












领域泛化 (Domain Generalization, DG) 是近几年非常热门的一个研究方向。它研究的问题是从若干个具有不同数据分布的数据集(领域)中学习一个泛化能力强的模型,以便在未知(Unseen) 的测试集上取得较好的效果。
本文介绍 DG 领域的第一篇综述文章《Generalizing to Unseen Domains: A Survey on Domain Generalization》。该论文一共调研了 160 篇文献,其中直接与领域泛化相关的有 90 篇。文章从问题定义、理论分析、方法总结、数据集和应用介绍、未来研究方向等几大方面对领域泛化问题进行了详细的概括和总结。
该论文的精简版已被国际人工智能顶会IJCAI-21录用。

文章链接:
https://arxiv.org/abs/2103.03097
PDF:https://arxiv.org/pdf/2103.03097
作者单位:微软亚洲研究院、中央财经大学
问题定义
领域泛化问题与领域自适应 (Domain Adaptation,DA) 最大的不同:DA 在训练中,源域和目标域数据均能访问(无监督 DA 中则只有无标记的目标域数据);而在 DG 问题中,我们只能访问若干个用于训练的源域数据,测试数据是不能访问的。毫无疑问,DG 是比 DA 更具有挑战性和实用性的场景:毕竟我们都喜欢「一次训练、到处应用」的足够泛化的机器学习模型。
例如,在下图中,DA 问题假定训练集和测试集都可以在训练过程中被访问,而 DG 问题中则只有训练集。

DG 问题的示意图如下所示,其形式化定义如下:
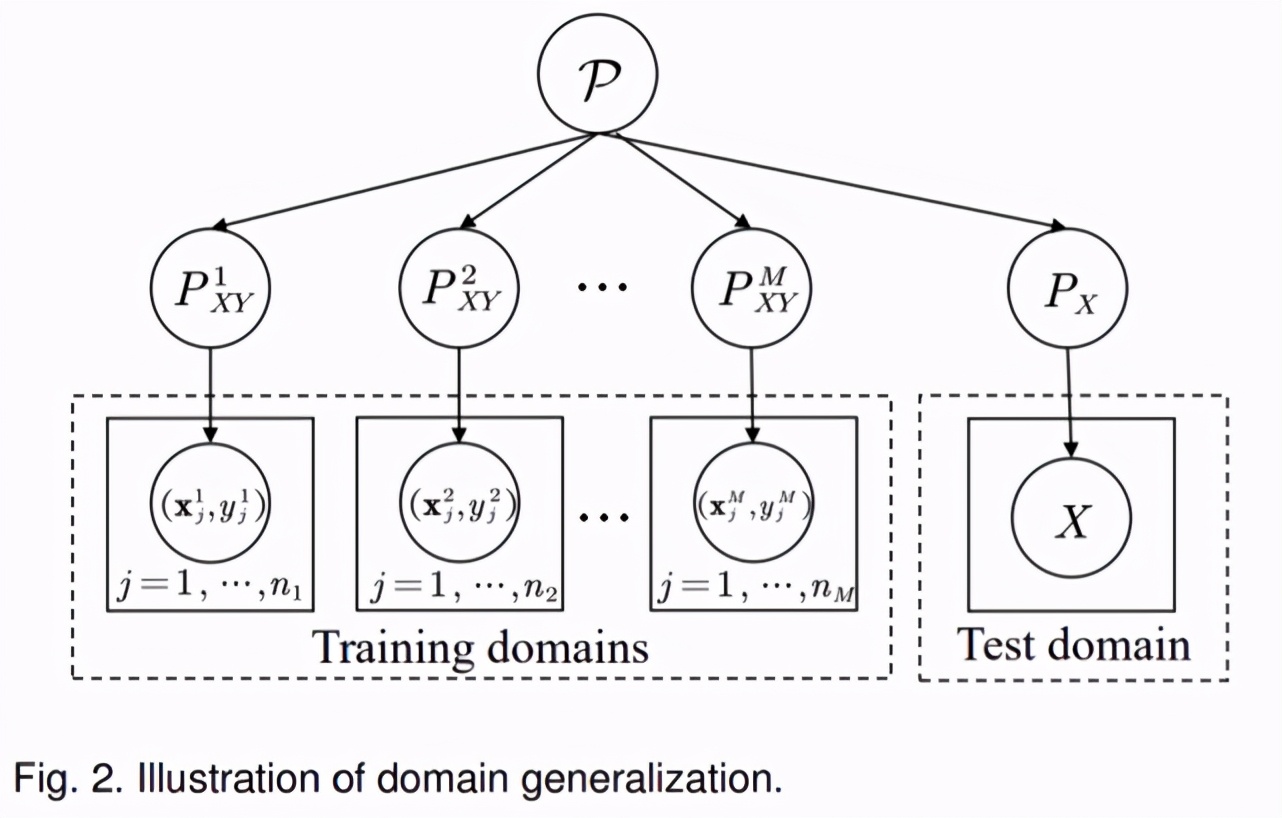

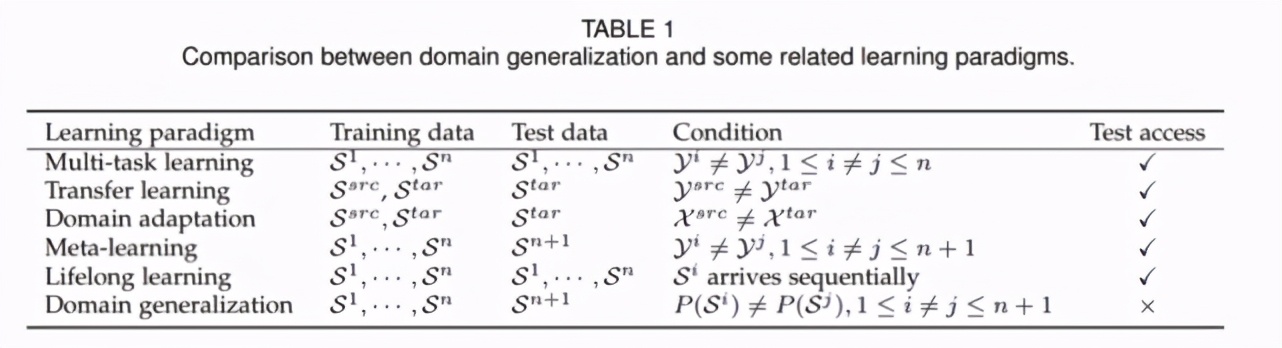
DG 不仅与 DA 问题有相似之处,其与多任务学习、迁移学习、元学习、终身学习等,都有一些类似和差异之处。我们在下表中对它们的差异进行了总结。
理论
我们从 Domain adaptation 理论出发,分析影响不同领域学习结果的因素,如 -divergence、-divergence 等,继而过渡到领域 Domain generalization 问题中,分析影响模型泛化到新领域的因素。从理论上总结了领域泛化问题的重要结果,为今后进行相关研究指明了理论方向。
详细结果请参考原文第 3 部分。
方法
领域泛化方法是我们的核心。我们将已有的领域泛化方法按照数据操作、表征学习、学习策略分为三大方面,如下图所示。
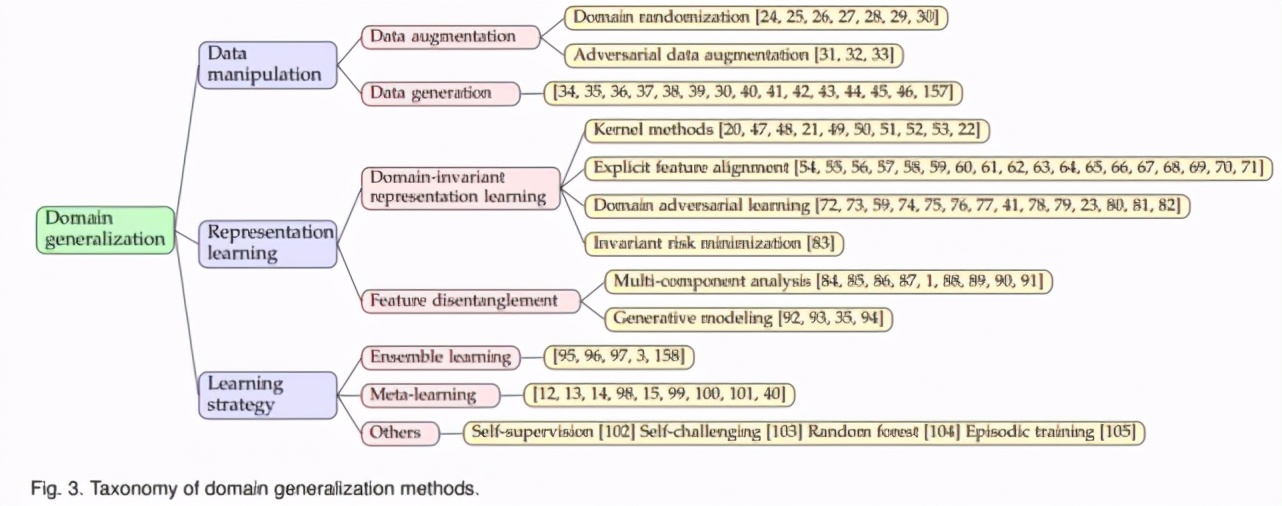
其中:
数据操作,指的是通过对数据的增强和变化使训练数据得到增强。这一类包括数据增强和数据生成两大部分。
表征学习,指的是学习领域不变特征 (Domain-invariant representation learning) 以使得模型对不同领域都能进行很好地适配。领域不变特征学习方面主要包括四大部分:核方法、显式特征对齐、领域对抗训练、以及不变风险最小化(Invariant Risk Minimiation, IRM)。特征解耦与领域不变特征学习的目标一致、但学习方法不一致,我们将其单独作为一大类进行介绍。
学习策略,指的是将机器学习中成熟的学习模式引入多领域训练中使得模型泛化性更强。这一部分主要包括基于集成学习和元学习的方法。同时,我们还会介绍其他方法,例如自监督方法在领域泛化中的应用。
在文章中,我们对每大类方法都进行了详细地介绍与总结。
应用与数据集
领域泛化问题在众多领域都得到了广泛应用。大多数已有工作偏重于设计更好的 DG 方法,因此,其往往都在图像分类数据上进行评估。除此之外,DG 方法还被应用于行人再识别(Re-ID)、语义分割、街景识别、视频理解等计算机视觉的主流任务中。
特别地,DG 方法被广泛应用于健康医疗领域,例如帕金森病识别、组织分割、X 光胸片识别、以及震颤检测等。
在自然语言处理领域,DG 被用于情感分析、语义分割、网页分类等应用。
DG 也在强化学习、自动控制、故障检测、语音检测、物理学、脑机接口等领域中得到了广泛应用。
下图展示了领域泛化问题中流行的标准数据集。

未来挑战
我们对 DG 进行以下展望:
连续领域泛化:一个系统应具有连续进行泛化和适配的能力,目前只是离线状态的一次应用。
新类别的领域泛化:目前我们假定所有的领域具有相同的类别,未来需要扩展到不同类别中、乃至新类别中。
可解释的领域泛化:尽管基于解耦的方法在可解释性上取得了进步,但是,其他大类的方法的可解释性仍然不强。未来需要对它们的可解释性进行进一步研究。
大规模预训练与领域泛化:众所周知,大规模预训练(如 BERT)已成为主流,那么在不同问题的在规模预训练中,我们如何利用 DG 方法来进一步提高这些预训练模型的泛化能力?
领域泛化的评价:尽管有工作在经验上说明已有的领域泛化方法的效果并没有大大领先于经验风险最小化,但其只是基于最简单的分类任务。我们认为 DG 需要在特定的评测,例如行人再识别中才能最大限度地发挥其作用。未来,我们需要找到更适合 DG 问题的应用场景。
























