟踪就绪队列信息以及管理就绪态调度实体,并维护一棵按照虚拟时间排序的红黑树。tasks_timeline->rb_root是红黑树的根,tasks_timeline->rb_leftmost指向红黑树中最左边的调度实体,即虚拟时间最小的调度实体。
- struct cfs_rq {
- ...
- struct rb_root_cached tasks_timeline
- ...
- };
sched_entity:可被内核调度的实体。每个就绪态的调度实体sched_entity包含插入红黑树中使用的节点rb_node,同时vruntime成员记录已经运行的虚拟时间。
- struct sched_entity {
- ...
- struct rb_node run_node;
- ...
- u64 vruntime;
- ...
- };
这些数据结构的关系如下图所示:
CFS 算法实现
1.时钟中断 scheduler_tick 更新虚拟运行时间,检查是否需要抢占。
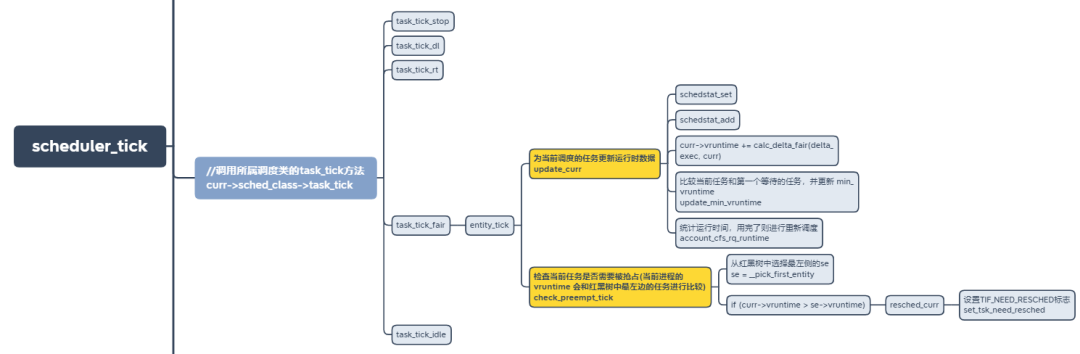
更新运行时的各类统计信息,比如vruntime, 运行时间、负载值、权重值等。
检查是否需要抢占,主要是比较运行时间是否耗尽,以及vruntime的差值是否大于运行时间等。
2.任务出队入队
当任务进入可运行状态时,用 enqueue_task_fair 将调度实体放入到红黑树中,完成入队操作;当任务退出可运行状态时,用 dequeue_task_fair 将调度实体从红黑树中移除,完成出队操作;队操作。

调用 __enqueue_entity 函数后,就可以把进程调度实体插入到运行队列的红黑树中。同时会把红黑树最左端的节点缓存到运行队列的 rb_leftmost 字段中,用于快速获取下一个可运行的进程。
从 cfs_rq 中获取下一个可运行的任务
每当进程任务切换的时候,也就是schedule函数执行时,调度器都需要选择下一个将要执行的任务。在CFS调度器中,是通过 pick_next_task_fair 函数完成的,其本质是从就绪队列中选择最适合运行的调度实体(虚拟时间最小的调度实体)。