













一、声源定位
1、电扫阵列
当系统扫描到输出信号功率最大时所对应的波束方向就是认为是声源的DOA方向,从而可以声源定位。电扫阵列的方式存在一定的局限,仅仅适用于单一声源。若多声源在阵列方向图的同一主波束内,则无法区分
2、超分辨谱估计
如MUSIC,ESPRIT算法等,对其协方差矩阵(相关矩阵)进行特征分解,构造空间谱,关于方向的频谱,谱峰对应的方向即为声源方向。适合多个声源的情况,且声源的分辨率与阵列尺寸无关,突破了物理限制,因此成为超分辨谱方案。
3、TDOA
TDOA是先后估计声源到达不同麦克风的时延差,通过时延来计算距离差,再利用距离差和麦克风阵列的空间几何位置来确定声源的位置。分为TDOA估计和TDOA定位两步。
二、波束成形
1、CBF-传统的波束形成
CBF是最简单的非自适应波束形成,对各个麦克风的输出进行加权求和得到波束,在CBF中,各个通道的权值是固定的,作用是抑制阵列方向图的旁瓣电平,以滤除旁瓣区域的干扰和噪声。
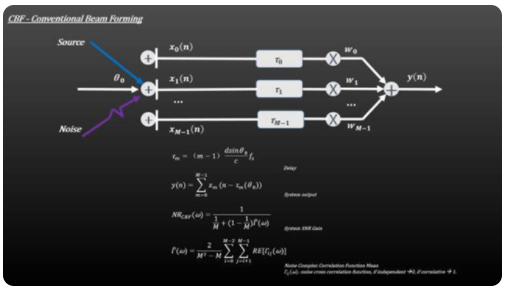
2、CBF + Adaptive Filter 增强型波束形成
CBF+Adaptive Filter结合Weiner滤波来改善语音增强的效果,带噪语音经过Weiner滤波得到基于LMS准则的纯净语音信号。而滤波器系数可以不断更新迭代,与传统的CBF相比,可以更有效的去除非稳态噪声。
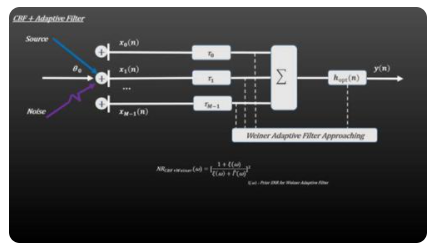
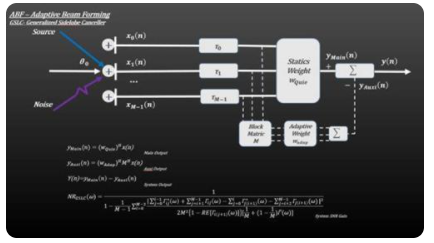
3、ABF-自适应波束形成
ABF在CBF的基础之上,对干扰和噪声进行空域自适应滤波。ABF中,采用不同的滤波器得到不同的算法,即不同通道的幅度加权值是根据某种最优准则进行调整和优化。
三、语音增强
语音增强是指当语音信号被各种各样的噪声(包括语音)干扰甚至淹没后,从含噪声的语音信号中提取出纯净语音的过程。
四、混响抑制
利用麦克风阵列去混响的主要方法有以下几种:
(1)基于盲语音增强的方法(Blind signal enhancement approach),即将混响信号作为普通的加性噪声信号,在这个上面应用语音增强算法。
(2)基于波束形成的方法(Beamforming based approach),通过将多麦克风对收集的信号进行加权相加,在目标信号的方向形成一个拾音波束,同时衰减来自其他方向的反射声。
(3)基于逆滤波的方法(An inverse filtering approach),通过麦克风阵列估计房间的房间冲击响应(Room Impulse Response, RIR),设计重构滤波器来补偿来消除混响。
五、噪声抑制
语音识别不需要完全去除噪声,相对来说通话系统中则必须完全去除噪声。这里说的噪声一般指环境噪声,比如空调噪声,这类噪声通常不具有空间指向性,能量也不是特别大,不会掩盖正常的语音,只是影响了语音的清晰度和可懂度。这种方法不适合强噪声环境下的处理,但是足以应付日常场景的语音交互。
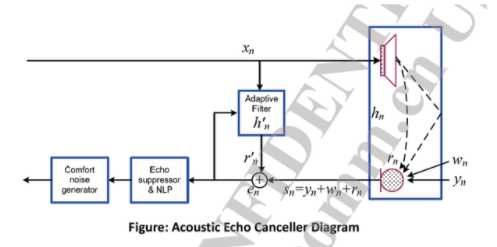
六、回声消除
回声消除就是在Mic采集到声音之后,将本地音箱播放出来的声音从Mic采集的声音数据中消除掉,使得Mic录制的声音只有本地用户说话的声音。





















