












本文转载自微信公众号「木鸟杂记」,作者穆尼奥 。转载本文请联系木鸟杂记公众号。
早对 LevelDB 有所耳闻,这次心血来潮结合一些资料粗略过了遍代码,果然名不虚传。如果你对存储感兴趣、如果你想优雅使用 C++、如果你想学习如何架构项目,都推荐来观摩一下。更何况作者是 Sanjay Ghemawat 和 Jeff Dean 呢。
看过一遍如果不输出点什么,以我的记性,定会很快抛诸脑后。便想写点东西说说 LevelDB 之妙,但又不想走寻常路:从架构概览说起,以模块分析做合。读代码的这些天,一直在盘算从哪下笔比较好。在将将读完之时,印象最深的反而是 LevelDB 的各种精妙的数据结构:贴合场景、从头构建、剪裁得当、代码精到。不妨, LevelDB 系列就从这些边边角角的小构件开始吧。
本系列主要想分享 LevelDB 中用到的三个工程中常用的经典数据结构,分别是用以快速读写 memtable 的 Skip List、用以快速筛选 sstable 的 Bloom Filter 和用以部分缓存 sstable 的 LRUCache 。这是第三篇,LRUCache。
引子
LRU 是工程中多见的一个数据结构,常用于缓存场景。近年来,LRU 也是面试中一道炙手可热的考题,一来工程用的多,二来代码量较少,三来涉及的数据结构也很典型。LeetCode 中有一道相应的题目:lru-cache。相对实际场景,题目进行了简化:本质上要求维护一个按访问时间有序的 kv 集合,且 kv 皆是整数。经典解法是使用一个哈希表(unordered_map)和一个双向链表,哈希表解决索引问题,双向链表维护访问顺序。这是我当时的一个解法,特点是用了两个辅助函数,并且可以返回节点自身,以支持链式调用,从而简化了代码。
说回 LevelDB 源码,作为一个工业品,它使用 的 LRUCache 又做了哪些优化和变动呢?下面让我们一块来拆解下 LevelDB 中使用的 LRUCache,看看有什么不同。
本文首先明确 LRUCache 的使用方法,然后总览分析 LRUCache 的实现思路,最后详述相关数据结构的实现细节。
缓存使用
在分析 LRUCache 的实现之前,首先了解下 LRUCache 的使用方法,以明确 LRUCache 要解决的问题。以此为基础,我们才能了解为什么要这么实现,甚至更进一步,探讨有没有更好的实现。
首先来看下 LevelDB 的导出接口 Cache:
- // 插入一个键值对(key,value)到缓存(cache)中,
- // 并从缓存总容量中减去该键值对所占额度(charge)
- //
- // 返回指向该键值对的句柄(handle),调用者在用完句柄后,
- // 需要调用 this->Release(handle) 进行释放
- //
- // 在键值对不再被使用时,键值对会被传入的 deleter 参数
- // 释放
- virtual Handle* Insert(const Slice& key, void* value, size_t charge,
- void (*deleter)(const Slice& key, void* value)) = 0;
- // 如果缓存中没有相应键(key),则返回 nullptr
- //
- // 否则返回指向对应键值对的句柄(Handle)。调用者用完句柄后,
- // 要记得调用 this->Release(handle) 进行释放
- virtual Handle* Lookup(const Slice& key) = 0;
- // 释放 Insert/Lookup 函数返回的句柄
- // 要求:该句柄没有被释放过,即不能多次释放
- // 要求:该句柄必须是同一个实例返回的
- virtual void Release(Handle* handle) = 0;
- // 获取句柄中的值,类型为 void*(表示任意用户自定义类型)
- // 要求:该句柄没有被释放
- // 要求:该句柄必须由同一实例所返回
- virtual void* Value(Handle* handle) = 0;
- // 如果缓存中包含给定键所指向的条目,则删除之。
- // 需要注意的是,只有在所有持有该条目句柄都释放时,该条目所占空间才会真正被释放
- virtual void Erase(const Slice& key) = 0;
- // 返回一个自增的数值 id。当一个缓存实例由多个客户端共享时,
- // 为了避免多个客户端的键冲突,每个客户端可能想获取一个独有
- // 的 id,并将其作为键的前缀。类似于给每个客户端一个单独的命名空间。
- virtual uint64_t NewId() = 0;
- // 驱逐全部没有被使用的数据条目
- // 内存吃紧型的应用可能想利用此接口定期释放内存。
- // 基类中的 Prune 默认实现为空,但强烈建议所有子类自行实现。
- // 将来的版本可能会增加一个默认实现。
- virtual void Prune() {}
- // 返回当前缓存中所有数据条目所占容量总和的一个预估
- virtual size_t TotalCharge() const = 0;
依据上述接口,可捋出 LevelDB 缓存相关需求:
- 多线程支持
- 性能需求
- 数据条目的生命周期管理
用状态机来表示 Cache 中的 Entry 的生命周期如下:
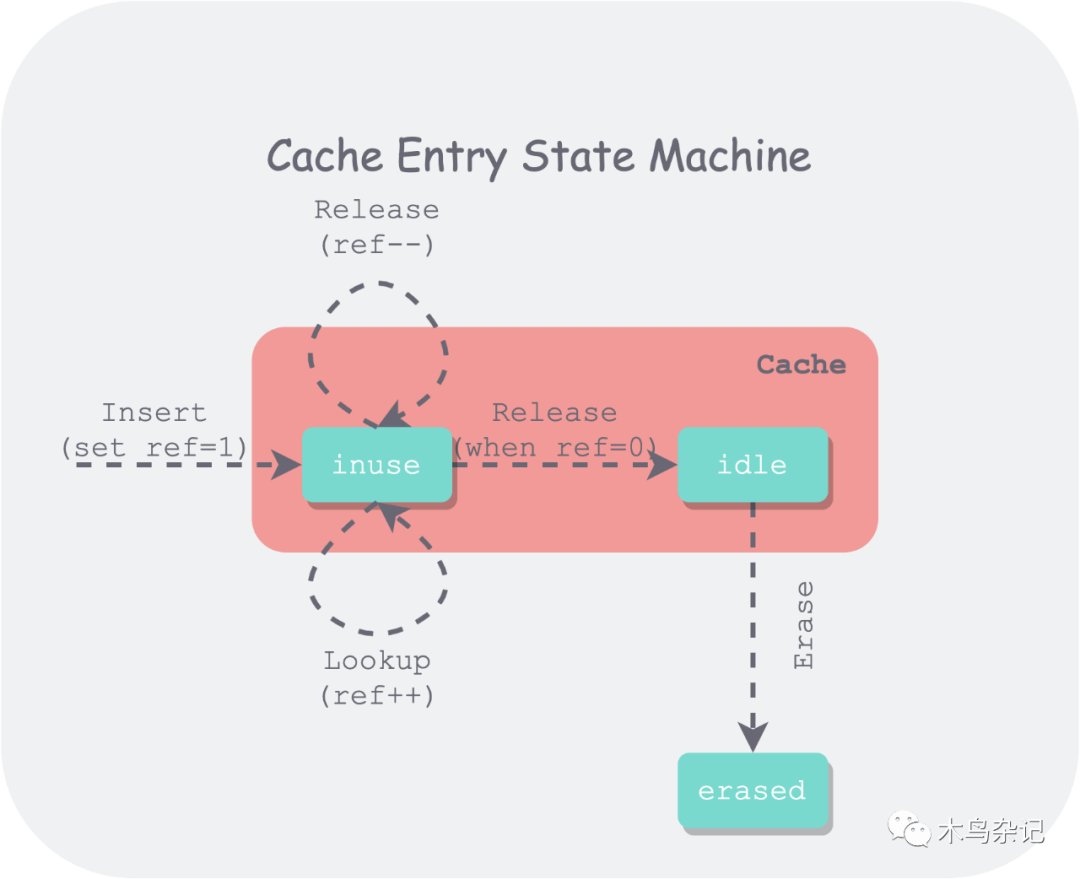
leveldb entry lifecycle
可以看出该状态机要比 LeetCode 中复杂一些,首先增加了多线程的引用,其次需要区分被引用(inuse) 和空闲(idle) 状态。
多个线程可以通过 Insert、Lookup 对同一个条目进行插入和引用,因此缓存需要维护每个条目(entry)的引用数量。只有引用数量为 0 的条目才会进入一个待驱逐(idle)的状态,将所有待驱逐的条目按 LRU 顺序排序,在用量超过容量时,将依据上述顺序对最久没使用过的条目进行驱逐。
此外,需要进行线程间同步和互斥,以保证 Cache 是线程安全的,最简单的方法是整个 Cache 使用一把锁,但这样多线程间争抢比较严重,会有性能问题。
接下来看看 LevelDB 的 LRUCache 是如何解决这些问题的。
思路总览
总体上来说,LevelDB 的 LRUCache 也使用了哈希表和双向链表的实现思路,但又有些不同:
使用数组+链表处理冲突定制了一个极简哈希表,便于控制分配以及伸缩。
多线程支持。了提高并发,引入了分片;为了区分是否被客户端引用,引入两个双向链表。
整个代码相当简洁,思想也比较直观。
定制哈希表
LevelDB 中哈希表保持桶的个数为 2 的次幂,从而使用位运算来通过键的哈希值快速计算出桶位置。通过 key 的哈希值来获取桶的句柄方法如下:
LRUHandle** ptr = &list_[hash & (length_ - 1)];
每次调整时,在扩张时将桶数量增加一倍,在缩减时将桶数量减少一倍,并需要对所有数据条目进行重新分桶。
两个链表
LevelDB 使用两个双向链表保存数据,缓存中的所有数据要么在一个链表中,要么在另一个链表中,但不可能同时存在于两个链表中。这两个链表分别是:
- in-use 链表。所有正在被客户端使用的数据条目(an kv item)都存在该链表中,该链表是无序的,因为在容量不够时,此链表中的条目是一定不能够被驱逐的,因此也并不需要维持一个驱逐顺序。
- lru 链表。所有已经不再为客户端使用的条目都放在 lru 链表中,该链表按最近使用时间有序,当容量不够用时,会驱逐此链表中最久没有被使用的条目。
另外值得一提的是,哈希表中用来处理冲突的链表节点与双向链表中的节点使用的是同一个数据结构(LRUHandle),但在串起来时,用的是 LRUHandle 中不同指针字段。
数据结构
LRUCache 实现主要涉及到了四个数据结构:LRUHandle、HandleTable、LRUCache 和 ShardedLRUCache。前三者组织形式如下:
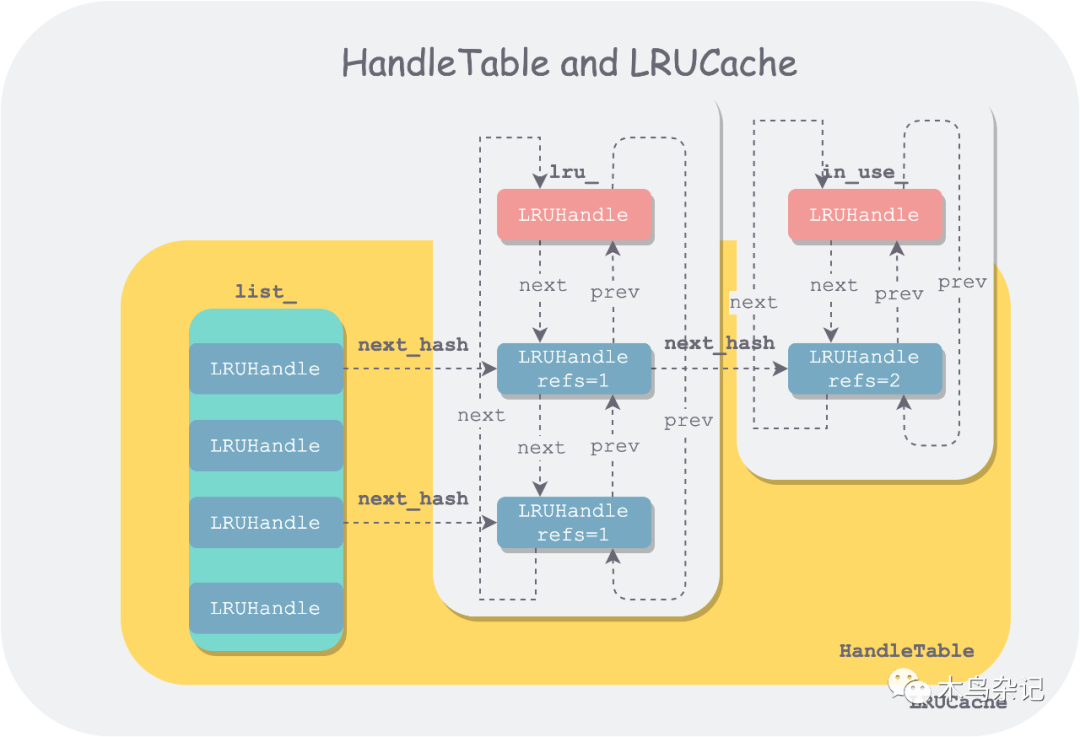
lru cache architecture
ShardedLRUCache 由一组 LRUCache 组成,每个 LRUCache 作为一个分片,同时是一个加锁的粒度,他们都实现了 Cache 接口。下图画了 4 个分片,代码中是 16 个。
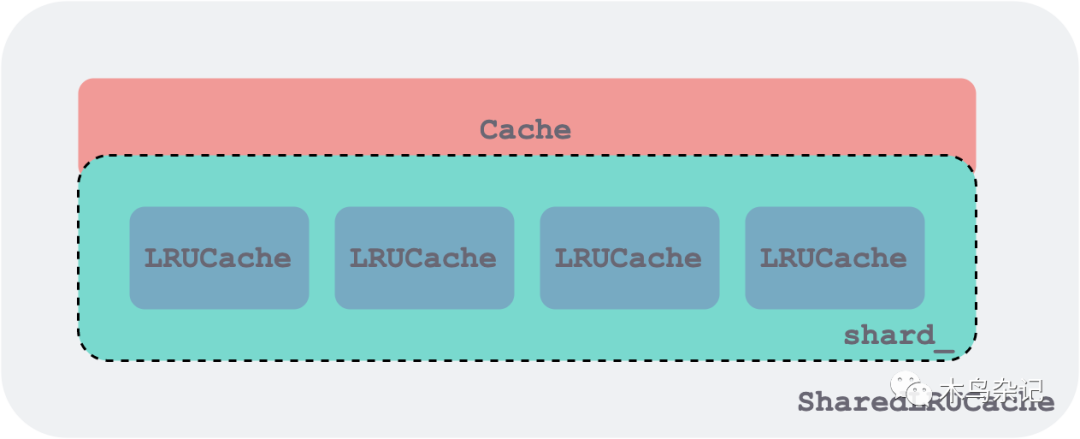
shared lru cache
LRUHandle——基本数据单元
LRUHandle 是双向链表和哈希表的基本构成单位。其结构如下:
- struct LRUHandle {
- void* value;
- void (*deleter)(const Slice&, void* value); // 释放 key,value 空间的用户回调
- LRUHandle* next_hash; // 用于 hashtable 中链表处理冲突
- LRUHandle* next; // 用于双向链表中维护 LRU 顺序
- LRUHandle* prev;
- size_t charge; // TODO(opt): Only allow uint32_t?
- size_t key_length;
- bool in_cache; // 该 handle 是否在 cache table 中
- uint32_t refs; // 该 handle 被引用的次数
- uint32_t hash; // key 的 hash 值,用于确定分片和快速比较
- char key_data[1]; // key 的起始
- Slice key() const {
- // next_ is only equal to this if the LRU handle is the list head of an
- // empty list. List heads never have meaningful keys.
- assert(next != this);
- return Slice(key_data, key_length);
- }
- };
特别要注意的是,LRUHandle 中的 refs 和我们前一小节中所画图中的状态机中 ref 含义并不一样。LevelDB 实现时,把 Cache 的引用也算一个引用。因此在 Insert 时,会令 refs = 2,一个为客户端的引用,一个为 LRUCache 的引用。refs==1 && in_cache即说明该数据条目只被 LRUCache 引用了。
这个设计开始看着有点别扭,但是想了想反而觉得很贴切自然。
HandleTable——哈希表索引
使用位操作来对 key 进行路由,使用链表来处理冲突,实现比较直接。链表中节点是无序的,因此每次查找都需要全链表遍历。
其中值得一说的是 FindPointer 这个查找辅助函数,该函数用了双重指针,在增删节点时比较简洁,开始时可能不太好理解。在通常实现中,增删节点时,我们会找其前驱节点。但其实增删只用到了前驱节点中的 next_hash 指针:
- 删除:会修改 next_hash 的指向。
- 新增:首先读取 next_hash,找到下一个链节,将其链到待插入节点后边,然后修改前驱节点 next_hash 指向。
由于本质上只涉及到前驱节点 next_hash 指针的读写,因此返回前驱节点 next_hash 指针的指针是一个更简洁的做法:
- LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
- LRUHandle** ptr = &list_[hash & (length_ - 1)];
- while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) {
- ptr = &(*ptr)->next_hash;
- }
- return ptr;
- }
该函数首先使用 hash 值通过位运算,定位到某个桶。然后在该桶中逐个遍历节点:
- 如果节点的 hash 或者 key 匹配上,则返回该节点的双重指针(前驱节点的 next_hash 指针的指针)。
- 否则,返回该链表的最后一个节点的双重指针(边界情况,如果是空链表,最后一个节点便是桶头)。
由于返回的是其前驱节点 next_hash 的地址,因此在删除时,只需将该 next_hash 改为待删除节点后继节点地址,然后返回待删除节点即可。
- LRUHandle* Remove(const Slice& key, uint32_t hash) {
- LRUHandle** ptr = FindPointer(key, hash);
- LRUHandle* result = *ptr;
- if (result != nullptr) {
- *ptr = result->next_hash;
- --elems_;
- }
- return result;
- }
在插入时,也是利用 FindPointer 函数找到待插入桶的链表尾部节点 next_hash 指针的指针,对于边界条件空桶来说,会找到桶的空头结点。之后需要判断是新插入还是替换,如果替换,则把被替换的旧节点返回,下面是插入新节点示意图:
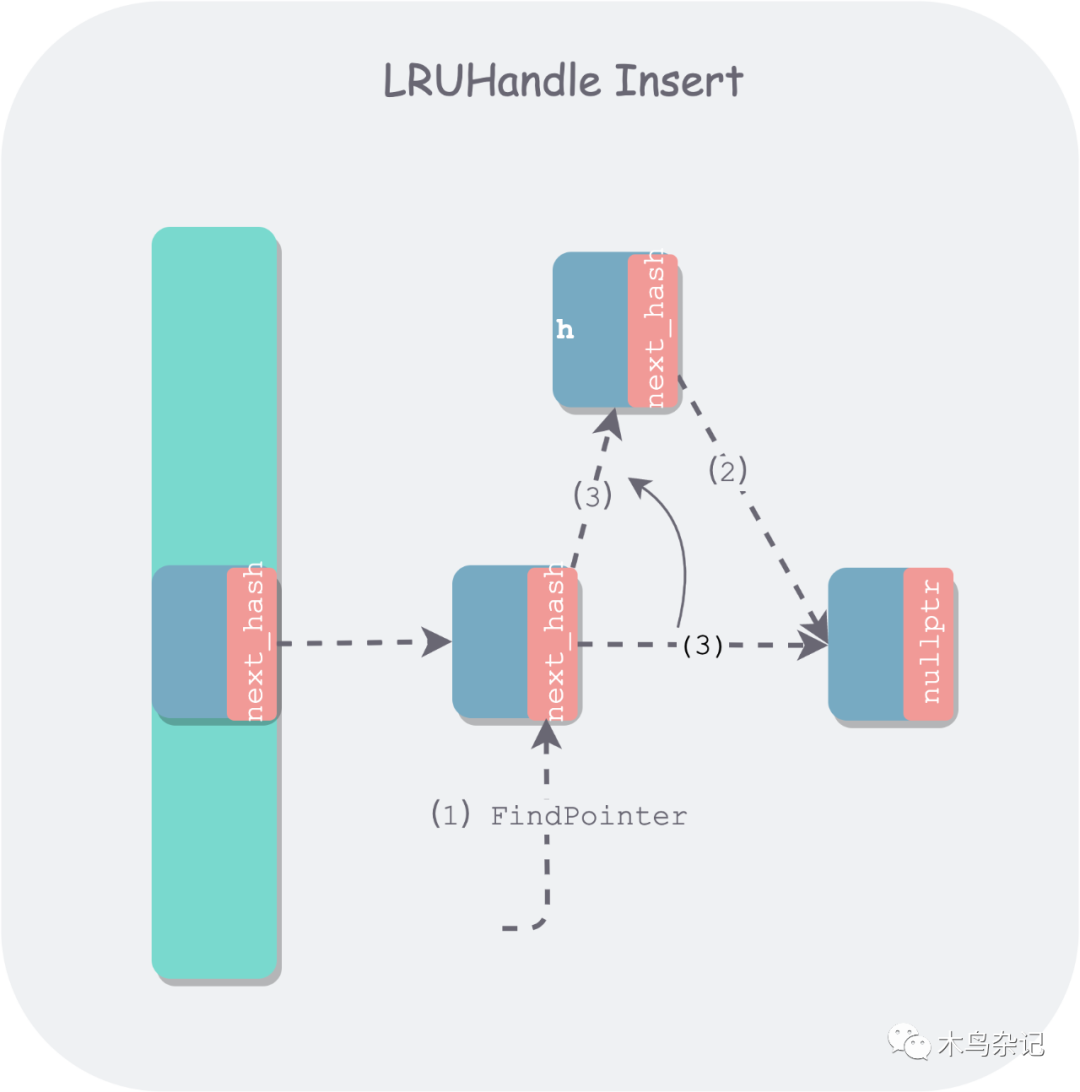
leveldb lru table insert
如果是新插入节点,节点总数会变多,如果节点总数多到大于某个阈值后,为了保持哈希表的性能,就需要进行 resize,以增加桶的个数,同时将所有节点进行重新分桶。LevelDB 选定的阈值是 length_ —— 桶的个数。
resize 的操作比较重,因为需要对所有节点进行重新分桶,而为了保证线程安全,需要加锁,但这会使得哈希表一段时间不能提供服务。当然通过分片已经减小了单个分片中节点的数量,但如果分片不均匀,仍然会比较重。这里有提到一种渐进式的迁移方法:Dynamic-sized NonBlocking Hash table,可以将迁移时间进行均摊,有点类似于 Go GC 的演化。
LRUCache—— 哈希表索引+双向环形链表
将之前分析过的导出接口 Cache 所包含的函数去掉后,LRUCache 类简化如下:
- class LRUCache {
- public:
- LRUCache();
- ~LRUCache();
- // 从构造函数分离出此参数的设置方法,可以让调用者在使用时进行灵活的调整
- void SetCapacity(size_t capacity) { capacity_ = capacity; }
- private:
- // 辅助函数:将链节 e 从双向链表中摘除
- void LRU_Remove(LRUHandle* e);
- // 辅助函数:将链节 e 追加到链表头
- void LRU_Append(LRUHandle* list, LRUHandle* e);
- // 辅助函数:增加链节 e 的引用
- void Ref(LRUHandle* e);
- // 辅助函数:减少链节 e 的引用
- void Unref(LRUHandle* e);
- // 辅助函数:从缓存中删除单个链节 e
- bool FinishErase(LRUHandle* e) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
- // 在使用 LRUCache 前必须先初始化此值
- size_t capacity_;
- // mutex_ 用以保证此后的字段的线程安全
- mutable port::Mutex mutex_;
- size_t usage_ GUARDED_BY(mutex_);
- // lru 双向链表的空表头
- // lru.prev 指向最新的条目,lru.next 指向最老的条目
- // 此链表中所有条目都满足 refs==1 和 in_cache==true
- // 表示所有条目只被缓存引用,而没有客户端在使用
- LRUHandle lru_ GUARDED_BY(mutex_);
- // in-use 双向链表的空表头
- // 保存所有仍然被客户端引用的条目
- // 由于在被客户端引用的同时还被缓存引用,
- // 肯定有 refs >= 2 和 in_cache==true.
- LRUHandle in_use_ GUARDED_BY(mutex_);
- // 所有条目的哈希表索引
- HandleTable table_ GUARDED_BY(mutex_);
- };
可以看出该实现有以下特点:
- 使用两个双向链表将整个缓存分成两个不相交的集合:被客户端引用的 in-use 链表,和不被任何客户端引用的 lru_ 链表。
- 每个双向链表使用了一个空的头指针,以便于处理边界情况。并且表头的 prev 指针指向最新的条目,next 指针指向最老的条目,从而形成了一个双向环形链表。
- 使用 usage_ 表示缓存当前已用量,用 capacity_ 表示该缓存总量。
- 抽象出了几个基本操作:LRU_Remove、LRU_Append、Ref、Unref 作为辅助函数进行复用。
- 每个 LRUCache 由一把锁 mutex_ 守护。
了解了所有字段,以及之前的状态机,每个函数的实现应该比较容易理解。下面不再一一罗列所有函数的实现,仅挑比较复杂的 Insert 进行注释说明:
- Cache::Handle* LRUCache::Insert(const Slice& key, uint32_t hash, void* value,
- size_t charge,
- void (*deleter)(const Slice& key,
- void* value)) {
- MutexLock l(&mutex_);
- // 构建数据条目句柄
- LRUHandle* e =
- reinterpret_cast<LRUHandle*>(malloc(sizeof(LRUHandle) - 1 + key.size()));
- e->value = value;
- e->deleter = deleter;
- e->charge = charge;
- e->key_length = key.size();
- e->hash = hash;
- e->in_cache = false;
- e->refs = 1; // 客户端引用
- std::memcpy(e->key_data, key.data(), key.size());
- if (capacity_ > 0) {
- e->refs++; // 缓存本身引用
- e->in_cache = true;
- LRU_Append(&in_use_, e);
- usage_ += charge;
- FinishErase(table_.Insert(e)); // 如果是替换,要删除原来数据
- } else { // capacity_==0 时表示关闭缓存,不进行任何缓存
- // next 会在 key() 函数中被 assert 测试,因此要初始化一下
- e->next = nullptr;
- }
- // 当超数据条目超出容量时,根据 LRU 策略将不被客户端引用的数据条目驱逐出内存
- while (usage_ > capacity_ && lru_.next != &lru_) {
- LRUHandle* old = lru_.next;
- assert(old->refs == 1);
- bool erased = FinishErase(table_.Remove(old->key(), old->hash));
- if (!erased) { // to avoid unused variable when compiled NDEBUG
- assert(erased);
- }
- }
- return reinterpret_cast<Cache::Handle*>(e);
- }
ShardedLRUCache——分片 LRUCache
引入 SharedLRUCache 的目的在于减小加锁的粒度,提高读写并行度。策略比较简洁—— 利用 key 哈希值的前 kNumShardBits = 4 个 bit 作为分片路由,可以支持 kNumShards = 1 << kNumShardBits 16 个分片。通过 key 的哈希值计算分片索引的函数如下:
- static uint32_t Shard(uint32_t hash) { return hash >> (32 - kNumShardBits); }
由于 LRUCache 和 ShardedLRUCache 都实现了 Cache 接口,因此 ShardedLRUCache 只需将所有 Cache 接口操作路由到对应 Shard 即可,总体来说 ShardedLRUCache 没有太多逻辑,更像一个 Wrapper,这里不再赘述。
参考
LevelDB 缓存代码:https://github.com/google/leveldb/blob/master/util/cache.cc
LevelDB handbook 缓存系统:https://leveldb-handbook.readthedocs.io/zh/latest/cache.html#dynamic-sized-nonblocking-hash-table【编辑推荐】
原文链接:https://mp.weixin.qq.com/s/zcvgWO4cIxfphfE7I41GYA

















