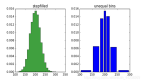
1、 jieba 分词 github地址:
https://github.com/fxsjy/jieba
“结巴”分词,可以说是 GitHub 最受欢迎的分词工具,支持自定义词典,支持多种分词模式,立志成为 Python 中最好的中文分词组件。
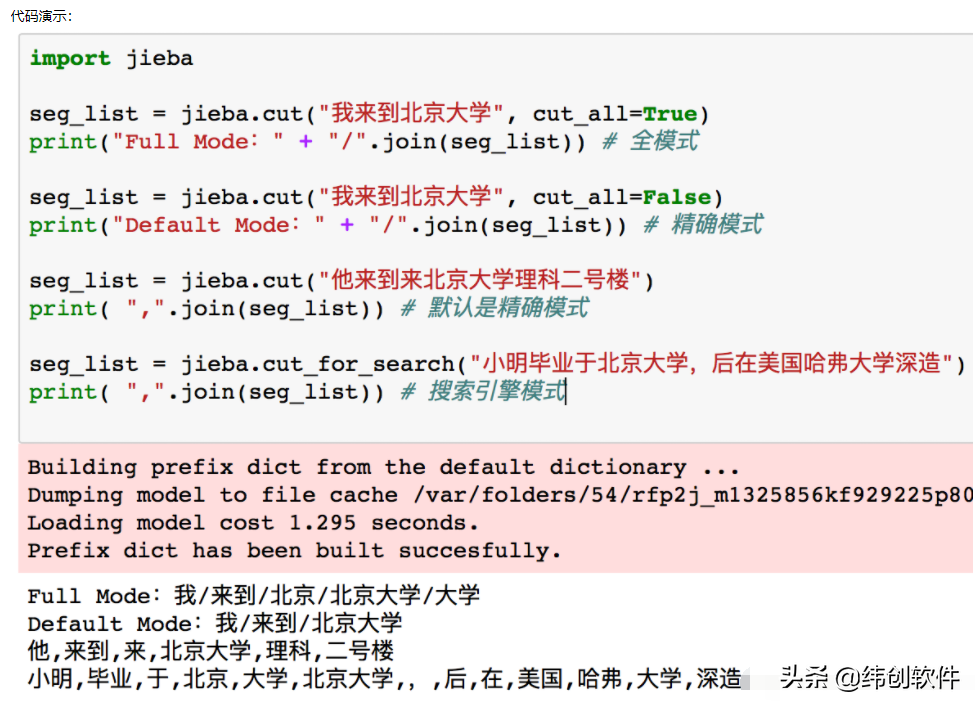
2. pkuseg 分词 github地址:
https://github.com/lancopku/pkuseg-python
pkuseg 的特点是支持多种不同的分词领域,新闻、网络、医药、v旅游等领域的分词训练模型,相比于其他分词工具,不但可以自由的选择不同模型,而且可以提供更高的分词准确率。
3. FoolNLTK 分词 github地址:
https://github.com/rockyzhengwu/FoolNLTK
FoolNLTK 分词是基于BiLSTM模型训练而来的,支持用户自定义词典,有人说它是最准确的开源中文分词,不知道你有没有尝试过呢?
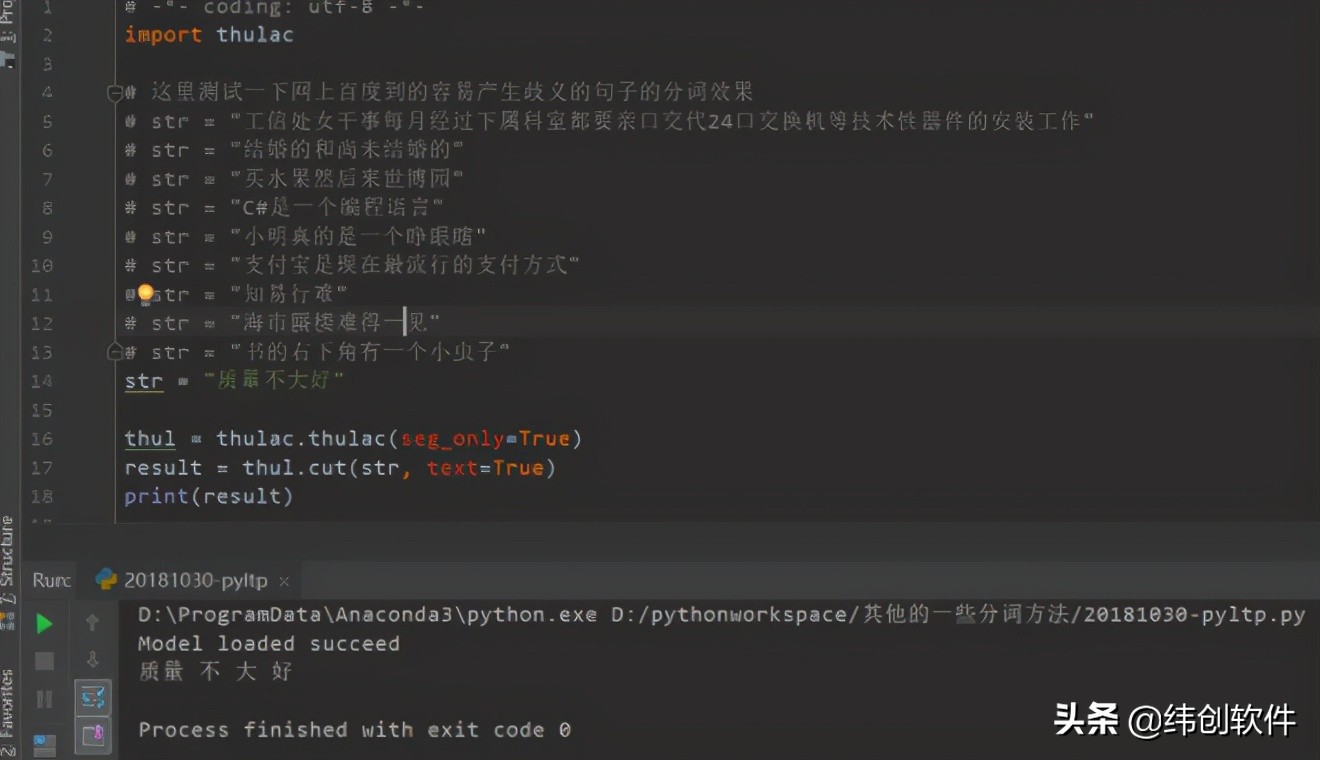
4. THULAC github地址:
https://github.com/thunlp/THULAC-Python
THULAC由清华大学自然语言处理与社会人文计算实验室,研制推出的具有词性标注功能的中文词法分析工具包。能分析出某个词是名词还是动词或者形容词。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。速度较快。
跟同事聊起分词工具,他们很多人在用的还是结巴分词,配合用户自定义词典,解决常见的网络词语。你在用哪个工具呢?