













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
5月4日,谷歌团队在arXiv上提交了一篇论文“MLP-Mixer: An all-MLP Architecture for Vision”[1],引起了广大计算机视觉的研究人员的热烈讨论:MLP究竟有多大的潜力?
5月5日,清华大学图形学实验室Jittor团队在arXiv上提交论文“Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks”[2], 提出了一种新的注意机制,称之为“External Attention”。
基于两个外部的、小的、可学习的和共享的存储器,只用两个级联的线性层和归一化层就可以取代了现有流行的学习架构中的“Self-attention”,揭示了线性层和注意力机制之间的关系。
同日,清华大学软件学院丁贵广团队在arXiv上提交了论文“RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition”[3],展示了结合重参数化技术的MLP也取得了非常不错的效果。
5月6日牛津大学的学者提交了一篇名为”Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”的论文[4],也提出了Transformer中的attention是不必要的,仅仅使用Feed forward就可以在ImageNet上实现非常高的结果。
从Self-attention到External-attention
自注意力机制在自然语言处理和计算机视觉领域中起到了越来越重要的作用。对于输入的Nxd维空间的特征向量F,自注意力机制使用基于自身线性变换的Query,Key和Value特征去计算自身样本内的注意力,并据此更新特征:
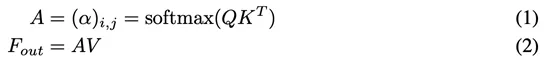
由于QKV是F的线性变换,简单起见,我们可以将自注意力计算公式简记如下:

这是F对F的注意力,也就是所谓的Self-attention。如果希望注意力机制可以考虑到来自其他样本的影响,那么就需要一个所有样本共享的特征。为此,我们引入一个外部的Sxd维空间的记忆单元M,来刻画所有样本最本质的特征,并用M来表示输入特征。
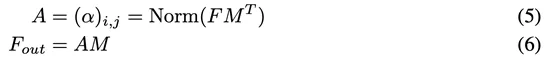
我们称这种新的注意力机制为External-attention。我们可以发现,公式(5)(6)中的计算主要是矩阵乘法,就是常见的线性变换,一个自注意力机制就这样被两层线性层和归一化层代替了。我们还使用了之前工作[5]中提出的Norm方式来避免某一个特征向量的过大而引起的注意力失效问题。
为了增强External-attention的表达能力,与自注意力机制类似,我们采用两个不同的记忆单元。

下图形象地展示了External-attention与Self-attention的区别。
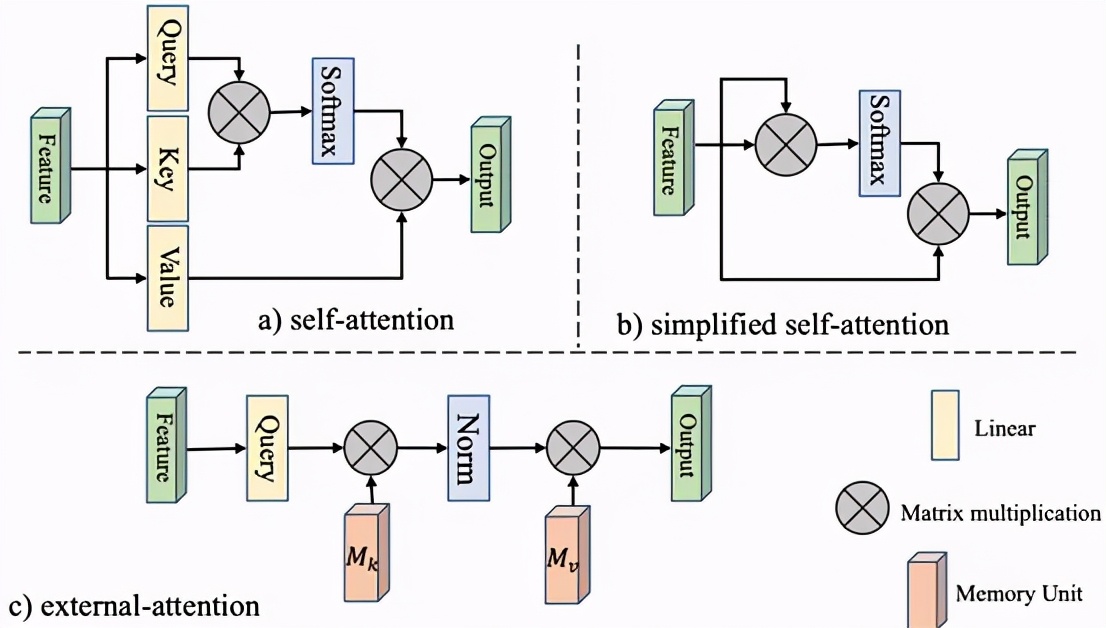
△图1 Self Attention和External Attention的区别
为什么两层线性层可以超越Self-attention?
自注意力机制一个明显的缺陷在于计算量非常大,存在一定的计算冗余。通过控制记忆单元的大小,External-attention可以轻松实现线性的复杂度。
其次,自注意力机制仅利用了自身样本内的信息,忽略了不同样本之间的潜在的联系,而这种联系在计算机视觉中是有意义的。打个比方,对于语义分割任务,不同样本中的相同类别的物体应该具有相似的特征。
External-attention通过引入两个外部记忆单元,隐式地学习了整个数据集的特征。这种思想同样在稀疏编码和字典学习中得到了应用。
计图团队在Pascal VOC 的Test set上,可视化了注意力图以及分割的结果,如图2所示,可以发现,使用两层线性层的External attention 的注意力图是合理的。
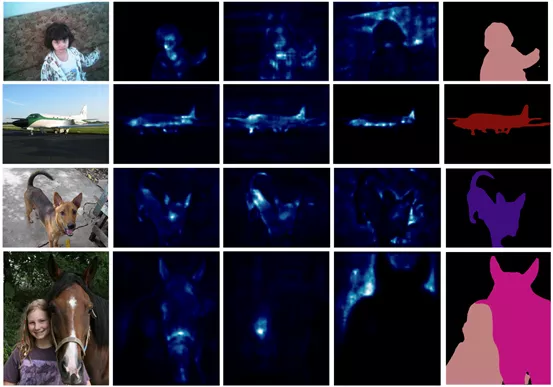
△图2 注意力图以及分割的结果的可视化
从实验看External Attention的效果
为了证明方法的通用性,我们在图像分类、分割、生成以及点云的分类和分割上均做了实验,证明了方法的有效性,External-attention在大大减少计算量的同时,可以取得与目前最先进方法相当,甚至更好的结果。
1、图像分类

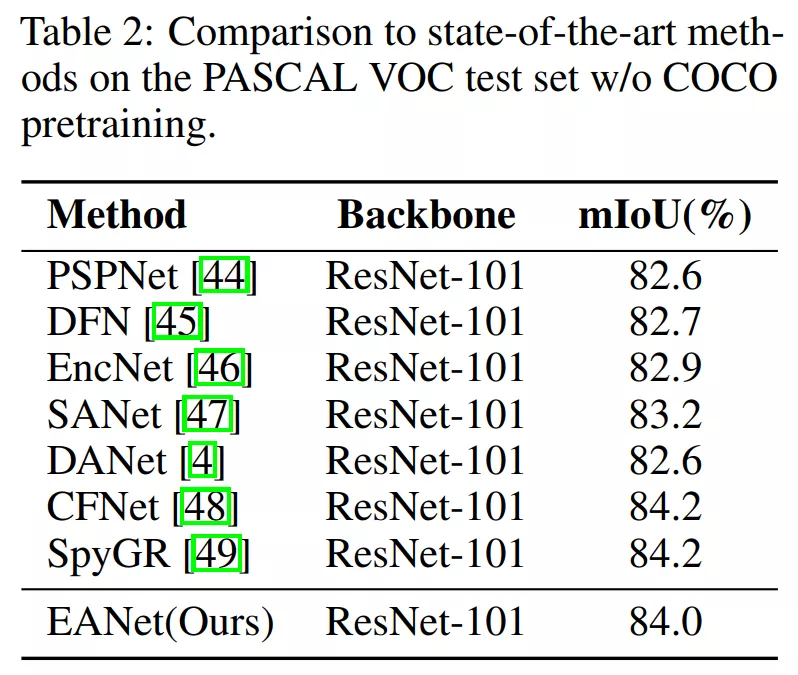
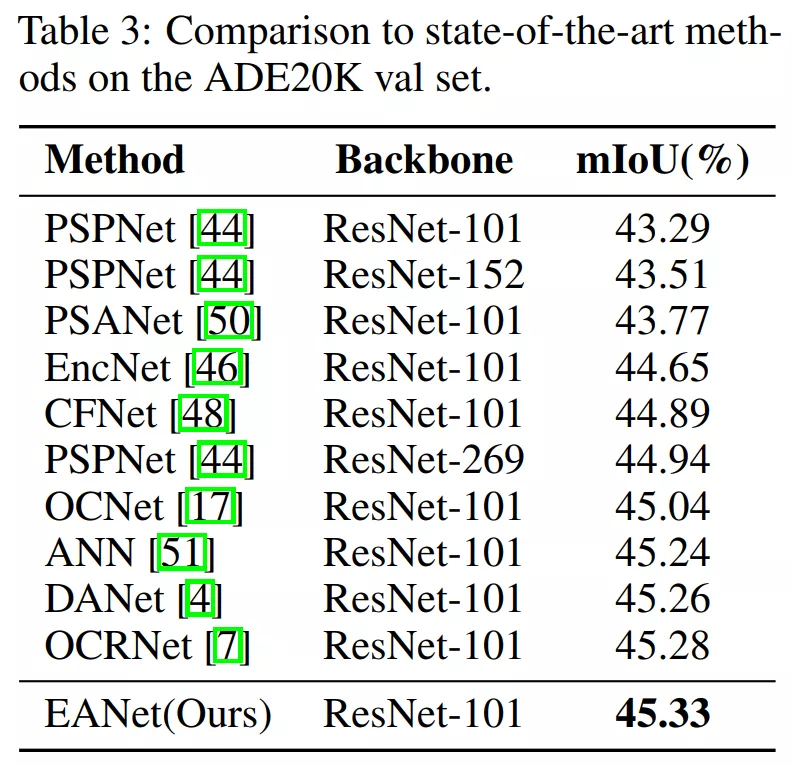
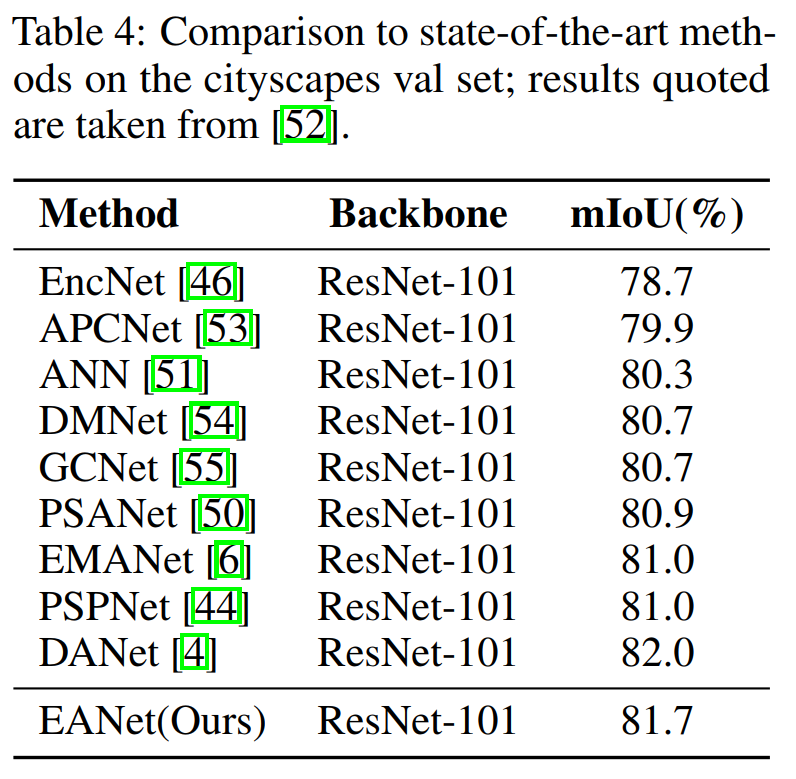
2、图像语义分割(三个数据集上)
3、图像生成
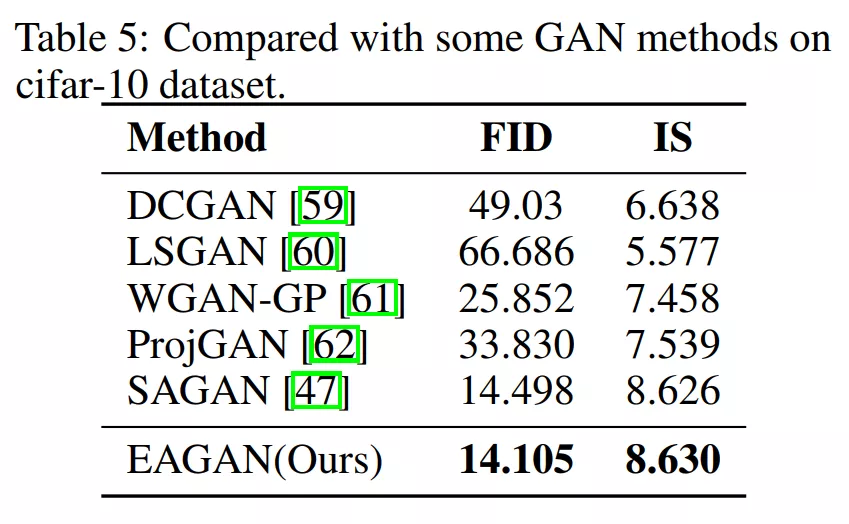
4、点云分类
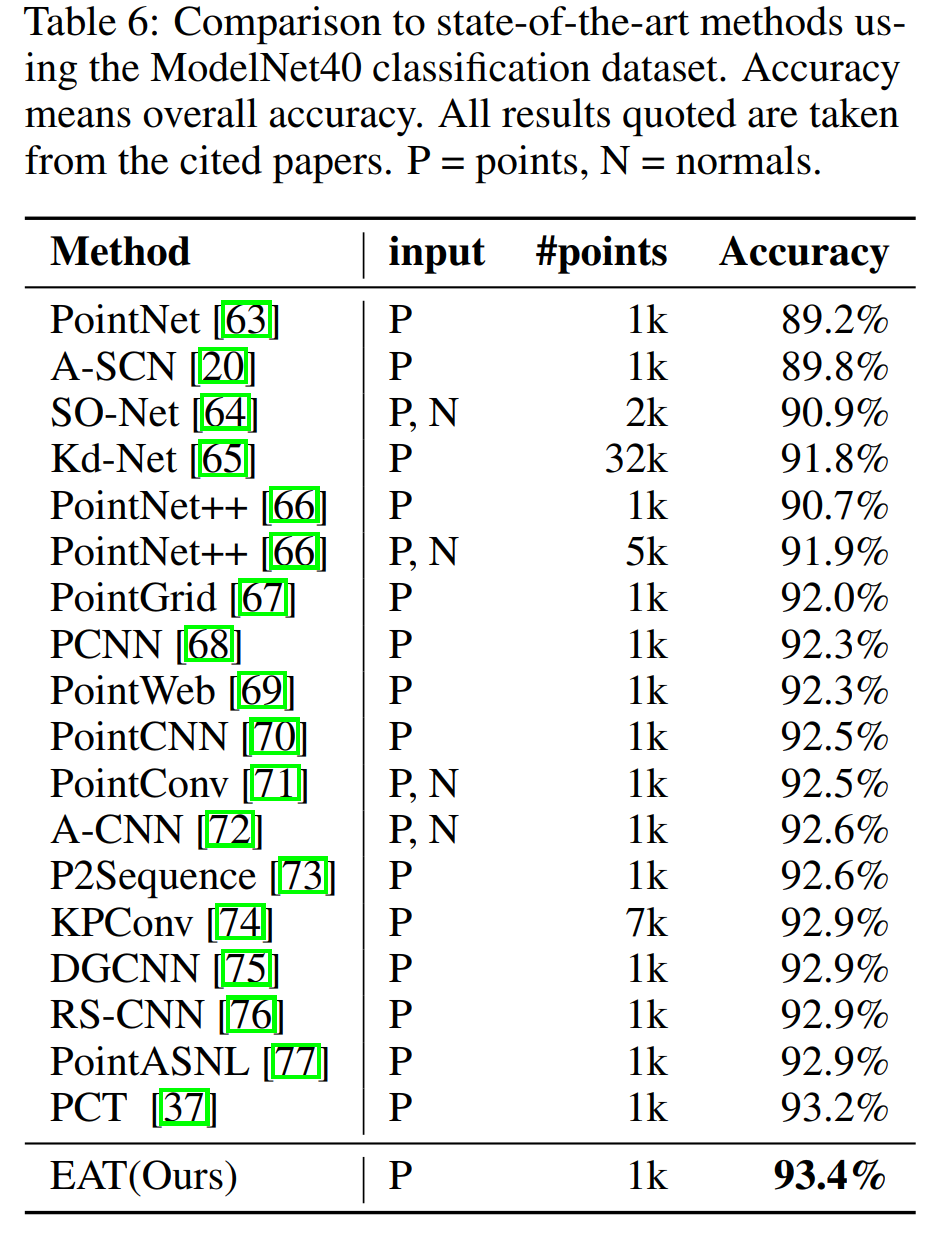
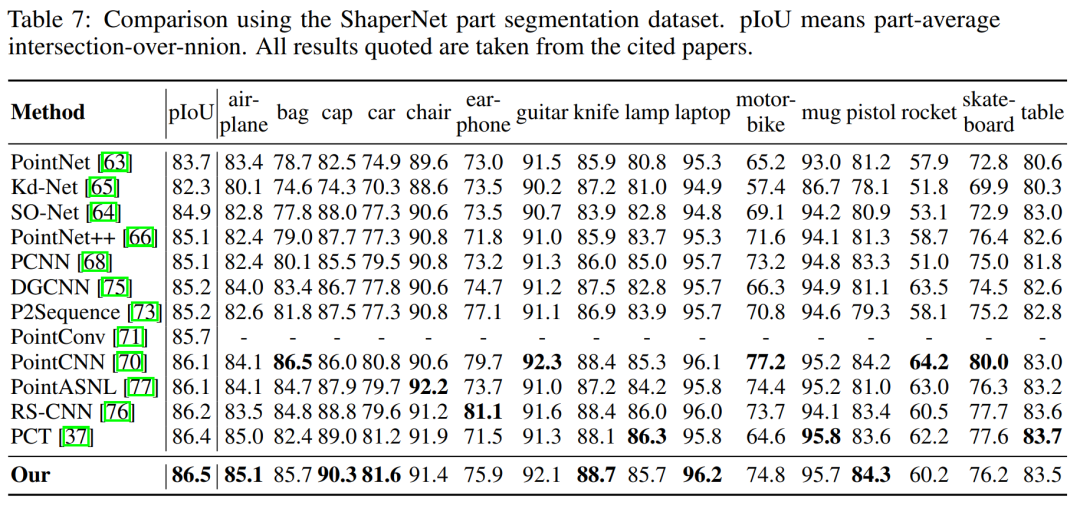
5、点云分割
External Attention VS MLP-Mixer
谷歌的工作提出了一种小巧且好用的Mixer-Layer,然后用极其丰富的实验,证明了仅仅通过简单的图像分块和线性层的堆叠就可以实现非常好的性能,开拓了人们的想象。
清华的External Attention则揭示了线性层和注意力机制之间的内在关联,证明了线性变换其实是一种特殊形式的注意力实现,如下公式所示:
Attention(x)=Linear(Norm(Linear(x)))
计图团队的工作和谷歌团队的工作都证明了线性层的有效性。值得注意的是,如果将External-attention不断级联堆叠起来,也是MLP的形式,就可以实现一个纯MLP的网络结构,但External-attention使用不同的归一化层,其更符合注意力机制。
这与谷歌团队的工作有异曲同工之妙。
清华的External Attention的部分计图代码已经在Github开源。
后续将尽快开源全部计图代码。
External Attention的部分计图代码:
https://github.com/MenghaoGuo/-EANet





























