












前言
我最近在优化我的PDF转word的开源小工具,有时候会遇到一个问题,就是如果我的PDF文件比较大,几百兆,如何更快更节省内存的读取它。于是我分析对比了四种常见的读取文件的方式,并使用javaVisualVM工具进行了分析。最后的出的结论是commons-io时间和空间都更加的高效。研究分析依然来自哪位baeldung国外大佬。
下面我会给出几种常见的读取大文件的方式。
读取大文件的四种方式
首先我自己在本地压缩了一个文件夹,大概500M左右。虽然不是很大但是,相对还可以。
方法1:Guava读取
- String path = "G:\\java书籍及工具.zip";
- Files.readLines(new File(path), Charsets.UTF_8);
使用guava读取比较简单,一行代码就搞定了。
下面去jdk的bin目录找到javaVisualVM工具,然后双击运行即可。
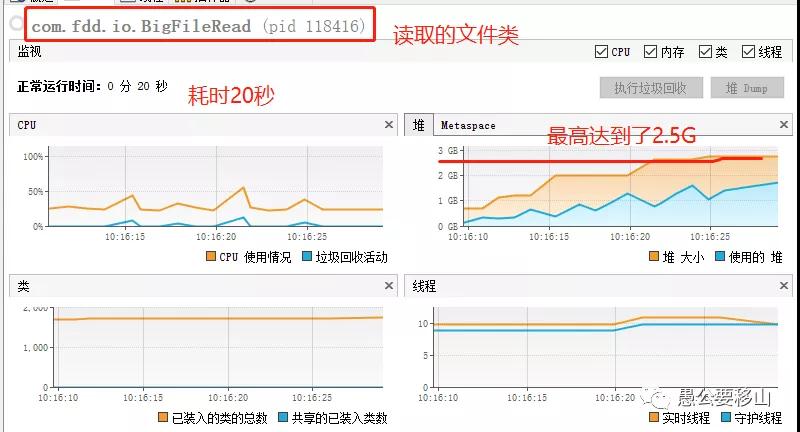
从上图可以看到:
- 时间消耗:20秒
- 堆内存:最高2.5G
- CPU消耗:最高50%
我们一个500M的文件,堆内存最高竟然2.5G,如果我们读取一个2G的文件,可能我们的电脑直接死机了就。
方式2:Apache Commons IO普通方式
- String path = "G:\\java书籍及工具.zip";
- FileUtils.readLines(new File(path), Charsets.UTF_8);
这种方式也比较简单,同样是一行代码。下面运行,也分析一波:
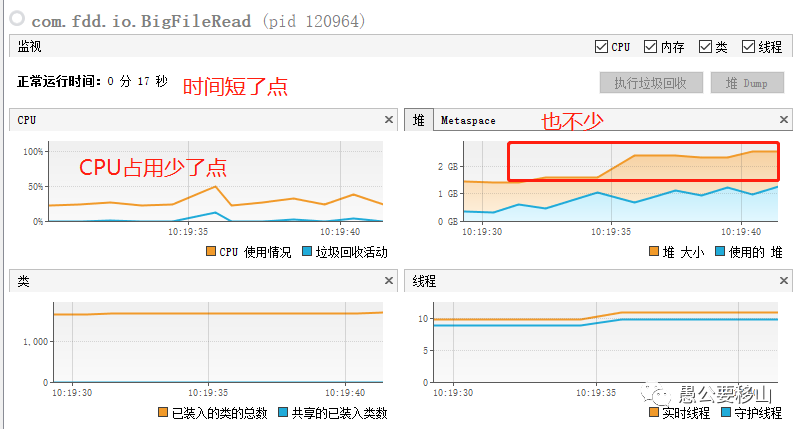
从上图可以看到:
- 时间消耗:17秒
- 堆内存:最高2.5G
- CPU消耗:最高50%,平稳运行25%左右
这种方式和上面那种基本上消耗差不多,肯定不是我想要的。
方式3:java文件流
- FileInputStream inputStream = null;
- Scanner sc = null;
- try {
- inputStream = new FileInputStream(path);
- sc = new Scanner(inputStream, "UTF-8");
- while (sc.hasNextLine()) {
- String line = sc.nextLine();
- //System.out.println(line);
- }
- if (sc.ioException() != null) {
- throw sc.ioException();
- }
- } finally {
- if (inputStream != null) {
- inputStream.close();
- }
- if (sc != null) {
- sc.close();
- }
- }
这种方式其实就是java中最常见的方式,然后我们运行分析一波:
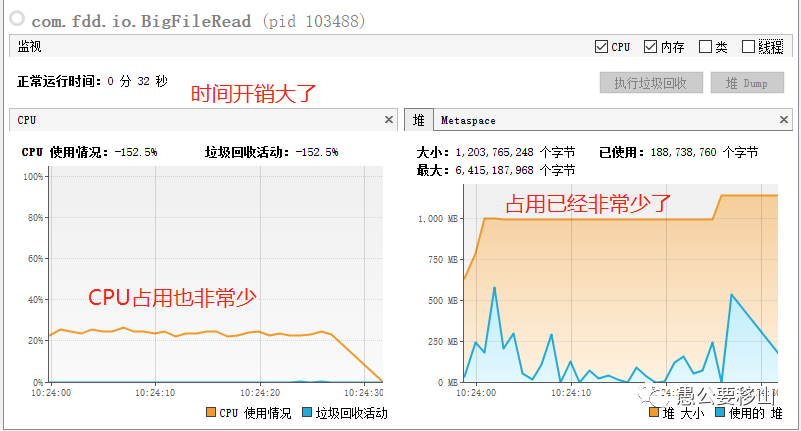
从上图可以看到:
- 时间消耗:32秒,增加了一倍
- 堆内存:最高1G,少了一半
- CPU消耗:平稳运行25%左右
这种方式确实很优秀,但是时间上开销更大。
方式4:Apache Commons IO流
- LineIterator it = FileUtils.lineIterator(new File(path), "UTF-8");
- try {
- while (it.hasNext()) {
- String line = it.nextLine();
- }
- } finally {
- LineIterator.closeQuietly(it);
- }
这种方式代码看起来比较简单,所以直接运行一波吧:
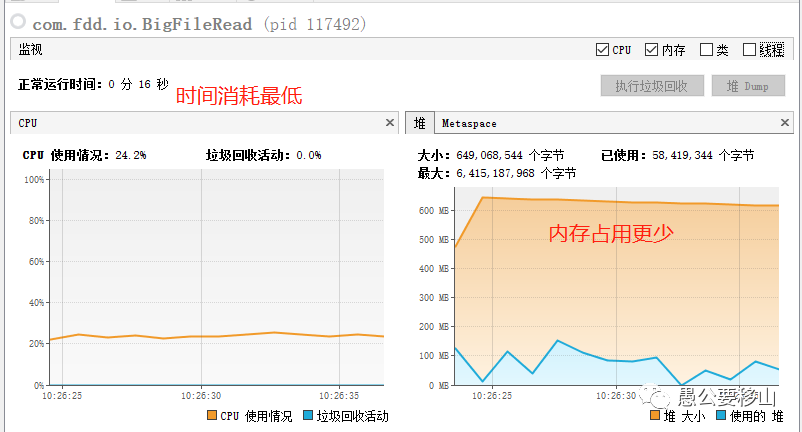
从上图可以看到:
- 时间消耗:16秒,最低
- 堆内存:最高650M,少了一半
- CPU消耗:平稳运行25%左右
OK,就它了,牛。
结论
通过以上的分析,我们可以得出一个结论,如果我们想要读取一个大文件,选择了错误的方式,就有可能极大地占用我的内存和CPU,当文件特别大时,会造成意向不到的问题。
因此为了去解决这样的问题,有四种常见的读取大文件的方式。通过分析对比,发现,Apache Commons IO流是最高效的一种方式。
本文转载自微信公众号「愚公要移山」,可以通过以下二维码关注。转载本文请联系愚公要移山公众号。

















