












序列到序列(seq2seq)模型已经成为处理自然语言生成任务的有效方法,其应用范围从机器翻译到单语言生成任务,如摘要、句子融合、文本简化和机器翻译的译后编辑。
然而,对许多单语任务来说,这些模型是一个次优选择,因为所需的输出文本往往代表一个输入文本的轻微重写。在完成这些任务时,seq2seq模型速度较慢,因为它们一次生成一个输出单词(即自回归) ,而且浪费,因为大多数输入标记只是复制到输出中。
相反,文本编辑模型最近引起了极大的关注,因为它们提出预测编辑操作——如单词删除、插入或替换——这些操作应用于输入以重构输出。
以前的文本编辑方法存在局限性,要么是快速的(非自回归的) ,但是不灵活,因为它们使用的编辑操作数量有限; 要么是灵活的,支持所有可能的编辑操作,但是速度很慢(自回归的)。
在这两种情况下,它们都没有集中精力建立大型的结构(语法)转换模型,例如从主动语态切换到被动语态,从「They ate steak for dinner」(他们晚餐吃牛排)切换到「Steak was eaten for dinner」(晚餐吃牛排),相反,它们专注于局部变换,删除或替换短语。
当需要进行大型结构转换时,这些文本编辑模型要么不能生成该转换,要么会插入大量新的文本,但是这样会很慢。
在最新的论文《FELIX: 通过标签和插入进行灵活的文本编辑》(FELIX: Flexible Text Editing Through Tagging and Insertion),Google团队带来了FELIX,这是一个快速而灵活的文本编辑系统,它模拟了大的结构变化,与seq2seq方法相比,速度提高了90倍,同时在四种单语言编辑任务中的表现非常出色。

与传统的seq2seq方法相比,FELIX 有以下三个关键优势:
样本效率: 训练一个高精度的文本生成模型通常需要大量高质量的监督数据。FELIX 使用三种技术将所需的数据量最小化: (1)微调预训练检查点,(2)学习少量编辑操作的标记模型,(3)非常类似于预训练任务的文本插入任务
快速推理时间:FELIX 是完全非自回归的,避免了自回归解码器造成的慢推理时间
灵活的文本编辑: FELIX 在学习编辑操作的复杂性和它建模的转换的灵活性之间达到了平衡
简言之,FELIX旨在从自监督的预训练中获得最大利益,在资源少、训练数据少的情况下实现高效训练。
概述
为了实现上述目标,FELIX将文本编辑任务分解为两个子任务: 打标签以确定输入单词的子集及其在输出文本中的顺序,以及插入输入文本中不存在的单词。
标注模型采用了一种新颖的指针机制,支持结构转换,而插入模型则基于MLM(Masked Language Model)。这两个模型都是非自回归的,保证了模型的快速性。下面是 FELIX 的图表。
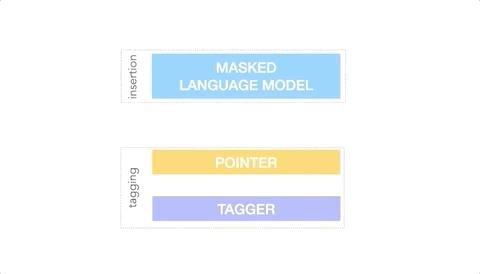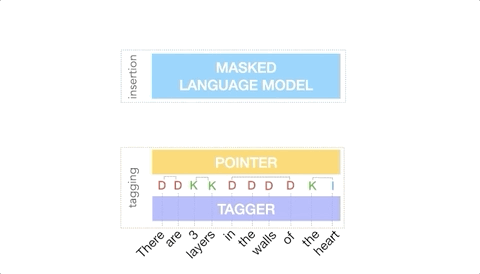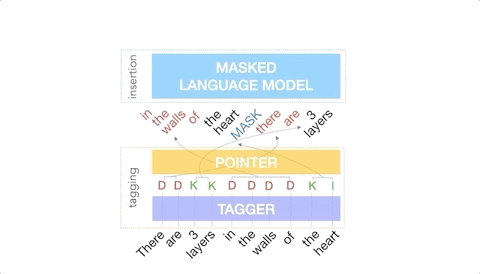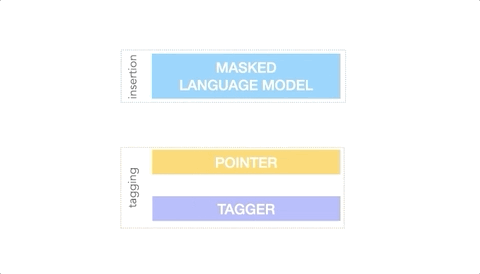
一个用于文本简化任务的FELIX数据训练示例。输入词首先标记为 KEEP (K)、 DELETE (D)或 KEEP 和 INSERT (I)。标记之后,输入被重新排序。然后将这个重新排序的输入反馈给一个MLM。
标记模型
FELIX的第一步是标记模型,它由两个组件组成。
首先,标记器确定哪些词应该保留或删除,哪些地方应该插入新词。当标记器预测插入时,将向输出中添加一个特殊的MASK标记。
在标记之后,有一个重新排序的步骤,其中指针对输入进行重新排序以形成输出,通过这个步骤,它能够重复使用输入的部分内容,而不是插入新的文本。重新排序步骤支持任意重写,从而支持对大型更改建模。
对指针网络进行训练,使得输入中的每个单词指向下一个单词,因为它将出现在输出中,如下所示。
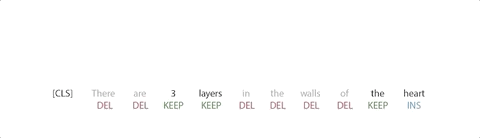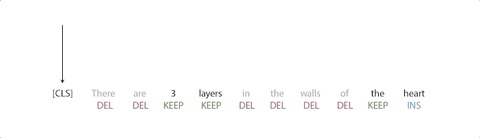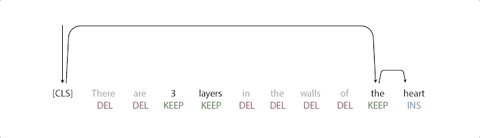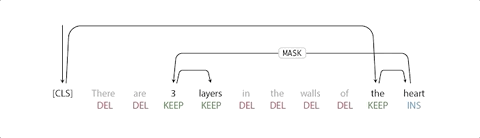
从「There are 3 layers in the walls of the heart」转化为「the heart MASK 3 layers」实现了指向机制
插入模型
标记模型的输出是重新排序的输入文本,其中包含插入标签预测的已删除的单词和MASK标记。
标记模型的输出是重新排序的输入文本,其中包含插入标签预测的已删除的单词和MASK标记。插入模型必须预测MASK标记的内容。因为FELIX的插入模型与BERT的预训练目标非常相似,所以它可以直接利用训练前的优势,这在数据有限的情况下尤其有优势。

插入模型的示例,其中标记器预测将插入两个单词,插入模型预测MASK标记的内容
结果
本文对FELIX在句子融合,文本简化,抽象摘要和机器翻译的译后编辑方面进行了评估。这些任务所需的编辑类型和操作所依据的数据集大小有着很大的差异。
在一定的数据集大小范围内,将FELIX与大型预训练的seq2seq模型(BERT2BERT)和文本编辑模型(LaserTager)进行比较,从而得到关于句子融合任务(即将两个句子合并为一个)的结果。
可以看出FELIX的性能要优于LaserTagger,并且仅需几百个样本就可以进行训练。对于完整的数据集,自回归BERT2BERT的性能要优于FELIX。但是,在推理过程中,此模型花费的时间明显更长。
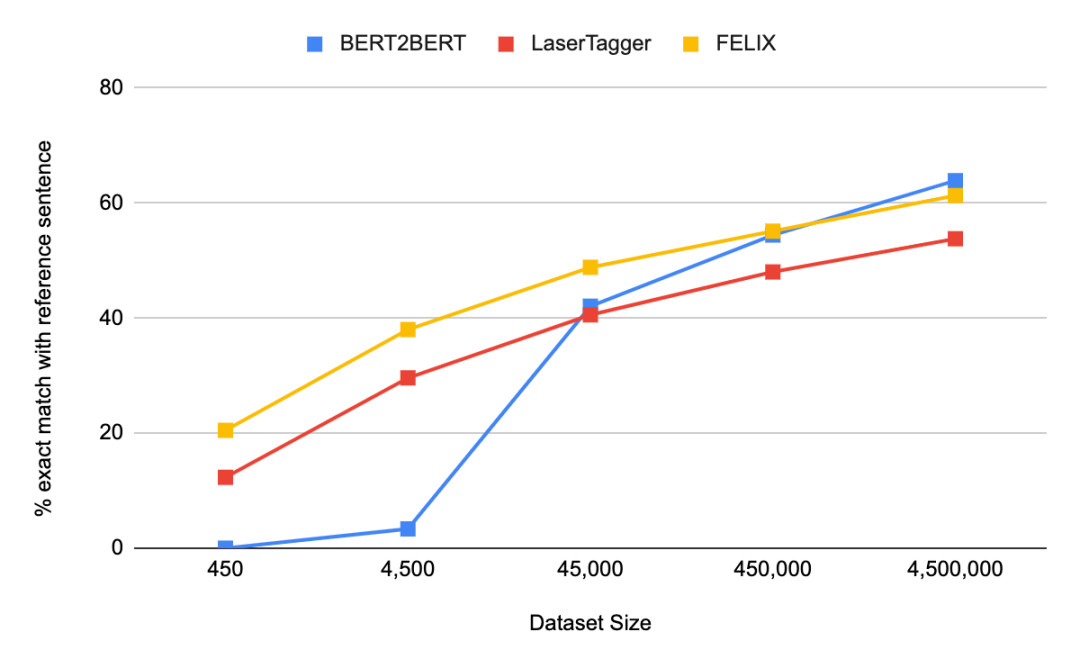
FELIX(使用性能最佳的模型),BERT2BERT和LaserTagger在使用不同大小的DiscoFuse训练数据集时的参考语句完全匹配百分比的比较。
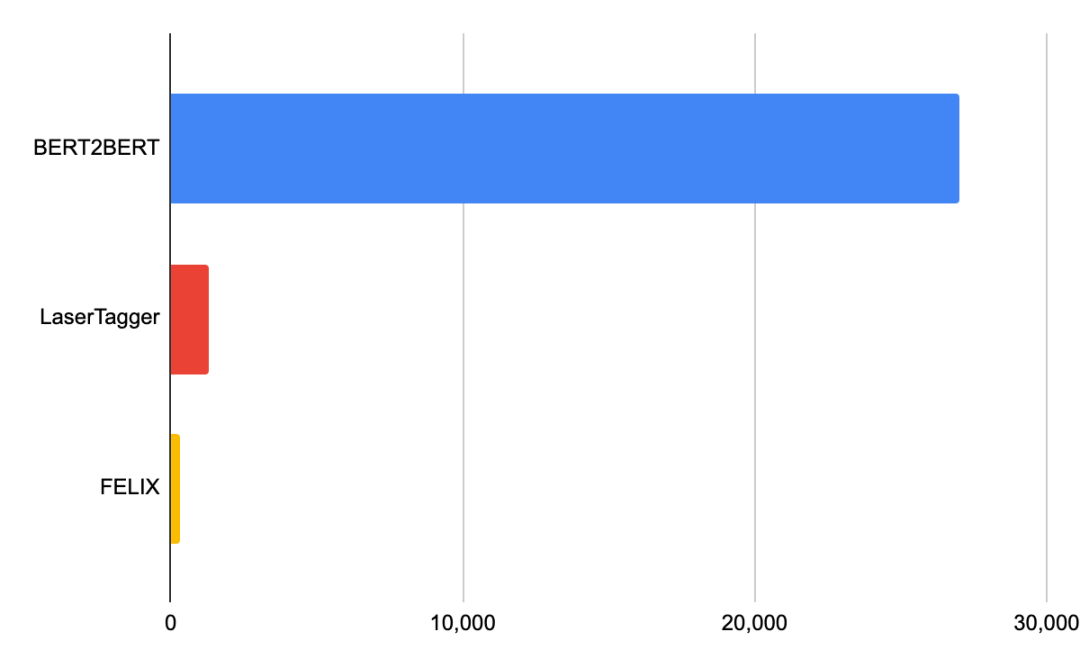
Nvidia Tesla P100上batch为32的延迟(以毫秒为单位)
结论
FELIX是完全非自回归的,在实现了顶尖水准的结果的同时提供了更快的推理时间。
FELIX还通过三种技术将所需的训练数据量降至最低:微调预训练的检查点,学习少量的编辑操作以及从预训练中模仿MLM任务的插入任务。
最后,FELIX在学习的编辑操作的复杂性和可处理的输入输出转换的百分比之间取得了平衡。

























