













如果一张图片可以用一千个单词描述,那么图片中所能被描绘的对象之间便有如此多的细节和关系。我们可以描述狗皮毛的质地,要被追逐的飞盘上的商标,刚刚扔过飞盘的人脸上的表情,等等。
现阶段,包含文本描述及其相应图像的描述的数据集(例如MS-COCO和Flickr30k)已被广泛用于学习对齐的图像和文本表示并建立描述模型。
然而,这些数据集的跨模态关联有限:图像未与其他图像匹配,描述仅与同一张图片的其他描述匹配,存在图像与描述的匹配但未被标记为匹配项,并且没有标签标明何时图像与描述之间是不匹配的。
为了弥补这一评估空白,我们提出了「交叉描述:针对MS-COCO的扩展的模内和模态语义相似性判断」。
纵横交错描述(CxC)数据集使用图像-文本,文本-文本和图像-图像对的语义相似性评级扩展了MS-COCO的开发和测试范围。
评级标准基于「语义文本相似性」,这是一种在短文本对之间广泛存在的语义相关性度量,我们还将其扩展为包括对图像的判断。我们已经发布了CxC的评分以及将CxC与现有MS-COCO数据合并的代码。
创建CxC数据集
CxC数据集扩展了MS-COCO评估拆分,并在模态内和模态之间具有分级的相似性关联。鉴于随机选择的图像和描述匹配的相似性不高,我们提出了一种方法来对项目进行选择,通过人工评级从而产生一些具有较高相似性的新匹配。为了减少所选匹配对用于查找它们的模型的依赖性,我们引入了一种间接采样方案,其中我们使用不同的编码方法对图像和描述进行编码,并计算相同模态项匹配之间的相似度进而生成相似度矩阵。图像使用Graph-RISE嵌入进行编码,而描述则使用两种方法进行编码-基于GloVe嵌入的通用语句编码器(USE)和平均单词袋(BoW)。
由于每个MS-COCO示例都有五个辅助描述,因此我们平均每个辅助描述编码以创建每个示例的单个表征,从而确保所有描述对都可以映射到图像。
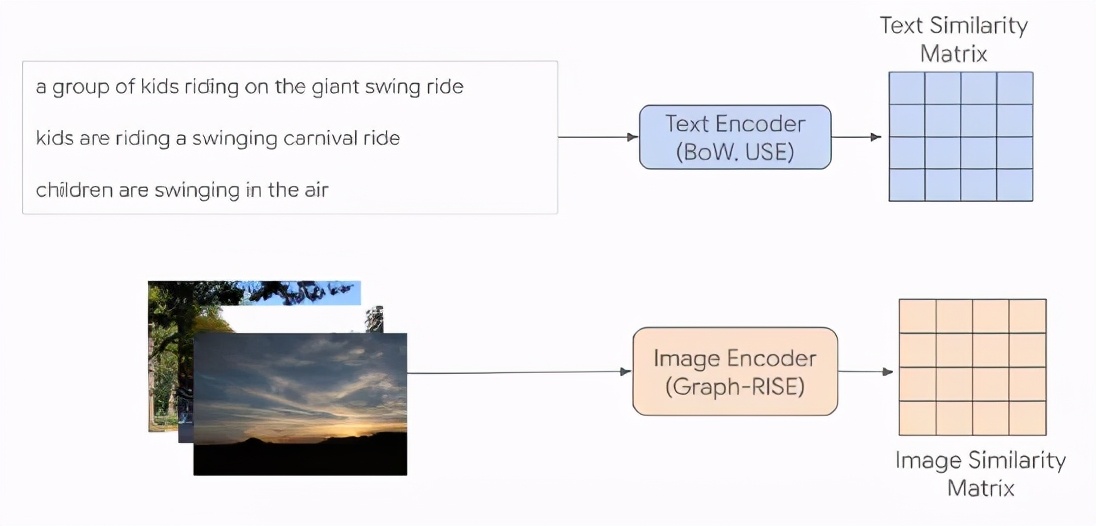
上:使用平均辅助描述编码构造的文本相似度矩阵(每个单元格对应一个相似度分数),每个文本条目对应于单个图像。下:数据集中每个图像的图像相似度矩阵。
我们从文本相似度矩阵中选择两个具有较高计算相似度的描述,然后获取它们的每个图像,从而生成一对新的图像,这些图像在外观上不同,但根据描述的相似。
例如,「一只害羞地向侧面看的狗」和「一只黑狗抬起头来享受微风」具有相当高的模型相似性,因此下图中两只狗的对应图像 可以选择图像相似度等级。此步骤也可以从两个具有较高计算相似度的图像开始,以产生一对新的描述。
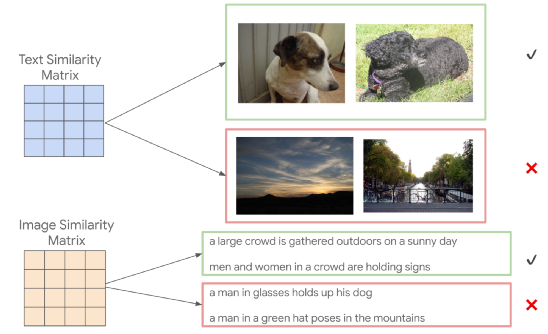
上:根据描述相似度来选择图像匹配。下:根据描图像的相似度来选择描述匹配。
通过使用现有的图像标题对在模态之间进行链接来做到这一点。例如,如果人对一个描述匹配样本ij的评级为高度相似,我们从样本i中选择图像,并从样本j中选择描述,以获得一个新的用于人工评级的模态内匹配。然后,我们使用具有最高相似性的模态内对进行采样,这可以包括一些具有高度相似性的新匹配。






不同相似度的语义图像相似性(SIS)和语义图像文本相似性(SITS)示例,其中5为最相似,0为完全不相似。
评估
MS-COCO的匹配是不完整的,因为有时为一幅图像的描述同样适用于另一幅图像,但这些关联并未记录到数据集中。CxC使用新的正向匹配增强了这些现有的检索任务,并且还支持新的图像-图像检索任务。
通过其相似度的评级判断,CxC还可以测量模型和人工评级之间的相关性。不仅如此,CxC的相关性分数还考虑相似度的相对顺序,其中包括低分项(不匹配项)。
我们进行了一系列实验,以展示CxC评级的效用。为此,我们使用基于BERT的文本编码器和使用EfficientNet-B4作为图像编码器构造了三个双编码器(DE)模型:
1. 文本-文本(DE_T2T)模型,双方使用共享的文本编码器。
2. 使用上述文本和图像编码器的图像文本模型(DE_I2T),且在文本编码器上方有一个用来匹配图像编码器输出的层。
3. 在文本-文本和图像-文本任务的加权组合上训练的多任务模型(DE_I2T + T2T)。
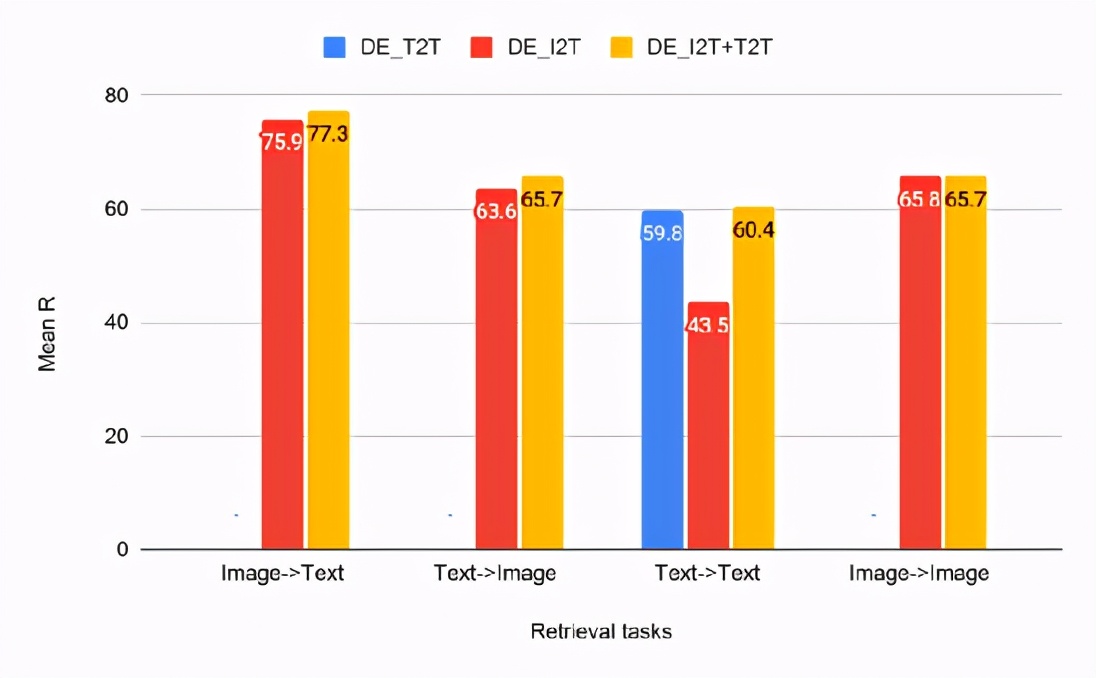
文本-文本(T2T),图像-文本(I2T)和多任务(I2T + T2T)双编码器模型的CxC检索结果
从检索任务的结果可以看出,DE_I2T + T2T(黄色条)在图像文本和文本图像检索任务上的性能优于DE_I2T(红色条)。因此,添加模态内(文本-文本)训练任务有助于提高模态间(图像-文本,文本-图像)性能。
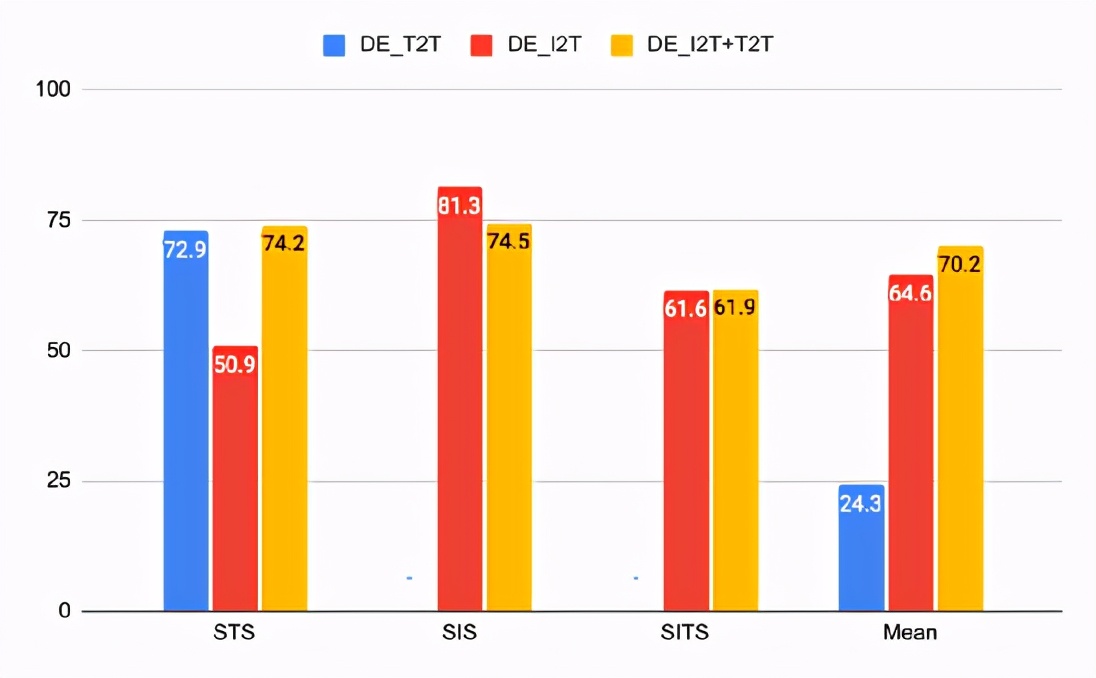
相同模型的CxC相关结果
对于关联任务,DE_I2T在SIS上表现最好,而DE_I2T + T2T在总体上是最好的。相关分数还显示DE_I2T仅在图像上表现良好:它具有最高的SIS,但具有更差的STS。
添加文本-文本损失到DE_I2T训练中(DE_I2T + T2T),可以使整体性能更加均衡。



























