












有一些行业对误报非常敏感,如金融行业,在对信用卡欺诈检测时,如果检测系统将用户的行为错误地分类为欺诈,这将对该金融机构的声誉产生负面影响。又如在医学领域对癌症诊断时,对假阳性反应是很敏感的。另外,在使用 GPT-3 等模型时,自动和客户聊天的机器人,其回复的文本不应该包含一些不合时宜的语言。
下面我先从使用机器学习模型来推理系统入手,再展开人工干预的推理循环的技术介绍。
基于模型的推理
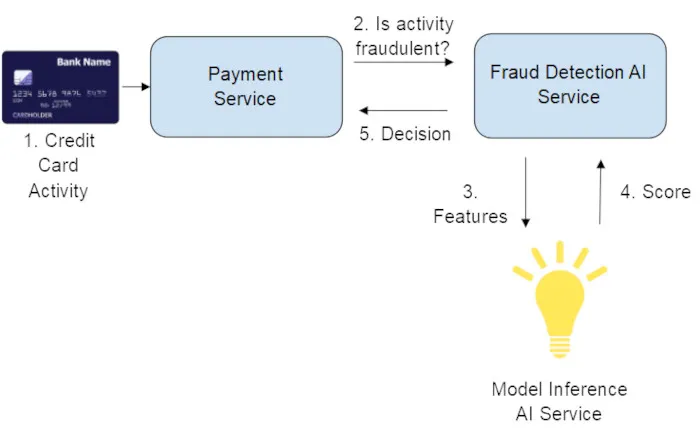
图1. 经典模型推断系统
上述为典型的信用卡欺诈用例机器学习模型,是系统和事件序列的简化视图,仅由模型负责决定给定活动是否为欺诈行为。
如何选择阈值?
阈值的大小是根据精度和召回率的要求来选择[5]。在图1的示例中,精确度定义为正确预测的欺诈活动数(真阳性样本数)除以预测为欺诈的活动总数(真阳性样本数+假阳性样本数)。召回率定义为正确预测的欺诈活动的数量(真阳性样本数)除以正确预测为欺诈的活动数量的总和,以及预测为不欺诈的实际欺诈活动的数量(真阳性样本数+假阴性样本数)。
为实现系统目标,我们需要在精度和召回率之间进行权衡。图2展示的精确率-召回率(PR)曲线是一个有效工具。
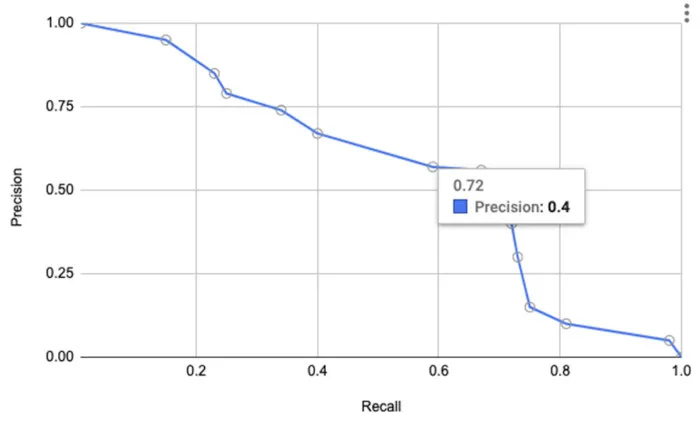
图2.精确率-召回率(PR)曲线
在较高召回率下,精度是如何降低的?当召回率为 0.72 时,精度逐渐降低到约为 0.4。为了捕获 70% 的欺诈案件,可能产生大量假阳性样本,精确率达 40%。对于这种情况,假阳性的数量是不可接受的。在合理的召回量下需要实现更高的精度,因此从图1开始,我们需要大于0.99的精度率。
尽管我们选择了更高的精度进行权衡,但在 0.99 的精度率下,召回率为 0.15,远远不够的。下面我们讨论下如何利用人工干预下,以更高的召回率实现更高的精度。
人工干预
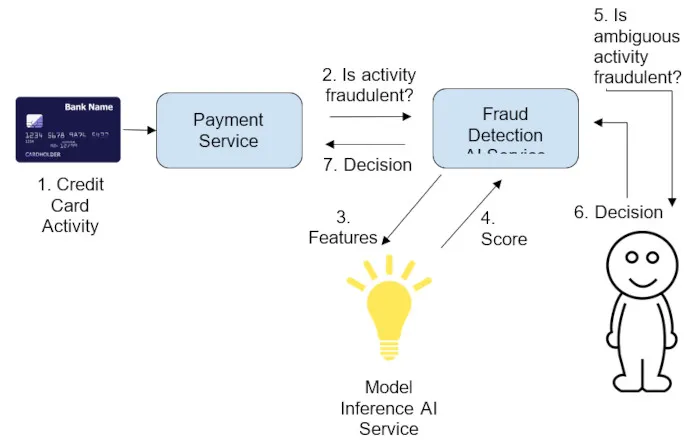
图3.通过人机交互来提高模型性能
增加召回率的一种方法是在推理循环中人工干预。如此一来,模型置信度较低的运算结果子集将被发送给人工代理进行手动检查。当选择确定有资格作为不明确的预测子集阈值时,该考虑将多少样本交给人工代理,毕竟人力资源成本往往更贵。所以为了帮助选择阈值,可以下图:
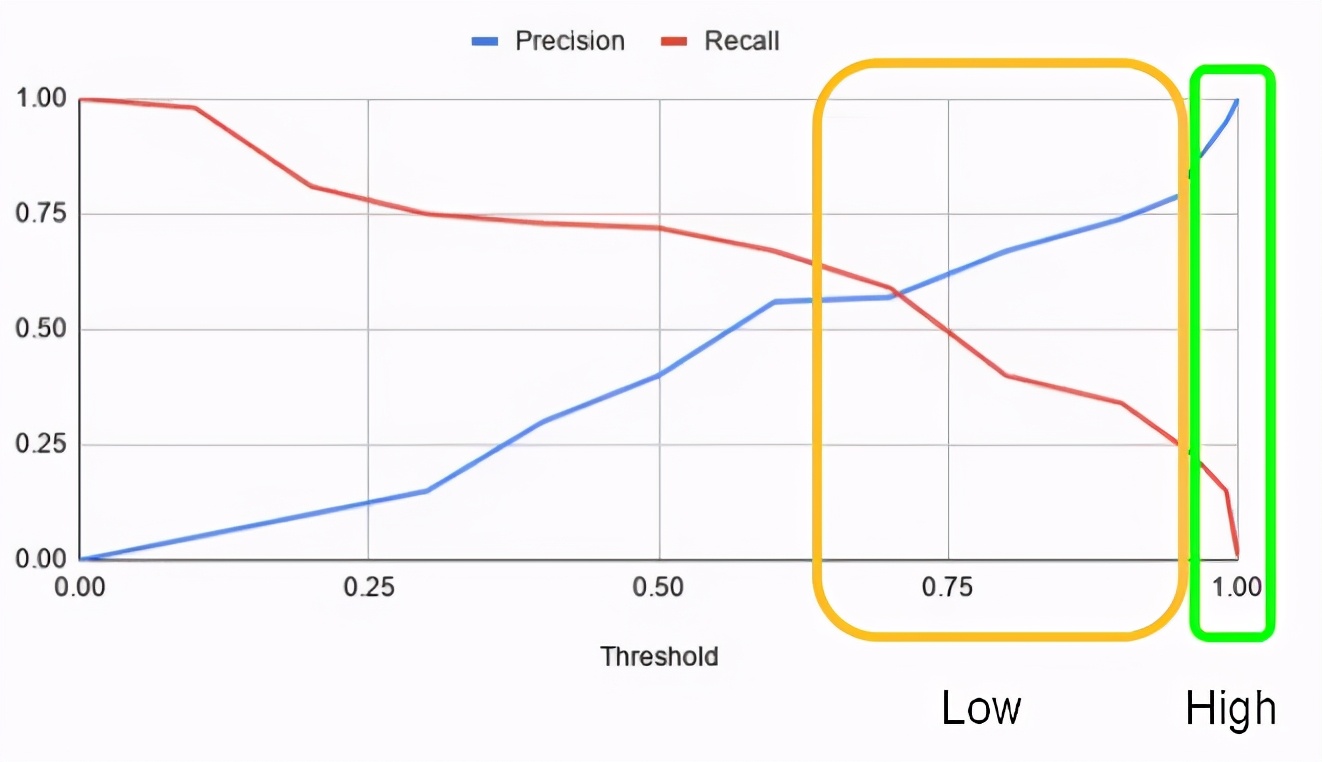
图4.精确召回阈值曲线
在上述案例里,假设分数接近 1.0 表示正标签(欺诈),分数接近0.0表示负标签(非欺诈)。图4中显示了两个区域:
- 绿色区域表示正样本标签的高置信度区域,即允许进行模型自行决策,并且所得到的模型精度是可以接受的(受影响的终端用户通常可以容忍较低的假阳率)。
- 黄色区域表示正样本标签的置信度低的区域,在该区域中,模型自动决策的精度水平是不可接受的(假阳率很高会对业务产生重大负面影响)
黄色区域是人工干预通过手动检查提高精度的区域范围。可以使用相同的方法处理负样本标签:接近0.0的区域是高置信度区域。黄色区域中的所有项目或项目子集可进行手动检查。在人工检查过程中,人工代理决定该样本识别的最终结果。关键假设是,在对歧义案件做出决策时,人为因素要优于机器学习模型。
但由于人力资源稀缺,因此在选择阈值时,发送给人工代理的请求量是重要的考虑因素。图5展示的是针对阈值绘制的数量和召回率的示例。“数量”的定义为每小时将发送给人工代理进行检查的项目数。从图5可以看出,阈值为0.7的数量为16,000个项目(每小时)。
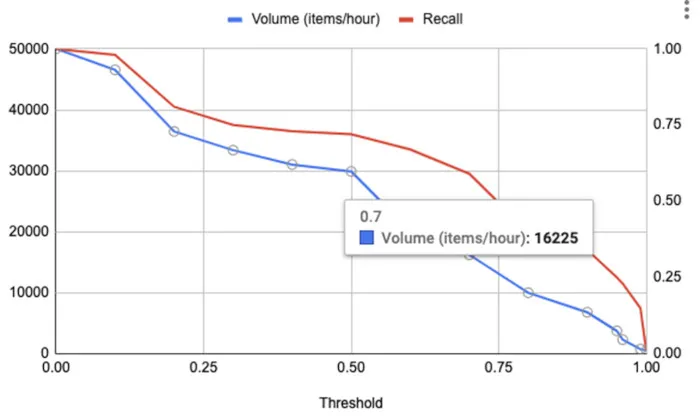
图5.容量图(每小时请求数量)和针对阈值的调用
图4和图5中的两个曲线图都可用来满足可接受的人工复查量,选择合适的阈值来满足期望召回率。让我们快速练习下,在召回率为0.59(阈值0.7)时,复查量(请参见图5)约为每小时16K个项目。在相同的召回率水平下,模型精度约为0.6(见图4)。假设人员代理池的容纳量为每小时16K件商品,并且还假设人员代理的准确性和召回率是95%,经过人工审查后,召回水平为0.59时所得到的精度将介于0.95和0.99之间。使用这设定,我们能将召回率从0.15提高到0.56(0.59 [模型] * 0.95 [人]),同时保持大于0.95的精确度。
使用人工干预的最佳做法
为了获得高质量的人工检查,为人工代理建立明确定义的培训是很重要的,人工代理将负责人工检查项目。培训计划和定期反馈循环将有助于长期保持人工检查项目的高质量,有助于最大程度地减少人为错误,维持每个项目决策的SLA要求。
另一种开销稍微大的策略是安排三个人工代理对同一项目进行审查,并从这三个代理的决策结果中进行多数表决来确定最终结果。
在微服务的实践也适用上述方法,这包括对以下内容的适当监视:
- 从系统中收到商品到对商品做出决定的时间
- 代理池的整体运行状况
- 发送给人工审查的项目数量
- 每小时的项目分类统计
由于各种原因模型精度和召回率可能会随时间变化。重要的是要通过跟踪精确/召回率来重新访问选定的阈值。
刚才我们回顾了涉及人工干预的机器学习推理系统如何在保持较高精确度的同时,帮助提高召回率。这种方法在对假阳性敏感的业务场景案例中特别有用。精确率-召回率阈值曲线是选择人工审查和自动模型决策的阈值的好工具。但是涉及人工代理会导致开发成本增加,并可能导致增加正在经历快速增长的系统的瓶颈区域。我们需要各方面评估和权衡。





















