本文转载自微信公众号「编程杂技」,作者 theanarkh 。转载本文请联系编程杂技公众号。
wireshark或tcpdump相信大家都用过,这些工具看起来都很酷,因为我们平时都是在界面看到应用层的数据,这些工具居然可以让我们看到tcp/ip协议栈每层的数据。本文介绍一下查看tcp/ip协议栈数据的方法。并实现一个简陋的sniffer,通过nodejs暴露出来使用。我们先看实现。
- #include <stdio.h>
- #include <errno.h>
- #include <unistd.h>
- #include <sys/socket.h>
- #include <sys/types.h>
- #include <linux/in.h>
- #include <linux/if_ether.h>
- #include <stdlib.h>
- #include <node_api.h>
- #define DATA_LEN 500
- static napi_value start(napi_env env, napi_callback_info info) {
- int sockfd;
- int bytes;
- char data[DATA_LEN];
- unsigned char *ipHeader;
- unsigned char *macHeader;
- unsigned char *transportHeader;
- // 对ETH_P_IP协议的数据包感兴趣,PF_PACKET在早期内核是AF_INET
- sockfd = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_IP));
- if (sockfd < 0) {
- printf("创建socket错误");
- exit(1);
- }
- while (1) {
- bytes = recvfrom(sockfd,data,DATA_LEN,0,NULL,NULL);
- printf("读到字节数:%d\n",bytes);
- macHeader = data;
- printf("MAC报文----------\n");
- printf("源Mac地址: %02x:%02x:%02x:%02x:%02x:%02x\n",
- macHeader[0],macHeader[1],macHeader[2],
- macHeader[3],macHeader[4],macHeader[5]);
- printf("目的Mac地址: %02x:%02x:%02x:%02x:%02x:%02x\n",
- macHeader[6],macHeader[7],macHeader[8],
- macHeader[9],macHeader[10],macHeader[11]);
- printf("上层协议: %04x\n",
- (macHeader[12] << 8) + macHeader[13]);
- // 跳过Mac头
- ipHeader = data + 6 + 6 + 2;
- printf("IP报文--------\n");
- printf("ip协议版本:%d\n",
- (ipHeader[0] & 0xF0) >> 4);
- int ipHeaderLen = (ipHeader[0] & 0x0F) << 2;
- printf("首部长度:%d\n",
- ipHeaderLen);
- printf("区分服务:%d\n",
- ipHeader[1]);
- printf("总长度:%d\n",
- (ipHeader[2]<<8)+ipHeader[3]);
- printf("标识:%d\n",
- (ipHeader[4]<<8)+ipHeader[5]);
- printf("标志:%d\n",
- (ipHeader[6] & 0xE0) >> 5);
- printf("片偏移:%d\n",
- (ipHeader[6] & 0x11) + ipHeader[7]);
- printf("TTL:%d\n",
- ipHeader[8]);
- printf("上层协议:%d\n",
- ipHeader[9]);
- printf("首部校验和:%x%x\n",
- ipHeader[10]+ipHeader[11]);
- printf("源ip:%d.%d.%d.%d\n",
- ipHeader[12],ipHeader[13],
- ipHeader[14],ipHeader[15]);
- printf("目的ip:%d.%d.%d.%d\n",
- ipHeader[16],ipHeader[17],
- ipHeader[18],ipHeader[19]);
- transportHeader = ipHeader + ipHeaderLen;
- printf("传输层报文-----------\n");
- printf("源端口:%d\n",
- (transportHeader[0]<<8)+transportHeader[1]);
- printf("目的端口:%d\n",
- (transportHeader[2]<<8)+transportHeader[3]);
- printf("序列号:%ud%ud%ud%ud\n",
- transportHeader[4],transportHeader[5],transportHeader[6],transportHeader[7]);
- printf("确认号:%ud\n",
- (transportHeader[8]<<24)+(transportHeader[9]<<16)+(transportHeader[10]<<8)+(transportHeader[11]));
- printf("传输层首部长度:%d\n",
- ((transportHeader[12] & 0xF0) >> 4) * 4);
- printf("FIN:%d\n",
- transportHeader[13] & 0x01);
- printf("SYN:%d\n",
- (transportHeader[13] & 0x02) >> 1);
- printf("RST:%d\n",
- (transportHeader[13] & 0x04) >> 2);
- printf("PSH:%d\n",
- (transportHeader[13] & 0x08) >> 3);
- printf("ACK:%d\n",
- (transportHeader[13] & 0x016) >> 4);
- printf("URG:%d\n",
- (transportHeader[13] & 0x32) >> 5);
- printf("窗口大小:%d\n",
- (transportHeader[14] << 8) + transportHeader[15]);
- }}
- napi_value Init(napi_env env, napi_value exports) {
- napi_value func;
- napi_create_function(env,
- NULL,
- NAPI_AUTO_LENGTH,
- start,
- NULL,
- &func);
- napi_set_named_property(env, exports, "start", func);
- return exports;
- }
- NAPI_MODULE(NODE_GYP_MODULE_NAME, Init)
我们看到实现并不复杂,首先创建一个socket,然后接收socket上面的数据进行分析就行。上面的代码可以捕获到所有发给本机的tcp/ip包,下面我们看看效果(有些字段还没有仔细处理)。
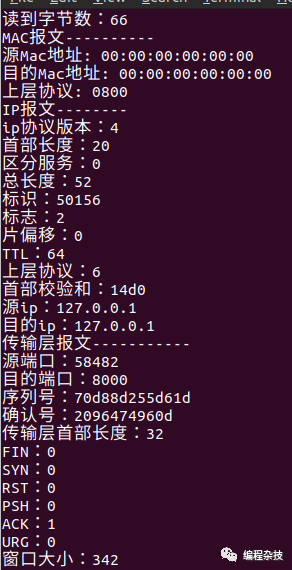
下面我们来看看底层的实现(2.6.13.1内核)。我们从socket函数的实现开始分析。
- asmlinkage long sys_socket(int family, int type, int protocol){
- int retval;
- struct socket *sock;
- // 创建一个socket
- retval = sock_create(family, type, protocol, &sock);
- // 返回文件描述符给用户
- retval = sock_map_fd(sock);
- }
接着看sock_create。
- int sock_create(int family, int type, int protocol, struct socket **res){
- return __sock_create(family, type, protocol, res, 0);
- }
- static int __sock_create(int family, int type, int protocol, struct socket **res, int kern){
- int err;
- struct socket *sock;
- // 分配一个socket
- if (!(sock = sock_alloc())) {
- // ...
- }
- // socket类型
- sock->type = type;
- err = -EAFNOSUPPORT;
- // 根据协议簇拿到对应的函数集,然后调用create函数
- if ((err = net_families[family]->create(sock, protocol)) < 0)
- goto out_module_put;
- }
我们看到__sock_create的逻辑很简单,根据协议簇拿到对应的函数集,然后执行其create函数。我们看看PF_PACKET协议簇对应的函数集。PF_PACKET协议簇通过packet_init注册了对应的函数集。
- static int __init packet_init(void){
- sock_register(&packet_family_ops);
- }
- static struct net_proto_family packet_family_ops = {
- .family = PF_PACKET,
- .create = packet_create,
- .owner = THIS_MODULE,
- };
我们看到create函数的值是packet_create。
- static int packet_create(struct socket *sock, int protocol){
- struct sock *sk;
- struct packet_sock *po;
- int err;
- // 分配一个packet_sock结构体
- sk = sk_alloc(PF_PACKET, GFP_KERNEL, &packet_proto, 1);
- // 赋值函数集
- sock->ops = &packet_ops;
- // 关联socket和sock
- sock_init_data(sock, sk);
- // 拿到一个packet_sock结构体,第一个字段是sock结构体(struct packet_sock *po)
- po = pkt_sk(sk);
- sk->sk_family = PF_PACKET;
- // 接收数据包的函数
- po->prot_hook.func = packet_rcv;
- po->prot_hook.af_packet_priv = sk;
- if (protocol) {
- po->prot_hook.type = protocol;
- dev_add_pack(&po->prot_hook);
- sock_hold(sk);
- po->running = 1;
- }
- }
packet_create首先创建了一个packet_sock结构体并初始化,最后调用dev_add_pack。
- static struct list_head ptype_base[16];
- void dev_add_pack(struct packet_type *pt){
- int hash;
- spin_lock_bh(&ptype_lock);
- if (pt->type == htons(ETH_P_ALL)) {
- netdev_nit++;
- list_add_rcu(&pt->list, &ptype_all);
- } else {
- hash = ntohs(pt->type) & 15;
- list_add_rcu(&pt->list, &ptype_base[hash]);
- }
- spin_unlock_bh(&ptype_lock);
- }
我们看到dev_add_pack的逻辑是往ptype_base对应的队列加入一个节点。接着我们看看网卡收到数据包的时候是如何处理的。
- int netif_receive_skb(struct sk_buff *skb){
- type = skb->protocol;
- list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) {
- if (ptype->type == type &&
- (!ptype->dev || ptype->dev == skb->dev)) {
- if (pt_prev)
- ret = deliver_skb(skb, pt_prev);
- pt_prev = ptype;
- }
- }
- ret = pt_prev->func(skb, skb->dev, pt_prev);
- }
netif_receive_skb的逻辑中会根据收到mac包中上层协议字段找到对应的处理函数,比如本文的packet。最后执行func。从刚才的create函数我们看到func的值是packet_rcv。
- static int packet_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt) {
- __skb_queue_tail(&sk->sk_receive_queue, skb);
- sk->sk_data_ready(sk, skb->len);
- }
packet_rcv首先把收到的数据包插入socket的接收队列,然后调用sk_data_ready通知socket,对应函数是sock_def_readable。
- static void sock_def_readable(struct sock *sk, int len){
- if (sk->sk_sleep && waitqueue_active(sk->sk_sleep))
- wake_up_interruptible(sk->sk_sleep);
- }
sock_def_readable会唤醒阻塞在该socket的进程。那么这个队列里有什么呢?我们回到文章开始的代码,我们创建socket后阻塞在recvfrom。recvfrom通过层层调用最后执行对应函数集的recvmsg。
- static int packet_recvmsg(struct kiocb *iocb, struct socket *sock,
- struct msghdr *msg, size_t len, int flags){
- struct sk_buff *skb;
- skb=skb_recv_datagram(sk,flags,flags&MSG_DONTWAIT,&err);
- }
packet_recvmsg从socket的接收队列取出一个数据包,我们看看skb_recv_datagram。
- struct sk_buff *skb_recv_datagram(struct sock *sk, unsigned flags,
- int noblock, int *err){
- struct sk_buff *skb;
- long timeo;
- /*
- static inline long sock_rcvtimeo(const struct sock *sk, int noblock)
- {
- return noblock ? 0 : sk->sk_rcvtimeo;
- }
- 获取没有数据包时等待的超时时间
- */
- timeo = sock_rcvtimeo(sk, noblock);
- do {
- skb = skb_dequeue(&sk->sk_receive_queue);
- // 有则返回
- if (skb)
- return skb;
- // 没有
- error = -EAGAIN;
- // 不等待则直接返回
- if (!timeo)
- goto no_packet;
- // 否则等待一段时间
- } while (!wait_for_packet(sk, err, &timeo));
- }
我们看到没有数据包的时候会等待一段时间,我们看看这个时间是多少。
- sk->sk_rcvtimeo = MAX_SCHEDULE_TIMEOUT;
- #define MAX_SCHEDULE_TIMEOUT LONG_MAX
我们看到超时时间非常长,当然这个值我们可以通过setsockopt的SO_RCVTIMEO选项设置。接着我们看等待的逻辑wait_for_packet。
- #define DEFINE_WAIT(name) \
- wait_queue_t name = { \
- .private = current, \
- .func = autoremove_wake_function, \
- .task_list = LIST_HEAD_INIT((name).task_list), \
- }
- static int wait_for_packet(struct sock *sk, int *err, long *timeo_p){
- DEFINE_WAIT(wait);
- prepare_to_wait_exclusive(sk->sk_sleep, &wait, TASK_INTERRUPTIBLE);
- int error = 0;
- *timeo_p = schedule_timeout(*timeo_p);
- out:
- finish_wait(sk->sk_sleep, &wait);
- return error
- }
wait_for_packet首先把当前进程插入对应的等待队列并修改进程状态为非就绪(TASK_INTERRUPTIBLE)
- void fastcall prepare_to_wait_exclusive(wait_queue_head_t *q, wait_queue_t *wait, int state){
- // 把当前进程插入等待队列
- if (list_empty(&wait->task_list))
- __add_wait_queue_tail(q, wait);
- // 修改进程状态
- set_current_state(state);
- }
接着执行进程调度schedule_timeout。
- fastcall signed long __sched schedule_timeout(signed long timeout){
- struct timer_list timer;
- unsigned long expire;
- // 超时时间
- expire = timeout + jiffies;
- // 开启定时器
- init_timer(&timer);
- timer.expires = expire;
- timer.data = (unsigned long) current;
- timer.function = process_timeout;
- // 启动定时器
- add_timer(&timer);
- // 进程调度
- schedule();
- timeout = expire - jiffies;
- out:
- return timeout < 0 ? 0 : timeout;
- }
以上就是实现捕获tcp/ip协议栈数据包的底层原理。代码仓库https://github.com/theanarkh/node-sniffer