












遵循最佳做法的代码库在当今世界能得到高度评价。如果您的项目是开源的,这会是一个吸引优秀开发人员的方式。作为开发人员,您想要编写高效且优化的代码:
占用尽可能小的内存、执行地更快、看起来整洁、文档正确、遵循标准风格指南,并且易于被新开发者理解。
这里讨论的实践可能有助于您为开源组织做出贡献,向在线评审(Online Judge)提交解决方案,使用机器学习处理大量数据处理问题,或开发自己的项目。

实践 1:尽量不要对内存置之不理
Python 内存管理器内部确保对这个专用堆的管理。当您创建对象时,Python 虚拟机处理所需的内存,并决定将其放置在内存布局中的特定位置。与 C/C ++ 不同,Python 解释器会进行内存管理,用户无法自己控制。Python 中的内存管理涉及包含所有Python对象和数据结构的专用堆。一个简单的 Python 程序在内存上可能不会引起很多问题,但在高内存消耗的项目中内存使用变得至关重要。从一开始开发大项目时,合理使用内存是明智的。
然而,如何更好地了解事情的工作原理和不同的方法来做事情,可以帮助您最大限度地减少程序的内存使用量。
• 使用生成器来计算大量的结果
生成器可进行惰性计算。您可以通过遍历来使用它们:显示地使用 “for” 或者隐式地将其传递给任何方法或构造。
生成器可以返回多个项,就像返回一个列表 —— 不是一次返回所有,而是一个接一个地返回。生成器会暂停,直到下一个项被请求。在 这里[1] 阅读更多关于 Python 生成器的内容。
• 对于大量数字/数据的处理,您可以使用像 Numpy 这样的库,它可以优雅地处理内存管理。• 使用 format 而不是 “+” 来生成字符串 —— 在Python中,str 是不可变的,所以每对连接都必须将左、右字符串复制到新的字符串中。如果连接长度为10的四个字符串,则将复制(10+10) + ((10+10)+10) + (((10+10)+10)+10) = 90 个字符,而不是 40 字符。随着字符串数量和大小的增加,事情会变得越来越糟。Java 有时将一系列的连接转换为使用StringBuilder 来优化这种情况,但是 CPython 没有。因此,建议使用 .format 或 % 语法。如果您不能在 .format 和 % 之间选择,请查看 这个有趣的 StackOverflow 问题[2] 。• 定义 Python 类时使用槽(slots)。您可以通过将类中的 slots 设置为固定的属性名称列表,来告诉 Python 不要使用动态字典,只为一组固定的属性分配空间,从而消除了为每个对象使用一个字典的开销。在 这里[3] 阅读更多关于槽的内容。•您可以通过使用内置的模块(如 resource 和 objgraph)来跟踪对象级别的内存使用情况。• 在 Python 中管理内存泄漏可能是一项艰巨的任务,但幸运的是有一些工具(如 heapy)用于调试内存泄漏。Heapy 可以与 objgraph 一起使用来观察 diff 对象的分配随时间而增长。Heapy 可以显示哪些对象占用最多的内存。Objgraph 可以帮助您找到反向引用,以明白为什么它们不能被释放。您可以在 这里[4] 阅读更多关于在Python中诊断内存泄漏的信息。
您可以在 这里[5] 阅读由 Theano 的开发人员编写的关于 Python 内存管理的细节。
实践2:Python2 还是 Python3
当开始一个新的 Python 项目,或是只学习 Python,您可能会发现自己在选择 Python2 还是Python3 上十分纠结。这是一个广泛讨论的话题,在网上有许多观点和好的解释。
一方面,Python3 有一些很棒的新特性。另一方面,您可能希望使用仅支持 Python2 的包,而Python3 不能向后兼容。这意味着在 Python3.x 的解释器上运行 Python2 的代码可能会抛出错误。
不过,编写能同时跑在 Python2 和 Python3 解释器的代码是可能的。最常见的方法是使用_future、builtins 和 six 这样的软件包来维护一个简单、干净的 Python3.x 兼容代码库,能以最小的开销同时支持Python2 和 Python3。
python-future 是 Python2 和 Python3 之间的缺失兼容层。它提供 future 和 past 的包,能够向前或向后移植 Python2 和 Python3 的特性。它还带有 futurize 和 pasteurize,定制化的 2 到 3 基础的脚本,可以帮助您轻松地将 Py2 或 Py3 代码逐模块转换为干净的支持 Python2 和 Python3 的Py3 风格的代码库。
请查看 Ed Schofield 编写的超赞的 Python 2-3 兼容代码 手抄册[6](需翻墙)。如果相比阅读,您更喜欢视频,可以在 PyCon AU 2014 上找到他的演讲,“编写 2/3 兼容的代码[7]”(需翻墙)。
实践3:写出美丽的代码
分享代码是一个有益的尝试。无论什么动机,如果人们发现您的代码难以使用或理解,那么您的良好意图可能没有达到预期。几乎每个组织都遵循开发人员必须遵循的风格指南,以保持一致性、易于调试和协作。Python 的禅就像一个迷你风格的 Python 设计指南。主流的 Python 风格指南包括:
1. PEP-8 风格指南2.Python 习语和效率3.Google Python 风格指南
这些准则讨论了如何使用:空格、逗号和大括号,对象命名指南等。尽管它们在某些情况下可能发生冲突,但它们都具有相同的目标 —— “清晰、可读和可调试的代码标准”。
坚持一个指南,或遵循自己的,但不要试图跟随与广泛接受的标准大不相同的内容。
使用静态代码分析工具
有许多可用的开源工具能够使您的代码符合标准的风格指南和编写代码的最佳实践。
Pylint 是一个 Python 工具,用于检查模块的编码标准。Pylint 可以快速轻松地查看您的代码是否捕捉到了 PEP-8 的精髓,因此对其他潜在用户是“友好的”。
它还为您提供优良的指标和统计报告,可帮助您判断代码质量。您还可以通过创建自己的 .pylintrc 文件进行自定义和使用。
Pylint 不是唯一的选择 —— 还有其他工具,如 PyChecker,PyFlakes 以及像 pep8 和 flakes8 这样的包。
我的建议是使用 coala,一个统一的静态代码分析框架,旨在通过单个框架提供语言非特定的代码分析。Coala 支持我之前提到的所有的linting工具,并且是高度可定制的。
正确地文档说明代码
这方面对您的代码库的可用性和可读性至关重要。始终建议您尽可能广泛地文档说明您的代码,以便其他开发人员更容易了解您的代码。
功能的典型内联文档应包括:
• 该功能的一行概要。•如果适用的话,提供交互示例。这些可以让新开发人员参考,以快速了解功能的使用和预期的输出。您也可以使用 doctest 模块来确保这些示例的正确性(以测试方式运行)。请参阅 doctest 文档 中的示例。•参数文档(通常一行描述参数及其在函数中的作用)•返回类型的文档(除非您的函数没有返回任何内容!)
Sphinx 是广泛使用的用于生成和管理项目文档的工具。它提供了大量方便的功能,可以减少您编写标准文档的工作量。此外,您可以将文档推送到 Read the Docs,这是最常用的托管项目文档的方式。
Hitchiker's guide to Python for documentation[8] (笔者翻译成了中文版——Python 最佳实践指南[9])包含一些有趣的信息,在文档说明代码时可能对您有用。
实践4:提高性能
多进程,而不是多线程
改进多任务代码的执行时间时,您可能希望利用 CPU 中的多核同时执行多个任务。产生几个线程并让它们并发执行可能看起来很直观,但是由于 Python 中的全局解释器锁,所有的线程都是在相同的核上轮流运行。
为了实现 Python 的实际并行化,您可能需要使用 Python 的 multiprocessing 模块。另一个解决方案可以是将任务外包给:
1.操作系统(通过多进程)2.一些调用您的 Python 代码的外部应用程序(例如 Spark 或 Hadoop)3.您的Python代码所调用的代码(例如,您可以让 Python 代码调用C函数,来执行昂贵的多线程内容)。
除了并行,还有其他方法可以提高您的性能。其中一些包括:
• 使用最新版本的 Python:这是最直接的方法,因为新的更新通常包括对已经存在功能性能方面的增强。• 尽可能使用内置函数:这也符合 DRY 原则 —— 内置函数由世界上一些最好的 Python 开发人员仔细设计和审查,所以它们通常是最好的方式。• 考虑使用 Ctypes:Ctypes 提供了一个在 Python 代码中调用 C 共享函数的接口。C 是一种更接近机器级别的语言,与 Python 中的类似实现相比,代码执行速度更快。• 使用 Cython:Cython 是一种 Python 语言的超集,允许用户调用 C 函数并具有静态类型声明,最后生成一份更简单的最终代码,可能会执行得快得多。• 使用 PyPy:PyPy 是具有 JIT(即时)编译器的另一个 Python 实现,可以使您的代码执行更快。虽然我从未尝试过 PyPy,但它也声称会减少程序的内存消耗。像 Quora 这样的公司实际上在生产环境中使用 PyPy。• 设计与数据结构:适用于各种语言。确保您正在为目标使用正确的数据结构,在正确的地方声明变量,明智地利用标识符范围,并在任何有意义的地方缓存结果等。
我可以给出的一个具体的例子是:Python 通常在访问全局变量和解析函数地址时很慢,所以将它们分配到当前作用域内的一个局部变量,然后访问它们,速度会更快。
实践5:分析您的代码
通常,分析您的代码的覆盖度、质量和性能是有帮助的。Python 附带了 cProfile 模块来帮助评估性能。它不仅给出了总运行时间,还分别对每个函数进行了计时。
然后,它会告诉您每个函数调用的时间,这样可以很容易地确定要优化的地方。以下是cProfile 的一个示例分析:
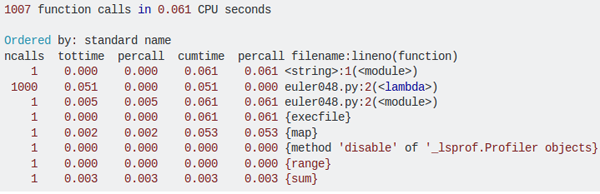
• memory_profiler 是一个用于监视进程内存消耗的Python模块,它能对 Python 程序的内存消耗进行逐行分析。•objgraph 能显示前N个占用 Python 程序内存的对象、在一段时间内删除或添加的对象以及脚本中给定对象的所有引用。•resource 为程序测量和控制系统资源使用提供了基本机制。该模块的两个主要用途包括限制资源分配和获取有关资源当前使用情况的信息。
实践6:测试和持续集成
测试
写单元测试是个好习惯。如果您认为写测试不值得您努力,请查看此 StackOverflow 问题[10]。最好在编码之前或期间编写测试。Python 提供了unittest 模块来为函数和类编写单元测试。此外还有如下框架:
• nose —— 可以运行 unittest 测试,并具有较少的样板。• pytest —— 也运行unittest测试,更少的样板,更好的报告和很多很酷,额外的功能。
为了得到良好的比较,请阅读这里[11]的介绍。
不要忘记 doctest 模块,它使用内联文档中的交互式示例来测试源代码。
测量覆盖度
Coverage 是测量 Python 程序代码覆盖度的工具。它监控您的程序,关注代码的哪些部分已被执行,然后分析源码以识别可能已被执行但没有执行的代码。
覆盖度测量通常用于测量测试的有效性。它可以显示您的代码的哪些部分被测试执行了,哪些没有。通常建议有 100% 的分支覆盖度,这意味着您的测试应该能够执行和验证项目的每个分支的输出。
持续集成
从一开始就为您的项目配置 CI 系统,对于您的项目来说可以非常有用。您可以使用 CI 服务轻松测试代码库的各个方面。CI 中的一些典型检查包括:
• 在现实环境中运行测试。有些情况下,测试在某些架构上通过,而在其他架构上失败。CI 服务可以让您在不同的系统架构上运行测试。• 对您的代码库执行覆盖度约束。•构建和部署您的代码到生产环境(您可以在不同的平台上这样做)
现今有一些 CI 服务:一些最受欢迎的有Travis、Circle(适用于OSX和Linux)和Appveyor(适用于Windows)。根据我最初的使用,像 Semaphore CI 这样的新兴产品看起来是可靠的。Gitlab(另一个Git存储库管理平台,如 Github)也支持 CI,不过如同其他服务一样,您需要明确配置它。














