【51CTO.com快译】图像分割是确定图像中对象的边界和区域的过程。虽然人类对图像不需要有意识地进行分割,但这对于机器学习系统来说仍然一个关键挑战。这一技术对加强自动化机器人、自动驾驶汽车以及其他人工智能系统的功能至关重要,这些人工智能系统必须在现实世界中进行交互和导航。

直到现在,图像分割还需要大型计算密集型神经网络进行处理。这使得很多设备在没有连接到云计算服务器的情况下很难运行这些深度学习模型。
DarwinAI公司和滑铁卢大学公司的研究人员成功地创建了一个神经网络,该网络提供了近乎最佳的分割功能,并且其足够小可以适用于资源受限的设备。研究人员在今年举办的一个计算机视觉和模式识别(CVPR)会议上在演讲报告中详细介绍了这种名为“AttendSeg”的神经网络。
对象的分类、检测和分割
人们对机器学习系统越来越感兴趣的一个主要原因是可以解决计算机视觉中的一些问题。机器学习在计算机视觉中最常见的应用包括图像分类、对象检测和图像分割。
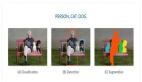
图像分类以确定图像中是否存在某种类型的对象。对象检测使图像分类更进一步,并提供了检测到的对象所在的边界。
而分割有两种形式:语义分割和实例分割。语义分割可以指定输入图像中每个像素的对象类别。实例分割可将每种类型的对象的各个实例进行区分。在实际应用中,分割网络的输出通常通过对像素着色来表示。而分割则是迄今为止最复杂的分类任务。

图像分类vs对象检测vs语义分割
卷积神经网络(CNN)是计算机视觉任务中常用的一种深度学习架构,其复杂度通常以其参数的数量来衡量。神经网络的参数越多,它需要的内存量和计算能力就越高。
RefineNet是一种流行的语义分割神经网络,其中包含8500多万个参数,而每个参数为4字节,这意味着使用RefineNet的应用程序至少需要具体340M的内存才能运行神经网络。考虑到神经网络的性能在很大程度上取决于能够执行快速矩阵乘法的硬件,这意味着模型必须加载到图形卡或其他一些并行计算单元上,在这些单元中,其内存比计算中的内存少得多。
边缘设备的机器学习
由于其硬件要求,大多数图像分割应用程序都需要连接互联网才能将图像发送到可以运行大型深度学习模型的云计算服务器。连接云平台可能会限制使用图像分割的位置。例如,如果无人机或机器人将在没有互联网连接的环境中运行,那么执行图像分割将成为一项艰巨的任务。在其他领域,人工智能代理将在敏感环境中工作,并且将图像发送到云平台将受到隐私和安全性约束。在需要来自机器学习模型的实时响应的应用程序中,由往返于云平台造成的网络延迟可能会令人望而却步。值得注意的是,网络硬件本身会消耗大量电能,而向云平台发送恒定的图像可能会增加电池供电的设备的负担。
由于这些原因,边缘人工智能和微型机器学习(TinyML)成为学术界和应用人工智能领域的关注和研究的热点。TinyML的目标是创建可以在内存和功耗受限的设备上运行而无需连接到云平台的机器学习模型。
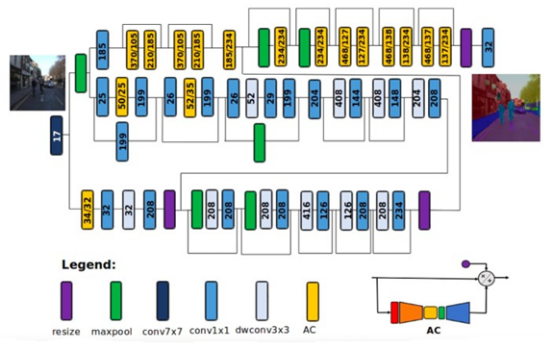
AttendSeg设备上语义分割神经网络的架构
借助AttendSeg,DarwinAI公司和滑铁卢大学的研究人员试图解决边缘计算设备上语义分割的挑战。
DarwinAI公司联合创始人兼滑铁卢大学副教授Alexander Wong说,“AttendSeg的想法是由我们对推进微型机器学习(TinyML)领域发展的渴望。以及我们将其视为满足DarwinAI公司的市场需求所驱动的。高效的边缘分割方法在工业上有很多应用,我认为正是这种反馈和市场需求推动了我们的研究。”
Wong表示,AttendSeg是为微型机器学习(TinyML)应用量身定制的低精度、高度紧凑的深度语义分割神经网络。
AttendSeg深度学习模型以几乎与RefineNet相当的精度执行语义分割,同时将参数数量减少到119万个。有趣的是,研究人员还发现,将参数的精度从32位(4字节)降低到8位(1字节)并不会导致显著的性能损失,同时使AttendSeg的内存占用减少了四倍。该型号需要略高于1M字节的内存,这足够小,适用于大多数边缘设备。
Alexander Wong说,“根据我们的实验,8位的参数对网络的可推广性没有限制,这表明低精度的表示在这种情况下是非常有益的。”

实验表明,AttendSeg深度学习模型提供了最佳的语义分割,同时减少了参数数量和内存占用量。
用于计算机视觉的自我关注机制
AttendSeg利用自我关注机制来减小模型尺寸,而不会影响运行性能。自我关注机制是通过关注重要信息来提高神经网络效率的机制。自我关注机制已经成为自然语言处理领域的福音。它们一直是诸如Transformers之类的深度学习架构成功的决定性因素。虽然以前的架构(例如递归神经网络)在较长的数据序列上具有有限的容量,但是Transformers使用自我关注机制来扩大其范围。诸如GPT-3之类的深度学习模型利用“Transformers”和自我关注机制来产生长字符串,这些字符串(至少在表面上)在长跨度上保持连贯性。
人工智能研究人员还利用自我关注机制来提高卷积神经网络的性能。去年,Wong和他的同事引入了一种非常节省资源的自我关注机制,并将其应用于图像分类器机器学习模型中。
Wong说:“这种机制允许采用非常紧凑的深度神经网络架构,该架构仍然可以实现高性能,使其非常适合边缘计算和微型机器学习(TinyML)应用。”
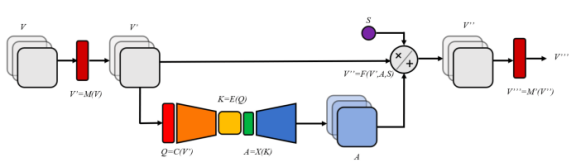
自我关注机制以一种记忆有效的方式提高了卷积神经网络的性能
机器驱动的神经网络设计
设计TinyML神经网络的关键挑战之一是找到性能最佳的架构,同时还要注意不能超出目标设备的资源。
为了应对这一挑战,研究人员使用了“生成合成”(Generative Synthesis)技术,这是一种可以根据特定的目标和约束创建神经网络架构的机器学习技术。研究人员无需人工设置各种配置和架构,而是为机器学习模型提供一个问题空间,可让它发现最佳组合。
Wong说,“这里使用的机器驱动设计过程(生成合成)要求人工提供初始设计原型和其指定的预期操作要求(例如尺寸、精度等),机器驱动设计过程将从中学习,并围绕操作需求、任务和数据量身定制最佳架构设计。”
在他们的实验中,研究人员使用机器驱动的设计来调整Nvidia Jetson的AttendSeg、机器人和边缘人工智能应用的硬件包。但AttendSeg并不局限于应用在Jetson。
Wong说:“从本质上来说,与先前的文献中提出的神经网络相比,AttendSeg神经网络将在大多数边缘计算硬件上快速运行。但是,如果要生成针对特定硬件量身定制的AttendSeg,则可以使用机器驱动的设计方法,可以创建一个新的高度定制化的网络。”
AttendSeg更适合在无人机、机器人和自动驾驶车辆中的应用,其中语义分割是实现导航的关键要求,但是设备上的分割可以有更多的应用程序。
Wong说,“这种高度紧凑、更加高效的分割神经网络可以用于各行业领域的应用,其中包括制造应用(如零件检查/质量评估、机器人控制)、医疗应用(如细胞分析、肿瘤分割)、卫星遥感应用(例如如土地覆盖物的分割)和移动设备应用程序(例如增强现实中的人体分割)等。”
原文标题:New deep learning model brings image segmentation to edge devices,作者:Ben Dickson
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】