最近一段时间,多层感知机(MLP)成为 CV 领域的重点研究对象,谷歌、清华大学等机构的研究者先后提出了纯 MLP 构建的视觉架构和新的注意力机制,这些研究将 CV 的研究重心重新指向 MLP。近日,Facebook 提出了具有数据高效训练、用于图像分类的纯 MLP 架构 ResMLP,当采用现代的训练方法时,该架构在 ImageNet 数据集上实现了相对不错的性能。
前几天,谷歌提出的 MLP-Mixer 引爆 CV 圈,无需卷积、注意力机制,仅需 MLP 即可实现与 CNN、ViT 相媲美的性能。
同样地,清华大学的 Jittor 团队提出了一种新的注意机制,称之为「External Attention」,基于两个外部的、小的、可学习的和共享的存储器,只用两个级联的线性层和归一化层就可以取代现有流行的学习架构中的「Self-attention」,进一步揭示了线性层和注意力机制之间的关系;此外,清华大学丁贵广团队将 MLP 作为卷积网络的一种通用组件实现多种任务性能提升。
MLP->CNN->Transformer->MLP 圈似乎已成为一种趋势。
近日,来自 Facebook 的研究者进一步推动了这一趋势,他们提出了 ResMLP(Residual Multi-Layer Perceptron ),一种用于图像分类的纯多层感知机(MLP)架构。

论文链接:https://arxiv.org/pdf/2105.03404.pdf
该架构极为简单:它采用展平后的图像 patch 作为输入,通过线性层对其进行映射,然后采用两个残差操作对投影特征进行更新:(i)一个简单的线性 patch 交互层,独立用于所有通道;(ii)带有单一隐藏层的 MLP,独立用于所有 patch。在网络的末端,这些 patch 被平均池化,进而馈入线性分类器。
该架构是受 ViT 的启发,但更加简单:不采用任何形式的注意力机制,仅仅包含线性层与 GELU 非线性激活函数。该体系架构比 Transformer 的训练要稳定,不需要特定 batch 或者跨通道的标准化(如 Batch-Norm、 GroupNorm 或 LayerNorm)。训练过程基本延续了 DeiT 与 CaiT 的训练方式。
由于 ResMLP 的线性特性,模型中的 patch 交互可以很容易地进行可视化、可解释。尽管第一层学习到的交互模式与小型卷积滤波器非常类似,研究者在更深层观察到 patch 间更微妙的交互作用,这些包括某些形式的轴向滤波器(axial filters)以及网络早期长期交互。
架构方法
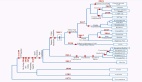
ResMLP 的具体架构如下图 1 所示,采用了路径展平(flattening)结构:
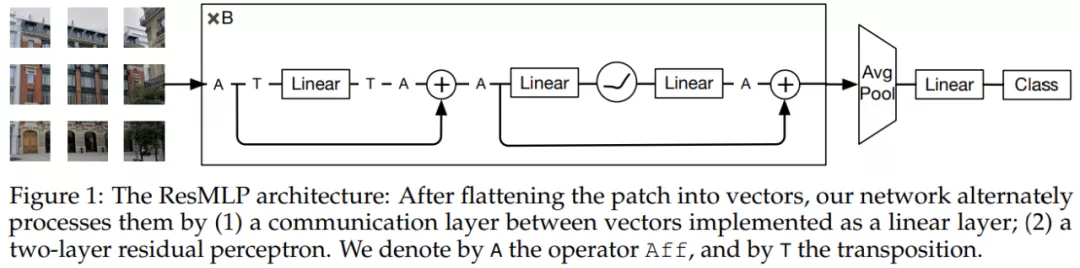
整体流程
ResMLP 以 N×N 非重叠 patch 组成的网格作为输入,其中 N 通常为 16。然后,这些非重叠 patch 独立地通过一个线性层以形成 N^2 个 d 维嵌入。接着,生成的 N^2 个 d 维嵌入被馈入到一个残差 MLP 层序列中以生成 N^2 个 d 维输出嵌入。这些输出嵌入又被平均为一个表征图像的 d 维向量,这个 d 维向量被馈入到线性分类器中以预测与图像相关的标签。训练中使用到了交叉熵损失。
残差多感知机层
网络序列中的所有层具有相同的结构:线性子层 + 前馈子层。类似于 Transformer 层,每个子层与跳远连接(skip-connection)并行。研究者没有使用层归一化(LayerNormalization),这是因为当使用公式(1)中的 Affine 转换时,即使没有层归一化,训练也是稳定的。
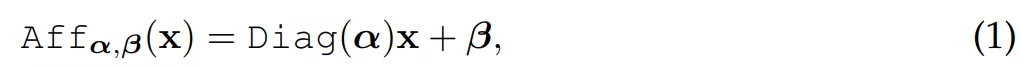
研究者针对每个残差块都使用了两次 Affine 转换。作为预归一化,Aff 替代了层归一化,并不再使用通道级统计(channel-wise statistics)。作为残差块的后处理,Aff 实现了层扩展(LayerScale),因而可以在后归一化时采用与 [50] 中相同的小值初始化。这两种转换在推理时均集成至线性层。
此外,研究者在前馈子层中采用与 Transformer 中相同的结构,并且只使用 GELU 函数替代 ReLU 非线性。
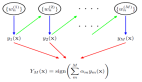
与 Transformer 层的主要区别在于,研究者使用以下公式(2)中定义的线性交互替代自注意力:
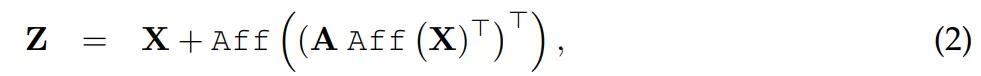
与 ViT 的关联
ResMLP 是 ViT 模型的大幅度简化,但具有以下几个不同点:
- ResMLP 没有采用任何自注意力块,使用的是非线性(non-linearity)的线性 patch 交互层;
- ResMLP 没有采用额外的「类(class)」token,相反只使用了平均池化;
- ResMLP 没有采用任何形式的位置嵌入,不需要的原因是 patch 之间的线性通信模块考虑到了 patch 位置;
- ResMLP 没有采用预层归一化,相反使用了简单的可学习 affine 转换,从而避免了任何形式的批和通道级统计。
实验结果
研究者在 ImageNet-1k 数据集上训练模型,该数据集包含 1.2M 张图像,平均分布在 1000 个对象类别中。他们在实验中采用了两种训练范式:监督学习和知识蒸馏。
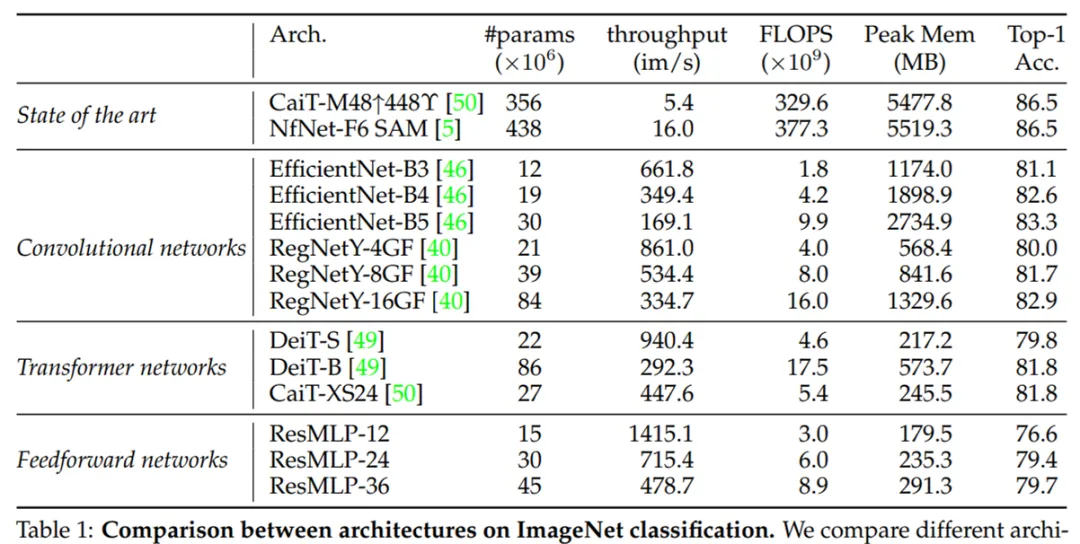
首先,研究者将 ResMLP 与 Transformer、convnet 在监督学习框架下进行了比较,如下表 1 所示,ResMLP 取得了相对不错的 Top-1 准确率。
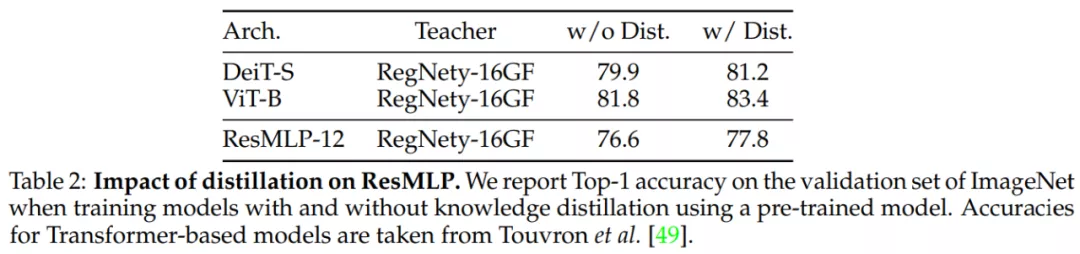
其次,利用知识蒸馏提高模型的收敛性,结果如下表 2 所示。与 DeiT 模型类似,ResMLP 可以从 convnet 蒸馏中显著获益。
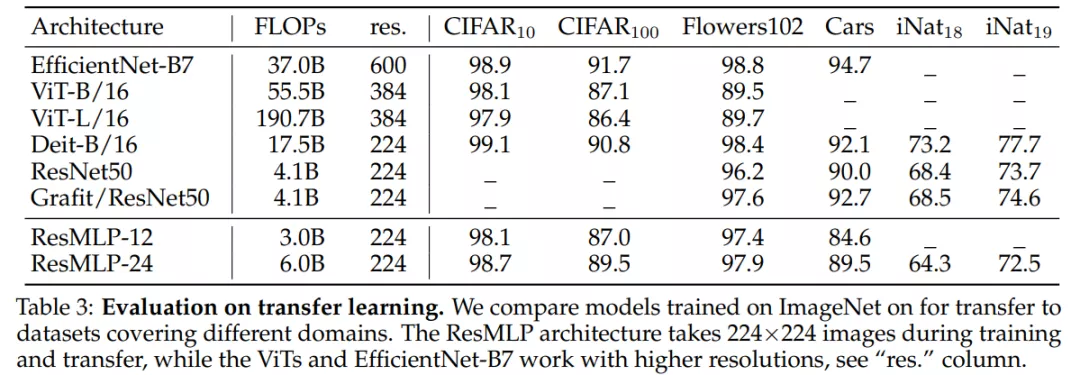
实验还评估了 ResMLP 在迁移学习方面的性能。下表 3 展示了不同网络架构在不同图像基准上的性能表现,数据集采用了 CIFAR-10、CIFAR100、Flowers-1022、 Stanford Cars 以及 iNaturalist 。
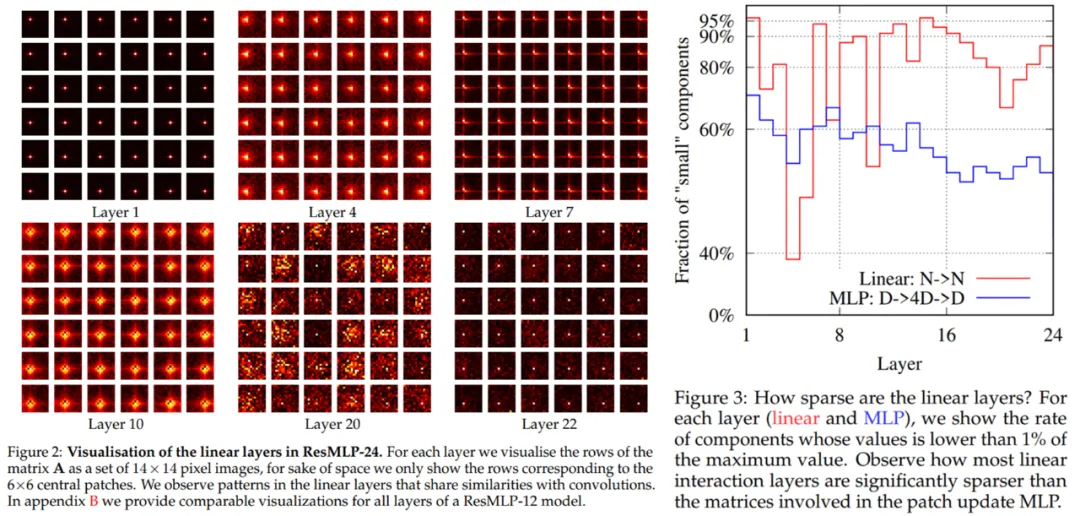
权重稀疏性测量也是研究者的关注点之一。下图 2 的 ResMLP-24 线性层的可视化结果表明线性通信层是稀疏的,并在下图 3 中进行了更详细的定量分析。结果表明,所有三个矩阵都是稀疏的,实现 patch 通信的层明显更稀疏。
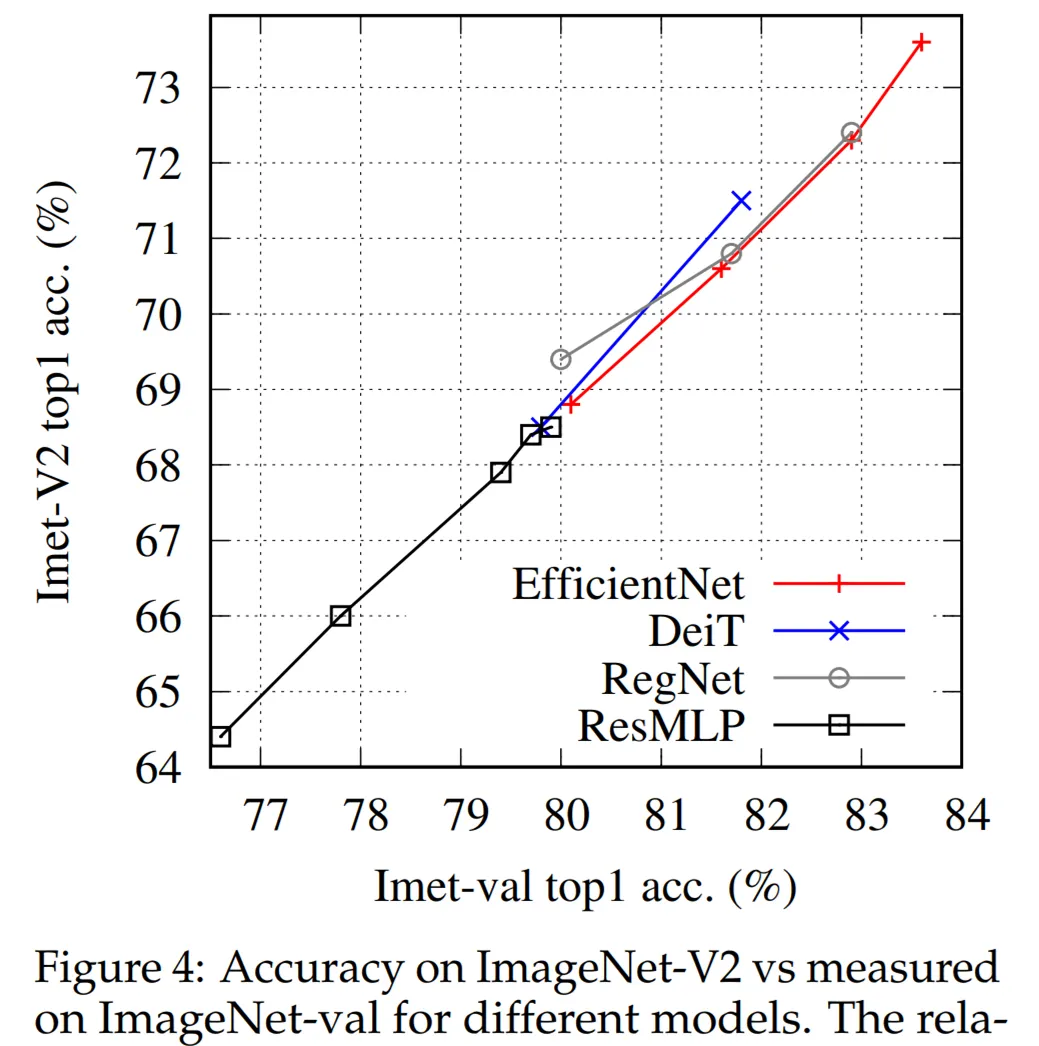
最后,研究者探讨了 MLP 的过拟合控制,下图 4 控制实验中探索了泛化问题。