本文转载自微信公众号「编程杂技」,作者theanarkh。转载本文请联系编程杂技公众号。
昨天有个同学碰到发送udp包时收到destination unreachable的icmp包问题,本文简单介绍一下linux5.9中icmp包的处理流程。
发送icmp包的流程
下面以udp为例看看什么时候会发送destination unreachable包。我们从收到一个udp包开始分析,具体函数是udp_rcv。
- int udp_rcv(struct sk_buff *skb){
- return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
- }
- int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
- int proto){
- struct sock *sk;
- struct udphdr *uh;
- unsigned short ulen;
- struct rtable *rt = skb_rtable(skb);
- __be32 saddr, daddr;
- struct net *net = dev_net(skb->dev);
- bool refcounted;
- // udp头
- uh = udp_hdr(skb);
- ulen = ntohs(uh->len);
- // 源目的ip
- saddr = ip_hdr(skb)->saddr;
- daddr = ip_hdr(skb)->daddr;
- // 头部指示大小比实际数据小
- if (ulen > skb->len)
- goto short_packet;
- if (proto == IPPROTO_UDP) {
- uh = udp_hdr(skb);
- }
- sk = skb_steal_sock(skb, &refcounted);
- // 广播或多播
- if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
- return __udp4_lib_mcast_deliver(net, skb, uh,
- saddr, daddr, udptable, proto);
- // 单播,根据地址信息找到对应的socket
- sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
- // 找到则挂到socket下
- if (sk)
- return udp_unicast_rcv_skb(sk, skb, uh);
- // 找不到socket则回复一个ICMP_DEST_UNREACH icmp包
- icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
- kfree_skb(skb);
- return 0;
- }
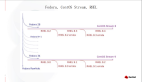
我们看到当通过ip包信息找不到对应socket的时候,就会发送一个icmp包给发送端。icmp包结构如下。

收到icmp包的处理流程
我们从收到ip包开始分析。
- int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
- struct net_device *orig_dev){
- struct net *net = dev_net(dev);
- skb = ip_rcv_core(skb, net);
- if (skb == NULL)
- return NET_RX_DROP;
- return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
- net, NULL, skb, dev, NULL,
- ip_rcv_finish);
- }
ip层收到包后会继续执行ip_rcv_finish。
- static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb){
- struct net_device *dev = skb->dev;
- int ret;
- ret = ip_rcv_finish_core(net, sk, skb, dev, NULL);
- if (ret != NET_RX_DROP)
- ret = dst_input(skb);
- return ret;
- }
接着执行dst_input
- static inline int dst_input(struct sk_buff *skb){
- return skb_dst(skb)->input(skb);
- }
input对应的是ip_local_deliver。
- int ip_local_deliver(struct sk_buff *skb){
- struct net *net = dev_net(skb->dev);
- return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
- net, NULL, skb, skb->dev, NULL,
- ip_local_deliver_finish);
- }
接着执行ip_local_deliver_finish。
- static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb){
- __skb_pull(skb, skb_network_header_len(skb));
- rcu_read_lock();
- ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol);
- rcu_read_unlock();
- return 0;
- }
ip_local_deliver_finish会执行ip_protocol_deliver_rcu进一步处理,ip_protocol_deliver_rcu的最后一个入参是ip包里的协议字段(上层协议)。
- void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol){
- const struct net_protocol *ipprot;
- int raw, ret;
- resubmit:
- // 根据协议找到对应的处理函数,这里是icmp
- ipprot = rcu_dereference(inet_protos[protocol]);
- if (ipprot) {
- ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,
- skb);
- if (ret < 0) {
- protocol = -ret;
- goto resubmit;
- }
- __IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
- }
- }
INDIRECT_CALL_2是一个宏。
- #define INDIRECT_CALL_1(f, f1, ...) \
- ({ \
- likely(f == f1) ? f1(__VA_ARGS__) : f(__VA_ARGS__); \
- })#define INDIRECT_CALL_2(f, f2, f1, ...) \
- ({ \
- likely(f == f2) ? f2(__VA_ARGS__) : \
- INDIRECT_CALL_1(f, f1, __VA_ARGS__); \
- })
因为这里的protocol是icmp协议。所以会执行icmp对应的handler。那么对应的是哪个函数呢?我们看看inet_protos是什么。
- struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly;
- int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol){
- return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
- NULL, prot) ? 0 : -1;
- }
我们看到inet_add_protocol函数是注册协议和对应处理函数的。我们再来看看哪里会调用这个函数。
- static int __init inet_init(void) {
- inet_add_protocol(&icmp_protocol, IPPROTO_ICMP);
- inet_add_protocol(&udp_protocol, IPPROTO_UDP);
- ...
- }
在内核初始化的时候会注册一系列的协议和处理函数。下面我们看看icmp的函数集。
- static const struct net_protocol icmp_protocol = {
- .handler = icmp_rcv,
- .err_handler = icmp_err,
- .no_policy = 1,
- .netns_ok = 1,
- };
我们看到handler是icmp_rcv。
- int icmp_rcv(struct sk_buff *skb){
- struct icmphdr *icmph;
- struct rtable *rt = skb_rtable(skb);
- struct net *net = dev_net(rt->dst.dev);
- bool success;
- // icmp头
- icmph = icmp_hdr(skb);
- success = icmp_pointers[icmph->type].handler(skb);
- }
icmp_rcv根据icmp包的信息做进一步处理。我看看icmp_pointers的定义。
- static const struct icmp_control icmp_pointers[NR_ICMP_TYPES + 1] = {
- ...
- [ICMP_DEST_UNREACH] = {
- .handler = icmp_unreach,
- .error = 1,
- },
- };
这里我们只关注ICMP_DEST_UNREACH的处理。
- static bool icmp_unreach(struct sk_buff *skb){
- ...
- icmp_socket_deliver(skb, info);
- }
继续看icmp_socket_deliver
- static void icmp_socket_deliver(struct sk_buff *skb, u32 info){
- const struct iphdr *iph = (const struct iphdr *) skb->data;
- const struct net_protocol *ipprot;
- int protocol = iph->protocol;
- // 根据ip头的协议字段找到对应协议处理,这里的iph是触发错误的原始ip头,不是收到icmp包的ip头,所以protocol是udp
- ipprot = rcu_dereference(inet_protos[protocol]);
- if (ipprot && ipprot->err_handler)
- ipprot->err_handler(skb, info);
- }
接着执行udp的err_handler,是udp_err
- int udp_err(struct sk_buff *skb, u32 info){
- return __udp4_lib_err(skb, info, &udp_table);}int __udp4_lib_err(struct sk_buff *skb, u32 info, struct udp_table *udptable){
- struct inet_sock *inet;
- const struct iphdr *iph = (const struct iphdr *)skb->data;
- struct udphdr *uh = (struct udphdr *)(skb->data+(iph->ihl<<2));
- const int type = icmp_hdr(skb)->type;
- const int code = icmp_hdr(skb)->code;
- bool tunnel = false;
- struct sock *sk;
- int harderr;
- int err;
- struct net *net = dev_net(skb->dev);
- // 根据报文信息找到对应socket
- sk = __udp4_lib_lookup(net, iph->daddr, uh->dest,
- iph->saddr, uh->source, skb->dev->ifindex,
- inet_sdif(skb), udptable, NULL);
- err = 0;
- harderr = 0;
- inet = inet_sk(sk);
- switch (type) {
- case ICMP_DEST_UNREACH:
- err = EHOSTUNREACH;
- if (code <= NR_ICMP_UNREACH) {
- harderr = icmp_err_convert[code].fatal;
- err = icmp_err_convert[code].errno;
- }
- break;
- ...
- }
- // 设置错误信息到socket
- sk->sk_err = err;
- sk->sk_error_report(sk);
- out:
- return 0;
- }
__udp4_lib_err设置了错误信息,然后调用sk_error_report。sk_error_report是在调用socket函数时赋值的(具体在sock_init_data函数)。
- sk->sk_error_report = sock_def_error_report;
接着看sock_def_error_report
- static void sock_def_error_report(struct sock *sk){
- struct socket_wq *wq;
- rcu_read_lock();
- wq = rcu_dereference(sk->sk_wq);
- if (skwq_has_sleeper(wq))
- wake_up_interruptible_poll(&wq->wait, EPOLLERR);
- sk_wake_async(sk, SOCK_WAKE_IO, POLL_ERR);
- rcu_read_unlock();}static inline void sk_wake_async(const struct sock *sk, int how, int band){
- if (sock_flag(sk, SOCK_FASYNC)) {
- rcu_read_lock();
- sock_wake_async(rcu_dereference(sk->sk_wq), how, band);
- rcu_read_unlock();
- }
- }
我们看到如果进程阻塞在socket则会被唤醒,或者设置了SOCK_FASYNC标记则收到信号。
后记:本文简单介绍了icmp的产生和处理过程,后面有时间再细化一下。