【51CTO.com原创稿件】 Apache HBase 是 Hadoop 的大数据存储数据库,一个分布式、可伸缩的大数据存储,是依赖 Hadoop。
图片来自 Pexels
HBase 该技术来源于 Fay Chang 所撰写的 Google 论文“Bigtable:一个结构化数据的分布式存储系统”。
就像 Bigtable 利用了 Google 文件系统(File System)所提供的分布式数据存储一样,HBase 在 Hadoop 之上提供了类似于 Bigtable 的能力。
BATJ 公司为什么用 HBase 能存储海量的数据?
- 因为 HBase 是在 HDFS 的基础之上构建的,HDFS 是分布式文件系统。
- Hbase 设计上属于列式存储,在存储上将业务的数据按照水平分割的模式来划分,因此在查询与插入的时候比较聚焦。
- HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,特别是 HBase 基于列的而不是基于行的模式存储
为什么要用 HBase
①分布式存储引擎分类
分布式存储引擎大概分类如下:
- 分布式搜索(Elasticsearch)
- 分布式文件系统(HDFS)
- 分布式消息队列(Kafka)
- 缓存数据库(Redis)
- 非关系型分布式数据库(Hbase\Mongodb\Cloudant)
- 等等...
②存储引擎的存储方式
存储引擎的存储方式如下:
- Redis 有 AOF 和 RDB
- Elasticsearch 会把数据写到 translog 然后结合 FileSystemCache 将数据刷到磁盘中
- Kafka 本身就是将数据顺序写到磁盘....
这些中间件都能够实现持久化(比如 HDFS 和 MySQL 我们本身就用来存储数据的),那用 HBase 干啥呢?
③各种存储引擎优缺点
HDFS 可以保存海量数据,容错性高,适合批处理,适合保存大量数据,可以流式数据访问,对于服务器的要求也不高,但是他也有一些不足如,不适合低延时数据访问。
比如毫秒级的存储数据,是做不到的,也没办法高效的对大量小文件进行保存处理,而且一个文件只能有一个线程写入,不允许多个线程同时写入,也不支持文件的随机修改。
MySQL 是我们日常中用的比较多的关系型数据库了,但是大家都知道 MySQL,他是单机的。
单机 MySQL 他最大的容量,完全取决于服务器的硬盘容量的大小。其最致命的弱点就是当有大量数据需要存储时,MySQL 很难扛得住。
Elasticsearch 大家都知道他是一个分布式搜索引擎,在搜索效率上还是比较快的。
因为 Elasticsearch 基于分布式所以理论上也是可以保存大量的数据的,我们也可以根据索引来取出来,那这就是我们心目中最完美的存储方式了吗?
不,他不是,因为如果我们存储的数据没有经常需要查询的需求,其实放到 Elasticsearch 就是一种浪费,因为数据在写入 Elasticsearch 时需要进行分词,从而大量消耗资源,造成没必要的浪费。
Redis 是近几年最常用的缓存数据库,读与写的操作都在内存中进行,其速度响应非常快,AOF/RDB 保存的相关数据全会加载到我们机器的内存中,从而导致 Redis 并不适合保存大量的数据,毕竟内存还是相对有限。
Kafka 在我们项目工作中主要用来处理消息的解耦于异步削峰,当数据到达 Kafka,此时就会将数据持久化到服务器硬盘中,且很方便的扩展因为他是分布式的,按照这个逻辑 Kafka 是可以存储大量数据。
但是 Kafka 持久化了的数据,最常见的用法就是直接重新设置 offset 进行操作。
④Hbase 的使用场景
Hbase 适合需对数据进行随机读操作或者随机写操作、大数据上高并发操作,比如每秒对 PB 级数据进行上千次操作以及读写访问均是非常简单的操作。
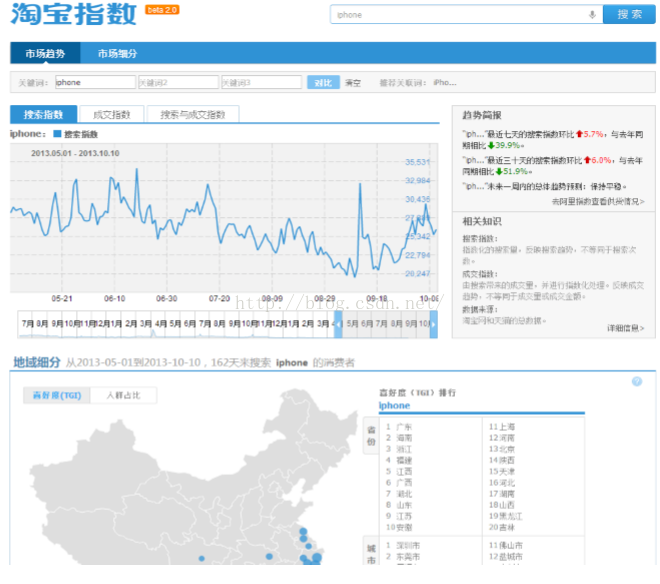
淘宝指数是 Hbase 在淘宝的一个典型应用。交易历史纪录查询很适合用 Hbase 作为底层数据库。
入门 HBase
①HBase 特性
Hbase 作为一种 NoSQL 数据库,而这就说明他不是传统的 RDBMS 数据库,且 SQL 语句也是不支持的。
对于 Hbase 是一种分布式存储的数据库,在技术层面来讲,它是属于分布式存储,因为缺少很多 RDBMS 数据库的特性。
那 Hbase 有什么特点呢?如下:
大,他容量巨大,HBase 的单表可以有百亿行、百万列,可以在横向和纵向两个维度插入数据,具有很大的弹性。
稀疏性,这主要体现在 Hbase 针对列有着很高的灵活性,比如对于为 NULL 的列中,是不会占用存储空间的,所以表可以设计的很稀疏。
易扩展,因为前面我也讲到过 HBase 是工作在 HDFS 之上的,所以自然是支持分布式表,同时也继承了 HDFS 的可扩展性。
而且 HBase 的扩展是横向扩展的,所谓的横向扩展是指在扩展的时候不需要提高服务器性能,只需要添加服务器到现有的集群即可。
高并发,如果项目使用 Hbase 的架构,那么使用的 PC 都可以很便宜,因此高 IO 也是常事。
而我所说的高并发,主要是他和其他 NoSQL 一样,Hbase 不支持复杂的 SQL 语句,这就给性能优化带来更多可能,并且主要是在内存中工作,支持大并发应该是没问题的。
还有别忘了,HBase 是天然支持分布式的,所以还可以利用集群等方法提高并发量。
高可用,还是因为 HBase 是运行在 HDFS 上的,HDFS 的多副本存储,类似于 MySQL 主备容灾,他可以在岀现故障时自行恢复,同时 HBase 还有更多的策略如:Replication,WAL 等。
面向列,这个与我们常用的 MySQL 等关系型数据库不同,HBase 是面向列的存储控制的。
简单来说就是每个列他都是是单独存储的,而且支持直接对列来进行查询,下面这张图可以简单来理解下什么是对列的操作。
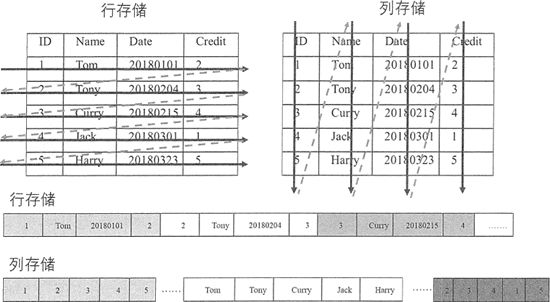
从图上来理解,看下下面的行存储于列存储其中行存储是保存在一块的,而列存储中的数据是分割的。
由上图得知行存储更适合插入与更新,而查询操作时需要读取其中所有的数据,此时 HBase 列存储则只需要读取相关列即可,从而可以大幅降低系统 I/O 吞吐量,达到快速读取的目的。
②什么情况更适合使用 Hbase
首先 Hbase 不是万能的,他也有不适合的场景,有哪些不适合场景呢?
这主要也是根据其特点来说的,首先一点就是数据量要大,如果你的数据只有区区几百万条或者更少的数据量,那么关系型数据库可能更适合你。
因为数据量不大的话,根本体现不出 HBase 的优势,反而会成为累赘,因为有大量的机器空闲,浪费资源。
再一个就是你对于列查询的使用不是那么高,且你也不需要辅助索引,静态类型的列等 HBase 的特性,在现有项目中使用关系型数据库已经可以满足其需求,则你完全没必要为了技术而去使用。
如果非要使用对于以往的项目你还需要重新去设计重构等,带来不必要的麻烦。
最后虽然 Hbase 在单机环境也能运行,但是最好请在开发环境的时候使用。
③HBase 的 Key-Value
HBase 其实就与 Redis 一样是 Key-Value 的数据库,那在 HBase 里边,Key 是什么?Value 是什么?
首先 KeyValue 的概念设计源自一片论文为"The log-structured merge-tree(LSM-Tree)"。
其中的每一行,每一列的数据,都被独立包装成特定结构即 KeyValue,而 KeyValue 还包含了很多自我描述信息从而会导致数据膨胀 。
目前市面上所有项目主要数据结构有:
- 结构化数据
- 半结构化数据
- 非结构化数据
由于 HBase 的稀疏性,导致其对于非结构化的数据存储有着天然的优势,而在我们日常项目中, 关系型数据也就是结构化数据是经常使用到的 。
由于 HBase 目前只能提供基于 RowKey 的单维度索,在我们日常项目中还是有些吃力。
还需要基于 HBase 添加一些特殊功能,如:
- GeoMesa 时空数据存储
- JanusGraph 图数据存储
- OpenTSDB 时序数据存储
既然如此,不如专业的事情交给专业的的去做,既然 MySQL,Oracle,MSSQL 这些关系型数据库这么擅长处理结构化数据,那就让他们来处理好了。
他们既然不擅长处理海量非结构化数据,那就上 HBase,所以我的理解 HBase 不是万能的,他只是相对于传统关系型数据库的一种补充。
④HBase 架构
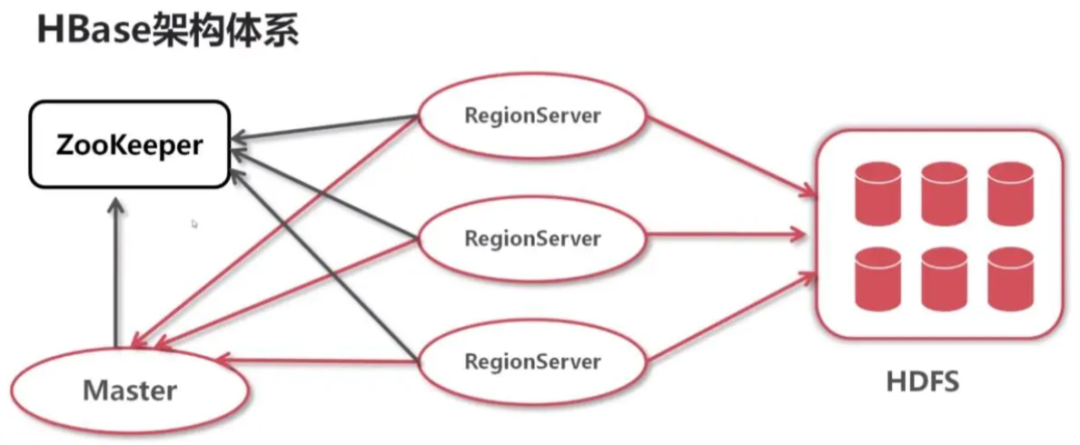
HBase 架构如上图:
- Zookeeper,主要作用是分布式协调。
- RegionServer,作为数据节点,用于存储数据,也会把自己的信息写到 ZooKeeper 中。
- HDFS,是在这里主要作为 HBase 的基础,是一个 分布式文件系统,为 HBase 提供服务。
- Master,主要负责管理所有的 RegionServer,管理所有的 Region 到 RegionServer 的分配,且自身也可以作为一个 RegionServer 提供服务。
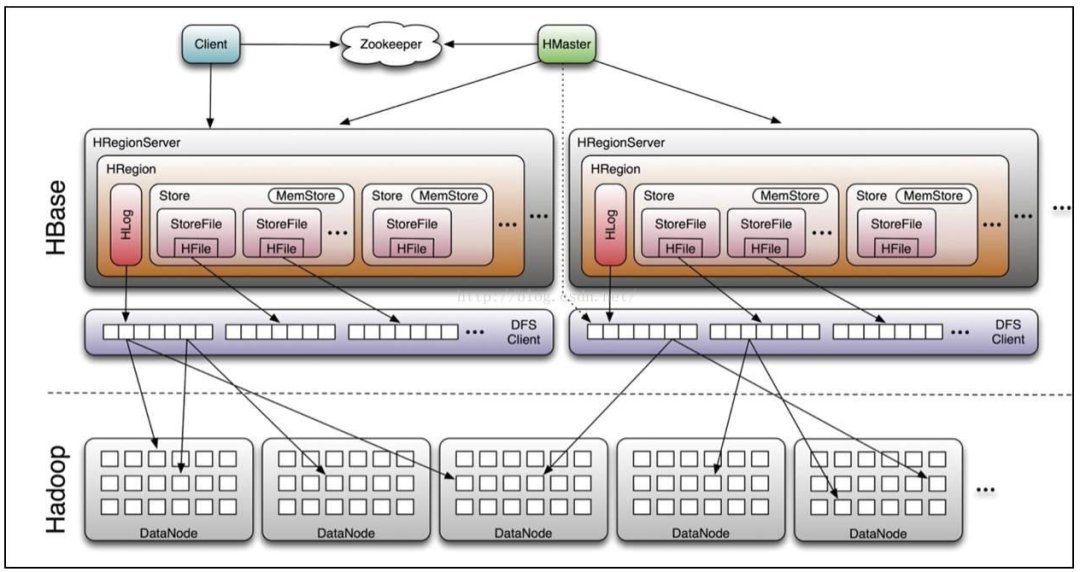
其大概流程就是:
- client 请求到 Zookeeper。
- Zookeeper 返回 HRegionServer 地址给 client。
- 当 client 获取到 Zookeeper 返回的地址就去请求 HRegionServer。
- HRegionServer 读写数据后再返回给 client。
⑤HMaster 大作用
看上面的流程我好像没有提到 HMaster,那 HMaster 是不是没啥用?那他主要是做什么的呢?
其实他的作用是不能被忽略的有:
- 负责 Region server 分布式管理与负载均衡
- 为 Region server 分配 region
- 在 HRegion 分裂后,负责新 HRegion 的分配
- 将 HDFS 上的垃圾文件回收
- 处理 schema 更新请求
由此可以看来 HMaster 相当于指挥家,统筹大局,非常重要!
RowKey 的设计
RowKey 在查询和保存方面有着很重要的作用,HBase 中如果设计好一个 RowKey 将会影响到其中数据的分布,与我们的查询速度。
由此得知设计好一个优秀的 RowKey 是非常重要的,那么这么重要的 RowKey 我们如何来设计呢?
首先要遵从以下几个原则:
长度原则:最短越好,最短越好,最短越好,重要的事情说三遍,最大不能超过 64K。如果太长主要影响有两点,
首先特别影响 HFile 的存储效果。其次 MemStore 将缓存部分数据到内存,如果 RowKey 字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
总结:保存慢,查询慢!
唯一原则:这个应该很好理解,RowKey 存储结构是 Key-Value 形式,跟 Java 中的 Map 一样,如果向同一个 Map 保存相同的 Key 的值,后保存的值会覆盖掉之前保存的值。
排序原则:HBase 会把 RowKey 按照 ASCII 进行自然有序排序,所以反过来我们在设计 RowKey 的时候可以根据这个特点来设计完美的 RowKey,好好的利用这个特性就是排序原则。
散列原则:如果 RowKey 按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将 RowKey 的高位作为散列字段,由程序随机生成,低位放时间字段。
这样将提高数据均衡分布在每个 RegionServer,以实现负载均衡的几率。
如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个 RegionServer 上。
这样在数据检索的时候负载会集中在个别的 RegionServer 上,造成热点问题,会降低查询效率。
①根据 RowKey 模糊查询
接下来直接上战场,首先我们根据业务场景需求,肯定还是需要进行在上 T 数据中查询部分数据的,那就是通过 RowKey 的方式进行模糊查询。
- hbase shell #首先登录hbase
- list #查询系统中所有数据库表
- scan 'tablename',{STARTROW=>'rowkey1',STOPROW=>'rowkey2'}
②根据 RowKey 范围查询
这里演示的是时间范围查询,TIMERANGE 中的值为时间戳。
- scan ‘tablename’,{TIMERANGE=>[1325654785652,1436524854295]}
更多操作下次我在给大家出一篇关于 HBase 使用的相关文章进行详细讲解。
HBase 调优
①读性能优化
HBase 服务端优化:
- 读请求是否均衡?
- BlockCache 设置是否合理?
- 数据本地率是不是很低?
- HFile 文件是否太多?
- Compaction 是否影响太大?
HBase 客户端优化:
- scan 缓存是否设置合理?
- get 是否使用批量请求?
- 离线批量读取请求是否设置禁止缓存?
- 请求是否可以显示指定列簇或者列?
HBase 列簇优化:
- 布隆过滤器是否设置?
②写性能优化
HBase 服务端优化:
- Region 是否太少?
- 写入请求是否均衡?
HBase 客户端优化:
- 是否可以使用 Bulkload 方案写入?
- 是否需要写入 WAL?
- WAL 是否需要同步写入?
- Put 是否可以同步批量提交?
- Put 是否可以异步批量提交?
- 写入 Key Value 数据是否太大?
大家可以带着以上问题去对自己的 HBase 逐个优化。
参考资料:
- http://hbase.apache.org/
作者:刘永继
简介:中国科学院大学博士,中国科学院信息工程所,主要从事大数据可视化,虚拟现实与数字孪生技术研究;精通 Java,Python 等主流的技术架构,擅长从架构的角度思考及解决问题。
编辑:陶家龙
征稿:有投稿、寻求报道意向技术人请添加小编微信 gordonlonglong

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】